
Keeping write latency low and throughput high is fundamental in designing or implementing storage systems. With standalone servers running applications using direct attached storage, this is a relatively straightforward task that doesn’t involve much more than reviewing manufacturer spec sheets before ordering the hardware. With network attached storage, such as NAS or SAN storage, the network equipment between the client systems and storage appliance becomes a consideration, but typically these systems can be stacked and racked in a way that additional latency or impact to throughput is negligible. What might not be as straightforward is what to expect when synchronously replicating storage between storage systems distributed across a network.
At LINBIT® we get asked the question, “What is the latency threshold for DRBD®’s synchronous replication?”, a non-zero number of times each year when talking to new users and clients. We typically answer that question with, “DRBD doesn’t have a threshold per se, but network latency between replicas will become I/O latency, which the application writing to DRBD will have to tolerate.” This is because when DRBD is replicating in synchronous mode – protocol C – it will not consider a write complete until that write is committed to each peer’s disk. This ensures that data is identical on all nodes, but demands low latency networks between DRBD peers. The same is true with throughput on the replication network, but modern networks generally have a much higher throughput than storage devices, so that is usually not the bottleneck.
Clusters built on-premise have some flexibility in that an administrator can choose to physically place peers closer to each other to minimize latency. Alternatively, administrators can choose to place peers further apart to minimize the risk of localized disasters affecting the entire cluster. Hyperscalers design their data centers with an emphasis on fault tolerance and reducing the risk of localized disaster impacting customer services, but the data center as a whole remains a single point of failure. While full data center, or “availability zone” (AZ), outages are relatively rare, we do see a few every year validating the idea behind distributing cluster peers across multiple zones.
You can probably see the quandary. Having nodes close together is great for replicated write performance, but not so great if a rack catches on fire or loses power. Having your nodes far apart is great for resilience, but not so great for replicated write performance. The rest of this blog will outline the impact on write performance with various latencies and write patterns when using DRBD’s synchronous replication, which I hope is at least interesting to someone out there, if not useful.
Testing Environment
Three Amazon Web Services (AWS) Elastic Compute Cloud (EC2) instances each running in a different AZ were used to run the tests. The latency between these instances without any additional simulated latency averaged 1.3ms as measured by ping -c3 -s1400, which is pretty good for latency between geographically dispersed data centers, but 10x the latency of systems that are directly connected using TCP.
I chose to use instances running in different AZs as my baseline since this more closely mimics the “best case scenario” when someone asks the question posed at the top of this blog. Typically those users are replicating across a metro area using the public internet, which might have a round trip ping time closer to 5-8ms, but I didn’t want to alienate those fortunate enough to have dedicated fiber.
Simulating Latency and Testing Write Performance
The Linux command line utility tc was used to simulate latency. The tc command line utility is used to configure Traffic Control in the Linux kernel. It can be used to shape, schedule, police, and drop traffic based on various different user defined classes and filters.
For example, to add and remove a delay of 20ms to all traffic on a device named eth2 using tc, use the following commands:
tc qdisc add dev eth2 root netem delay 20ms # simulate 20ms of latency on a network device
tc qdisc del dev eth2 root netem # remove the simulated latency from the device
💡 TIP: Check the
tcman page and the Linux documentation project for more detailed information and examples of howtccan be used.
The Linux command line utility fio was used to simulate IO. The fio command line utility is a Flexible I/O tester commonly used to simulate specific IO workloads and generate reports for each test it runs.
For example, to generate a detailed JSON formatted I/O report for a single threaded random write workload with a queue depth of eight I/Os and a block size of 4K using fio, use the following command:
fio --name=io-test \
--filename=/dev/drbd0 \
--ioengine=libaio \
--direct=1 \
--invalidate=1 \
--rw=randwrite \
--bs=4k \
--runtime=60s \
--numjobs=1 \
--iodepth=8 \
--group_reporting \
--time_based \
--significant_figures=6 \
--output-format=json+
💡 TIP: Check the
fiodocumentation for detailed information about its options and use.
Using tc, fio, and some Python, all possible combinations of the following settings were tested:
latencies = ["0ms", "2ms", "5ms", "10ms", "20ms"]
io_depths = ["1", "8", "16", "32"]
block_sizes = ["4k", "16k", "32k", "64k", "128k", "1M"]
io_patterns = ["randwrite", "write"]
Results and Expectations
The results are not surprising, but they do provide some reference for what to expect under different circumstances. The full set of results can be viewed in this spreadsheet. For almost all block sizes, when latency on the replication network increases, overall write performance decreases. An exception being for block sizes above 64k, where we’re likely bottlenecked by the amount of data we can place into the kernels TCP send buffers.
Since the default block size for most Linux filesystems is 4k, and that’s what the majority of users will use to store data on block devices, we can inspect these results. With a high queue depth, or I/O depth, the backing Elastic Block Storage (EBS) volume which has a performance cap of 3000 IOPS was fully saturated. We can see that the average cumulative latency (clat) of each test closely reflects the latency added using tc.
| I/O Pattern | Block Size | I/O Depth | Added Latency | IOPS | Avg. Clat (ns) |
|---|---|---|---|---|---|
| randwrite | 4k | 32 | 0ms | 3015 | 10591907 |
| randwrite | 4k | 32 | 2ms | 2716 | 11762213 |
| randwrite | 4k | 32 | 5ms | 2569 | 12435262 |
| randwrite | 4k | 32 | 10ms | 1953 | 16355842 |
| randwrite | 4k | 32 | 20ms | 1226 | 26060108 |
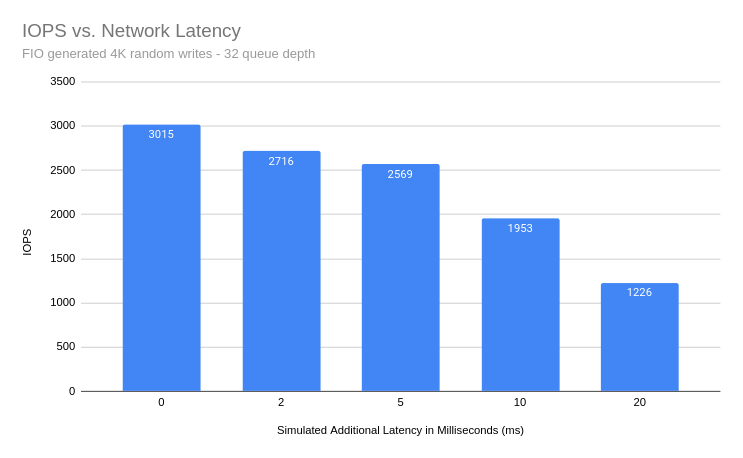
📝 NOTE: The “Simulated Additional Latencies” are in addition to the base latency of 1.3ms.
With 20ms of additional latency on the replication link, we’re only able to achieve 41% of the IOPS as we could with minimal latency between the DRBD peers. DRBD will not complain about this latency, but your application or users might. Knowing the I/O pattern of the applications you’re replicating with DRBD, as well as the latency between DRBD peers, you should be able to find the “ball park” performance expectations in the full results.
Final Thoughts
You might be thinking, “Well, that was anticlimactic,” and I don’t disagree. The idea that latency has a negative impact on performance isn’t some ground breaking discovery, after all. However, I do hope that posting some reference for the impact latency has on performance will help someone out there set appropriate expectations.
That said, if you’re in a situation where you have high latency between DRBD peers and cannot move them closer to one another physically, all is not lost. DRBD has other modes of replication including an asynchronous protocol – protocol A – that can help with high latency replication networks. When using DRBD’s protocol A, writes are considered complete once they’re placed into the TCP send buffer of the DRBD Primary node. However, asynchronous replication traffic caused by a spike in writes can quickly fill the kernel’s TCP send buffer causing IO to block while DRBD waits for the TCP buffer to flush, and we’re back to square one.
DRBD Proxy to the rescue! DRBD Proxy can take system memory and use that as an additional buffer for DRBD’s replicated writes. This means you have a configurable amount of buffer space to fill before writes would start blocking. DRBD Proxy also maintains multiple TCP streams to send important DRBD specific information between peers with priority, which can further mitigate write blocking during spikes of I/O or congestion on the replication network. For more information on DRBD Proxy and how you can use it in long distance DRBD replicated clusters, reach out to us LINBIT to learn more or trial DRBD Proxy in your own environment.


