
LINBIT® has been growing its catalog of open source storage and high-availability (HA) clustering software for many years with various drivers, plugins, and platforms all with DRBD® at their core. I often refer to DRBD as a “Swiss army knife of replication” because DRBD doesn’t care what application is writing to it or what those writes look like, its simply going to replicate that write.
This makes DRBD extremely flexible. That flexibility allows for a wide range of implementations and use cases. Often times, there will be more than one way to use LINBIT’s software to solve a single problem. How LINBIT’s software can be used to provide storage to Kubernetes environments is one of those situations.
Each of the various software configurations come with its own set of pros and cons, its own deployment method, and also its own industry buzzword. This blog post will cover three different configurations of LINBIT software and how they can be used to provide persistent storage to Kubernetes.
LINSTOR Operator – Hyperconverged Infrastructure (HCI)
The most commonly deployed LINBIT software configuration for Kubernetes is the LINSTOR® Operator in a hyperconverged architecture. Hyperconverged architecture is a software-defined infrastructure that combines compute, storage, networking, and virtualization resources into a single appliance or cluster. This means that the LINSTOR cluster itself is running within Kubernetes, and that LINSTOR is consuming physical storage attached to the cluster nodes, which it then can replicate to other nodes in the cluster, and attach directly to your Kubernetes pods.
The following diagram illustrates LINBIT software being used in a hyperconverged configuration. Here, LINSTOR is operating inside of Kubernetes as sets of pods and is attaching DRBD-replicated storage from the Kubernetes nodes to an application.
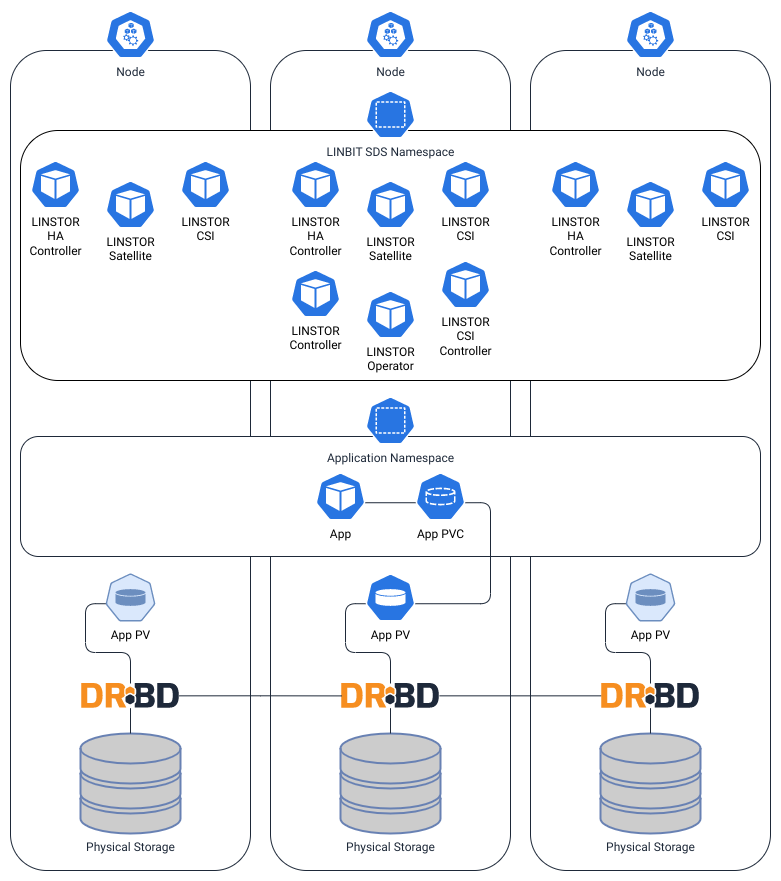
This approach also offers the highest level of performance, because the application and the storage it’s writing to can be created on the same node. This keeps read and write latencies as low as possible, making it a great fit for databases and other I/O intensive applications. Because LINSTOR is attaching block devices to the Kubernetes pods, this configuration is limited to a “ReadWriteOnce” (RWO) volume access mode on its persistent volumes.
This approach streamlines management, reduces costs, and improves scalability for data center environments. For these reasons, the majority of LINBIT’s documentation for LINSTOR’s integration into Kubernetes assumes this is how LINSTOR will be deployed.
Another advantage to this approach is a lower operational overhead. Assuming your operations team is familiar with Kubernetes, managing LINSTOR’s lifecycle using Kubernetes, along with the LINSTOR Operator managing the LINSTOR cluster itself, this configuration will have the lowest learning curve of all the approaches mentioned in this blog.
LINSTOR Operator – Disaggregated
Some users prefer to keep their compute and storage nodes separate, attaching applications to their storage over a network fabric. This is what the industry refers to as a disaggregated architecture. This approach allows data center operators to tailor their systems to specific workloads, improving resource utilization and allowing for asymmetric scaling of compute and storage.
In a disaggregated configuration, a LINSTOR cluster runs outside of Kubernetes, with only LINSTOR’s CSI and satellite pods running inside of the Kubernetes cluster. The LINSTOR pods running in the cluster are there to support the Diskless attachment of DRBD devices to their applications, as well as managing node affinities and “higher availability” for stateful applications using LINSTOR’s HA controller for Kubernetes. The external LINSTOR cluster’s satellite nodes contain all of the cluster’s storage that comprises LINSTOR’s storage pools.
The following diagram illustrates LINBIT software being used in a disaggregated configuration. Here, some LINSTOR components are running inside of Kubernetes to support attaching DRBD-replicated storage from the external LINSTOR cluster which contains the physical storage to an application running within Kubernetes.
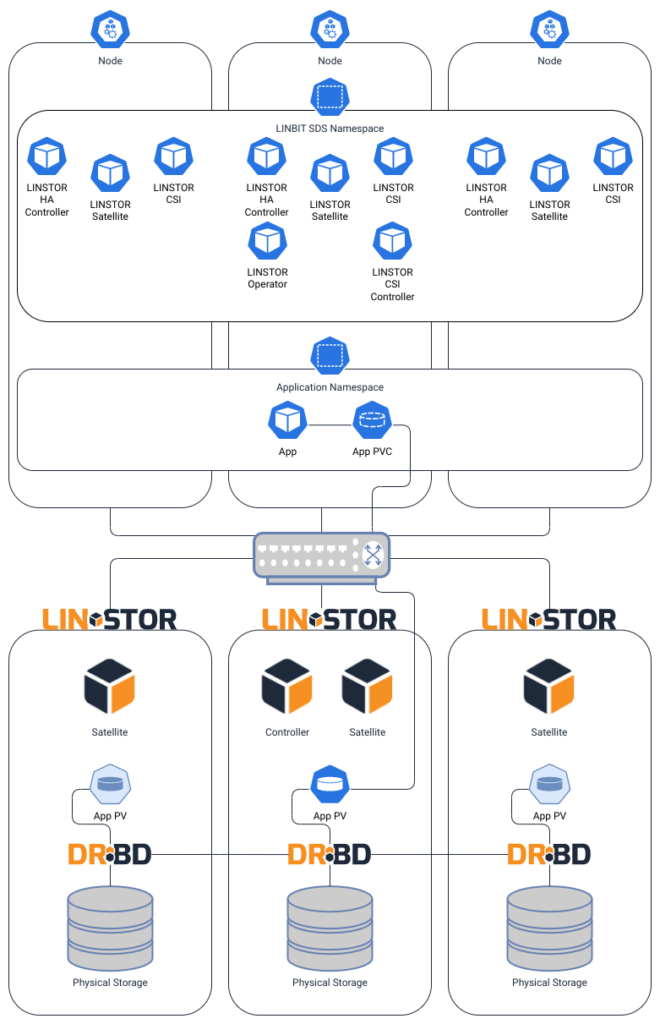
This might be the most flexible of the two LINSTOR CSI driver options, but has a larger operational overhead and steeper learning curve with the “manual” deployment and management of the external LINSTOR cluster. The disaggregated cluster’s performance will be comparable to HCI, with only a bit of additional latency added by the fabric connecting Kubernetes to your LINSTOR Cluster.
As with the HCI approach, the disaggregated approach is also attaching block devices to the Kubernetes pods, therefore limiting the persistent volumes to the RWO volume access mode.
DRBD Reactor HA NFS – NAS
LINBIT has a long history of building and supporting traditional Linux HA clusters. In recent years, LINBIT has added DRBD Reactor to its software catalog, further simplifying LINBIT’s HA stack. One of LINBIT’s most deployed Linux HA clusters is the HA NFS stack.
NFS is a mature, widely supported, and well understood technology for system and storage administrators. Kubernetes has native support for NFS as persistent volumes for its pods, and because NFS is already designed for concurrent access, NFS backed persistent volumes can be accessed using the “ReadWriteMany” (RWX) volume access mode. This makes NFS an attractive solution for teams that require RWX support for their application, or teams that are simply more comfortable managing NFS.
Using DRBD and DRBD Reactor to build an HA NFS for use in Kubernetes environments completely separates the Kubernetes cluster from the storage cluster. There are no LINBIT specific software deployed into the Kubernetes cluster, and nothing Kubernetes specific deployed into the NFS cluster.
The following diagram illustrates LINBIT software being used as network attached storage (NAS). Here, there is no intermingling of LINBIT software between the Kubernetes hosts and the hosts comprising the NAS. DRBD-replicated storage from the HA NAS configuration is attached using the NFS protocols and Kubernetes’ built-in NFS support
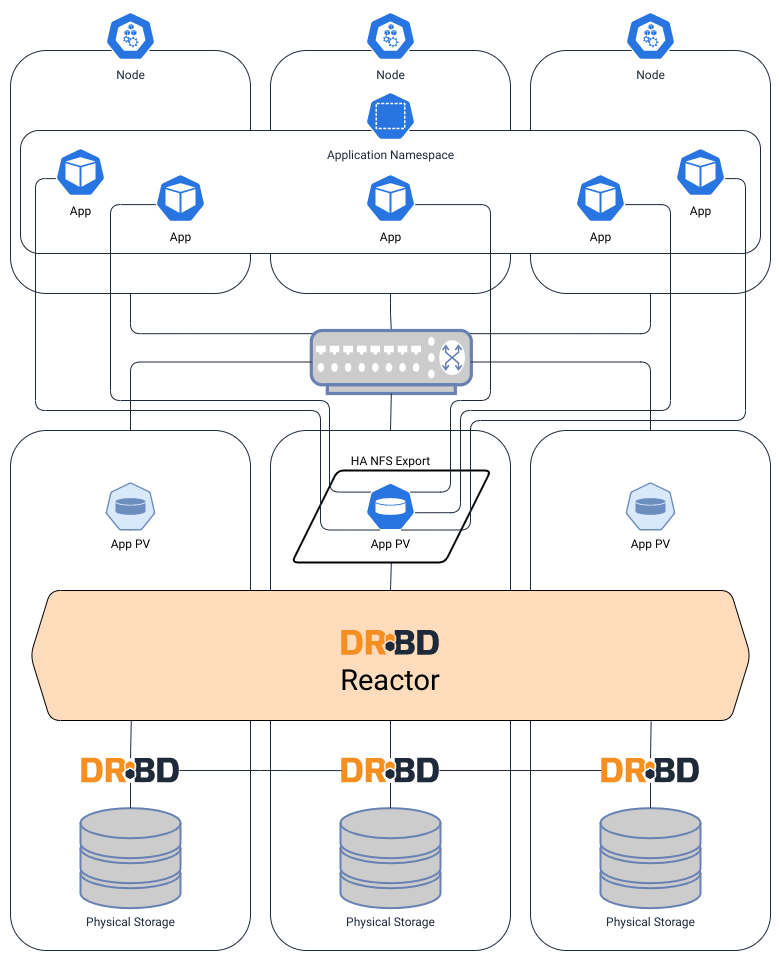
Operating at the file level using the relatively “chatty” NFS client-server protocol will have the lowest performance in terms of IOPS and throughput among the configurations listed in this blog. Concurrent access to the same persistent storage from multiple pods, or the simplicity in managing NFS completely separate from Kubernetes, will likely be the factors that attract users to this configuration.
Final Thoughts
As I’ve hopefully demonstrated in this blog, there is more than one way to skin the proverbial cat when you’re looking at LINBIT’s software and how Kubernetes can use it. Which configuration you chose will likely come down to some combination of performance requirements, volume access mode requirements, or a familiarity or comfort level with one of the architectures over the others. LINBIT is a big believer in openness, not only in our project’s source code, but also in how we support our clients’ and community’s choices in how they want to use LINBIT software in their projects.
If you’re using LINBIT’s software in a configuration I’ve not mentioned, please don’t hesitate to join LINBIT’s community and let us know directly.


