Over the many years that I’ve worked for LINBIT®, I cannot tell you how many times I’ve been asked, “How does a LINSTOR® (or DRBD®) cluster compare to a Ceph storage cluster?” Hopefully I can help answer that question in this blog post for anyone who might Google this in the future.
My short answer could simply be, “it doesn’t”. That’s not completely fair though, so my actual answer would be, “you shouldn’t use LINSTOR where it makes sense to use Ceph and you shouldn’t use Ceph where it makes sense to use LINSTOR”. I believe the comparison is attempted as often as it is because you could use Ceph and LINSTOR interchangeably in a lot of use cases and accomplish something close to what you sought out to achieve. The finer details are what need to be considered though, not the end result.
Differences in Block Devices and Distribution of Storage
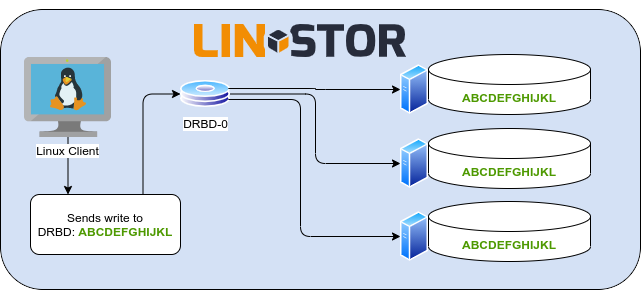
Typically, LINSTOR partitions physical storage by using LVM or ZFS, and layers DRBD on top. This results in a replicated block device. Ceph’s RADOS Block Device (RBD) creates storage objects distributed within the RADOS cluster that are then presented as a block device to clients. In both situations you end up with a block device that is tolerant to single node failures. Apples and apples, right? Not quite.
LINSTOR provisions its DRBD block device resources on LVM or ZFS partitions in a RAID-1 like manner across cluster nodes. Each node assigned with a replica of a resource has a full copy of that resource’s data. It also stores DRBD’s metadata at the end of the backing block device, behind the space available to the file system or application using the resource. This architecture means that you can remove all LINSTOR and DRBD components from all systems in the cluster and you’d still have access to your unaltered data on the backing LVM or ZFS partition. Read balancing across replicas is a feature of DRBD, but because of the RAID-1 like replication across nodes you’re typically going to have only two or three replicas for each resource, so scaling reads by adding replicas is expensive in terms of disk space. Write latency and throughput, on the other hand, are going to greatly benefit from the RAID-1 like replication because there’s no need to calculate how to stripe writes across the cluster’s nodes.
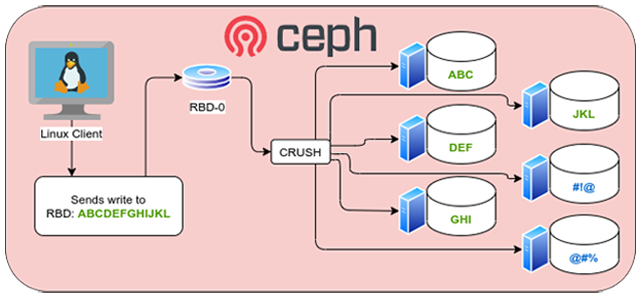
Ceph backs its block devices within RADOS objects. RADOS is the object storage system that backs all of Ceph’s storage solutions (RBD, CephFS, and RADOSGW). Ceph’s RBD stripes and replicates data across the distributed object storage using the Controlled Replication Under Scalable Hashing (CRUSH) algorithm. This uses less physical storage than LINSTOR’s RAID-1 style replication, but it also spreads your data around the cluster in a pseudo-random fashion. The CRUSH algorithm’s distribution of data makes Ceph’s block devices highly scalable, but realistically impossible to reassemble without Ceph operating normally. Scaling the Ceph cluster does increase the read and write performance by adding more RADOS objects to read from and write to, but there is computational overhead in determining where those reads and writes are happening which will have a noticeable impact on latency and throughput.
Differences in File System and Storage Access
LINSTOR’s DRBD devices can be formatted and mounted by any satellite node in the LINSTOR cluster. Ceph’s object storage can be mounted by using CephFS on any node able to authenticate to the Ceph cluster. In both cases you have a file system accessible over a network. Oranges and oranges, right? Not really.
LINSTOR’s DRBD resources are (usually) readable and writable from only one node at a time, but DRBD can automatically promote a resource “on-demand” (for example, when a DRBD-backed file system is mounted) so long as no other node is currently accessing that resource. LINSTOR’s drivers for various cloud platforms will temporarily promote more than one node to support live migrations of VMs, but this is done in a controlled manner making it safe without taking extra measures like shared file systems and cluster-wide locking mechanisms. To some, this Primary/Secondary, or Active/Passive, approach is viewed as a limitation, but this is one of the reasons LINSTOR’s DRBD devices perform as well as the physical storage used to back them. That makes DRBD a good fit for database workloads, persistent message queues, and virtual machine root disks. This also enables the user to choose which file system they’d like to format their DRBD device with, which can make a difference in application performance when you know your I/O patterns.
CephFS is Ceph’s POSIX-compliant file system that allows client systems to mount RADOS object storage just like any other Linux file system, and multiple clients can mount the same CephFS at the same time. Concurrent access to the same file system from many hosts is a must have for things like disk-image stores on hypervisors, web farms, and other large-filesized data that tends to be read more frequently than it is written. If NFS works for your use case, CephFS can most likely work there as well. CephFS implements its own locking, and cannot magically avoid the overhead that comes with this requirement for concurrence. This makes CephFS less suitable for performance demanding applications that make frequent small writes, like databases or persisted messaging queues.
In Summary
Both Ceph and LINSTOR will provide you with resilient storage, and both are fully open source. Both have operators to make deployment simple in Kubernetes, and both have upstream OpenStack drivers. Both have snapshotting and disaster recovery capabilities. So, there may be more similarities than I first led on, but how these things work “under the hood” make them very different solutions for solving different problems.
Ceph’s use of the CRUSH algorithm will distribute storage more efficiently than LINSTOR’s RAID-1 like distribution. The downside to CRUSH is a complete loss of all data when Ceph isn’t operating normally. If a LINSTOR cluster failed, DRBD-backed data can be recovered by most Linux system admins without needing to have LINSTOR specific knowledge and without needing to have LINSTOR up and running. If replication overhead is a bigger concern than the system’s complexity, consider Ceph. If the complexity of the system makes you feel uneasy about recovering from failure scenarios, consider LINSTOR.
If you require concurrent access to the same data that’s read from more frequently than it’s written to, or write latency isn’t the most important metric for your use case, consider Ceph. If you require frequent low latency writes, or flexibility in your file systems, you should consider LINSTOR (as a component of the LINBIT SDS solution).
For an idea about how LINSTOR performed when tested against Ceph, and other storage solutions in a Kubernetes environment, you can read about some benchmarking that was done by an independent tester in Comparing LINSTOR, Ceph, Mayastor, & Vitastor Storage Performance in Kubernetes.
Of course, if you need both Ceph and LINSTOR for different applications or workloads there’s nothing stopping you from using both!


