
My previous blog post described Virter, a tool for running virtual machines (VMs). This post will show how we use that to test our software at LINBIT®. Here we focus on our end-to-end tests.
In tandem with Virter, we have another tool called vmshed. Think of it as a shed where VMs are kept. Or as a s(c)heduler for VMs if you prefer.
The job of vmshed is to decide which tests to run when, execute them and collect the results. It utilizes Virter to:
- Prepare images containing the software under test using
virter image build. These are based on various distributions and use various kernels. - Start clusters of VMs using
virter vm run. - Run the test with
virter vm exec. For most of our projects, the test suite itself is started in a Docker container.
The tests that we run require a deal of flexibility. They require varying numbers of VMs, each test may be run in a number of variants, and there are multiple base distributions, not all of which are compatible with all test variants. These features are provided by vmshed.
DRBD® runs on a wide variety of kernels thanks to the kernel compatibility patching system. By testing with different distributions we are able to validate the automatically patched versions.
Continuous integration tests
At LINBIT we use GitLab for continuous integration (CI). We host our internal repositories there and review changes to the code. The CI pipelines start vmshed on runners which are specially prepared as libvirt hypervisors. Thus we ensure that every change passes a set of core end-to-end tests before being merged.
Stability tests
In addition to the CI tests which are run for every change, the DRBD tests are run many times every night. There are various reasons for this:
- Catching instability. A change may pass the test suite once but still make the software unstable for some use-case. Running the tests repeatedly catches many such issues so that they can be fixed early.
- Ensuring reliability of the CI tests. Similar to the first point, changes to the tests or the software under test may make the CI tests unreliable. This leads to developers ignoring the results of these tests. We want to catch such issues as early as possible so that the CI tests remain trustworthy.
- Tracking success rates of legacy and new tests. Legacy tests and newly written tests are not always reliable enough to be added to the CI test suite. However, they still cover particular corner cases. By tracking the success rates of these tests, we can gain valuable insights while we work to make these tests fully reliable.
Running 65 tests 50 times each generates a large set of results which can be hard to interpret. To solve this, we push the results into an Elasticsearch instance and visualize them with Kibana.
For example, here is an excerpt from our test results for a week in November:
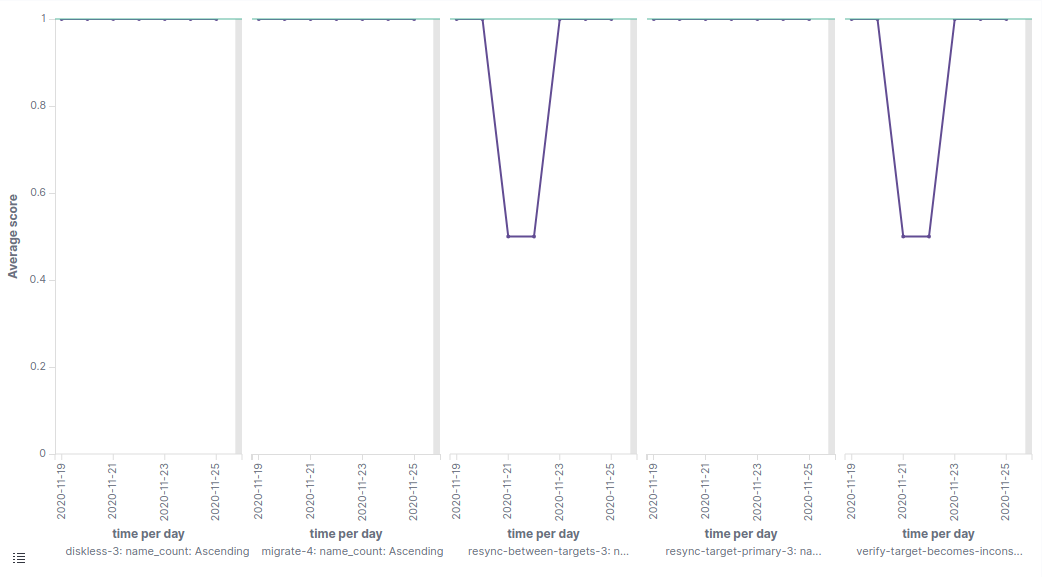
This shows the success rate of several tests on different days. Two of the tests become highly unreliable at one point. As soon as we noticed this, we were able to identify and revert the offending change. After that the tests became reliable again.
Here is another example. This shows a comparison between the main drbd-9 branch and an experimental version. Only a few tests are shown for clarity.
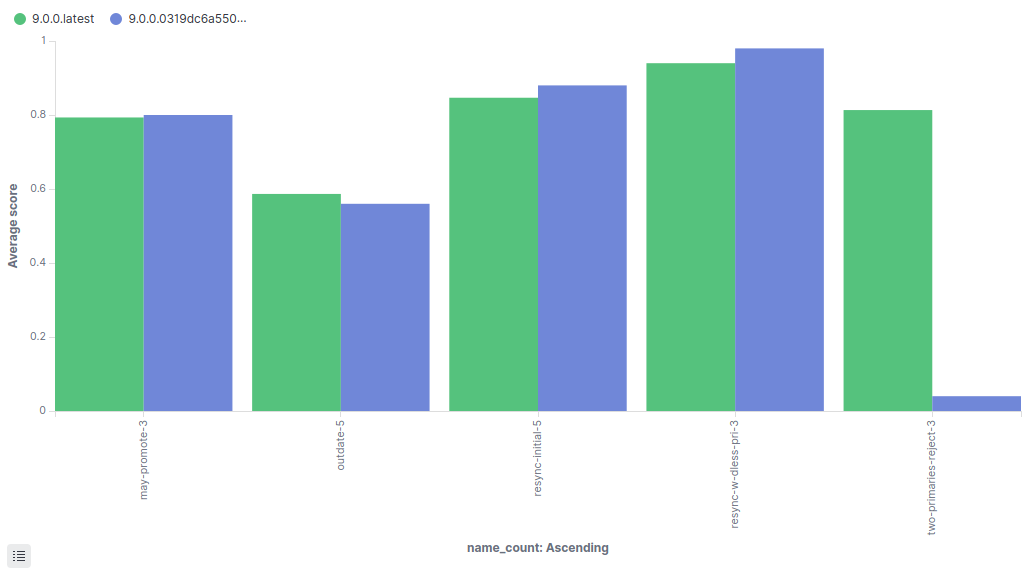
These are not part of the CI test suite, because they are not yet reliable enough. Nonetheless the change in success rate for the test “two-primaries-reject” is significant enough to warrant further investigation, and in this case it revealed a genuine issue with the experimental version.


