
This is a guest post by Davide Obbi, Storage Specialist at E4.
In 2024, the Italy-based E4 Computer Engineering company evaluated DRBD® for use in their high performance computing (HPC) ecosystem. E4 is a company that since 2002, has specialized in building HPC systems for academic and institutional research environments, such as CERN. More recently, the company is applying its expertise and experience to the emerging HPC markets in artificial intelligence (AI), aerospace and defense, and data science. E4 prides itself on providing “mature and reliable solutions in sophisticated technological environments” which could be why researchers at E4 chose to evaluate DRBD, the Linux kernel module that has been helping people create high availability (HA) storage clusters for more than two decades.
Similar to their approach to building sophisticated HPC systems, E4 took a sophisticated and detail-oriented approach to their performance testing of DRBD. In their conclusion, DRBD was easy to implement and to make configuration changes, such as implementing a CPU mask, to gain some performance benefits. Furthermore, their results showed that DRBD had very little impact on CPU use, which bodes well for using DRBD in a hyperconverged HPC environment.
Davide Obbi, Storage Specialist at E4, conducted the performance testing in the E4 lab environment. Testing procedures, observations, and results follow, in Davide’s own words, with only some minor copy editing from LINBIT® to improve clarity.
LINBIT DRBD Performance Evaluation on NVMe Drives
Scope
Evaluate the performances of LINBIT HA DRBD replication mechanism on the HW nodes available in the lab.
Setup
|
Server Model |
SYS-2029BT-HNTR |
|---|---|
|
FW and BIOS |
|
|
CPU |
2x Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz 16 cores (HT enabled) |
|
Drives |
|
|
OS and Kernel |
RHEL8.9 and 4.18.0-513.11.1.el8_9.x86_64 |
|
LINBIT DRBD |
9.2.7 |
|
Adapter |
MT27800 Family [ConnectX-5] 2x ports 100Gb/s Eth: direct attach |
|
MOFED and fw |
MOFED: 16.35.3502 and 23.10-1.1.9.0 |
|
Fio version |
3.19 |
Data Collection
Performance test results are recorded as absolute values by Fio output and over time by using Fio plotting plus Prometheus Node Exporter.
Test Preparation
Initialize the drives on each node:
blkdiscard /dev/nvme0n1
blkdiscard /dev/nvme1n1
blkdiscard /dev/nvme2n1Precondition the drives on each node:
[global]
description=Precondition all NVME
ioengine=libaio
direct=1
readwrite=write
bs=1M
numjobs=1
iodepth=32
group_reporting=0
size=100%
[nvme0n1_precondition]
filename=/dev/nvme0n1
[nvme1n1_precondition]
filename=/dev/nvme1n1
[nvme2n1_precondition]
filename=/dev/nvme2n1Testing with KCD6 drives
Fio Job File
[global]
description=KCD61VUL3T20
ioengine=libaio
time_based=1
startdelay=60
ramp_time=60
runtime=300
direct=1
NVMe Drive Test Results
Absolute results:
| sequential reads 1M bs GiB/s | ~3.2 |
| random reads 4K IOPS | ~780K |
| sequential writes 1M bs GiB/s | ~2.3 |
| random writes 4K IOPS | ~300K (170K by vendor) |
Over time sequential and random reads results are displayed in sequence below:
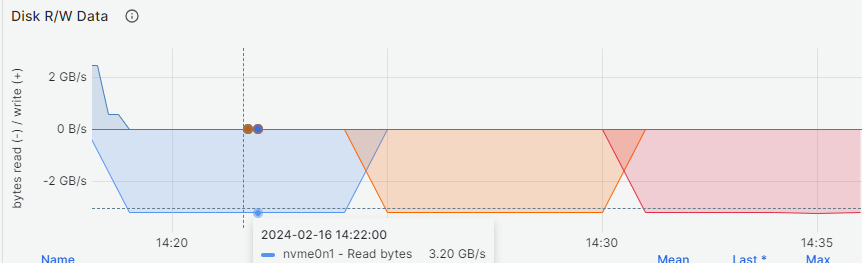
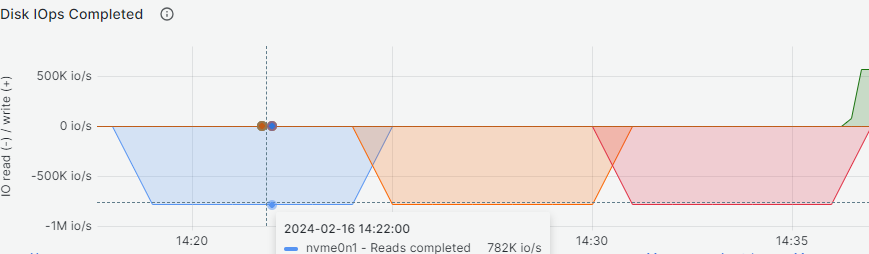
All NVMe drives experienced a performance drop during execution of the random writes test caused by the write amplification factor (WAF) of the drives. It is difficult to see it with the bare eye, but there are 32 colored lines in the graph below, each representing an I/O job for a total of around 300K IOPS per device after the drop point. Because KIOXIA advertises the drive to be capable of 170K IOPS with random write workloads we expect the value to drop more with further utilization:
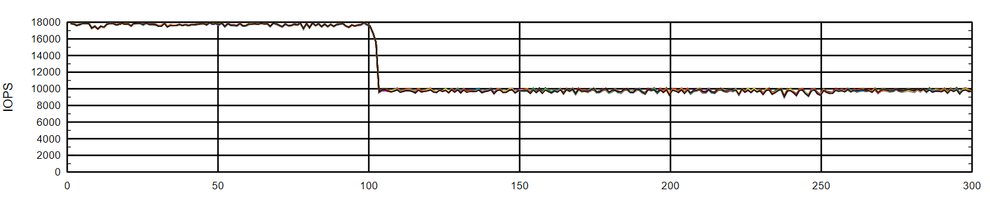
Interestingly the same happens with sequential writes, where the aggregated bandwidth is reduced by half; if we had to repeat the tests, the same behavior is experienced:
DRBD config
The test run on the /dev/drbd* devices present on the “primary“ node after the drbdadm status command reported all the resources up-to-date. Configuration for the DRBD resource:
# cat /etc/drbd.d/r0.res
resource "r0" {
volume 0 {
device minor 1;
disk "/dev/nvme0n1";
meta-disk internal;
}
volume 1 {
📝 NOTE: It was not possible to use RDMA with MOFED because we were unable to compile DRBD successfully.
📝 NOTE: So far no DRBD tuning was done.
DRBD test results
Absolute results:
| NVMe device | DRBD device | |
|---|---|---|
| sequential reads 1M bs GiB/s | ~3.2 | ~3.2
~5.1 with ReadBalancing |
| random reads 4K IOPS | ~780K | ~410K |
| sequential writes 1M bs GiB/s | ~2.3 | ~2.3 |
| random writes 4K IOPS | 300K (170K by vendor) | 170K |
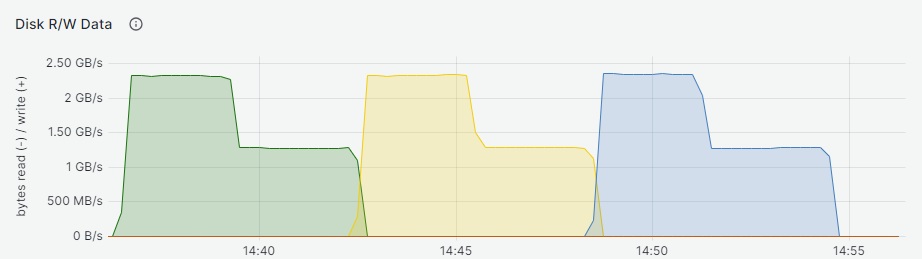
Over time sequential and random reads results are displayed in sequence below:
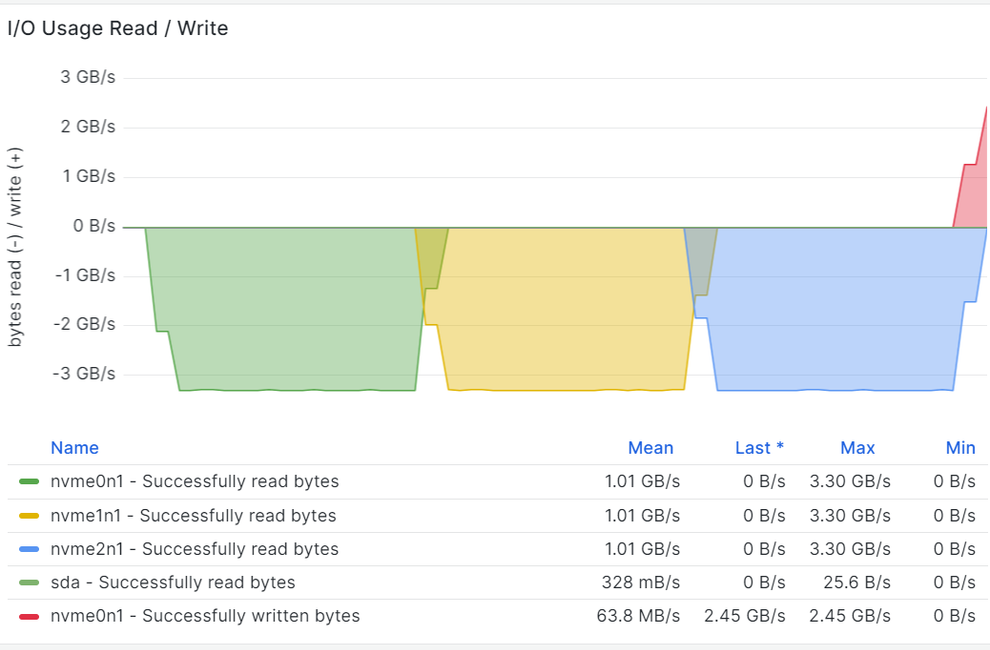
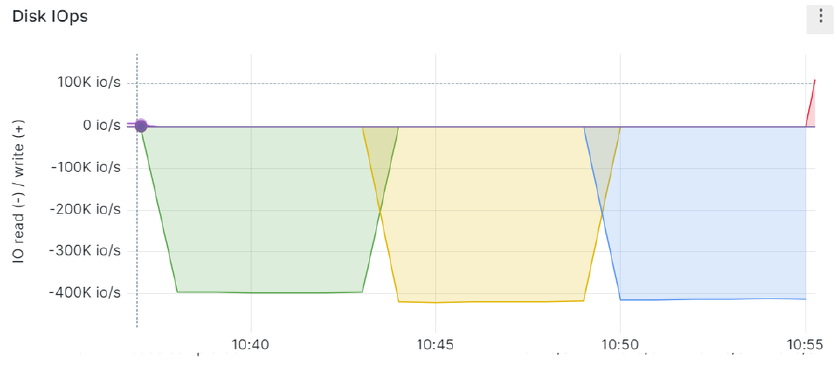
The sequential read workloads performed as if they were performed on the NVMe devices while the random reads experienced an almost 44% performance drop. Because the drop is considerable, random read tests were run again on the bare NVMe drive and confirmed to be similar to before: 780k.
During the execution of the sequential write workload, it was noticed that Fio had some sort of “pausing behavior“, which is reflected in the over time graph for the three DRBD devices:
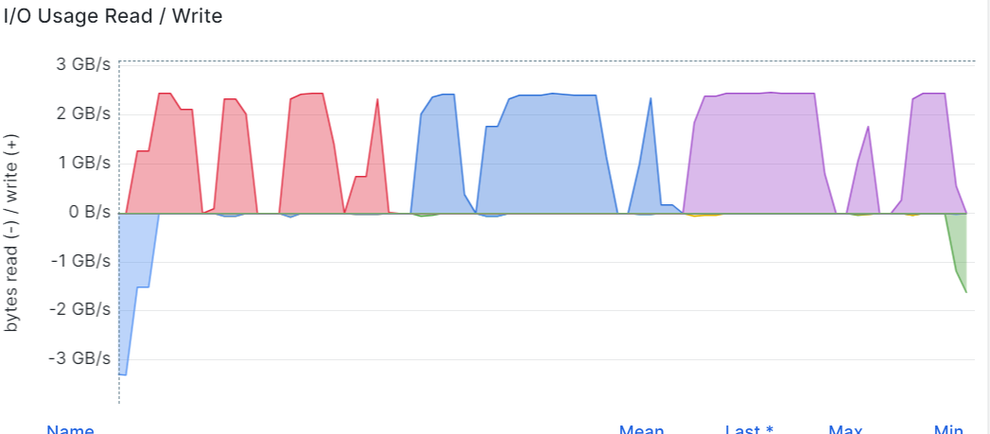
and inconsistent job execution for the three DRBD devices:
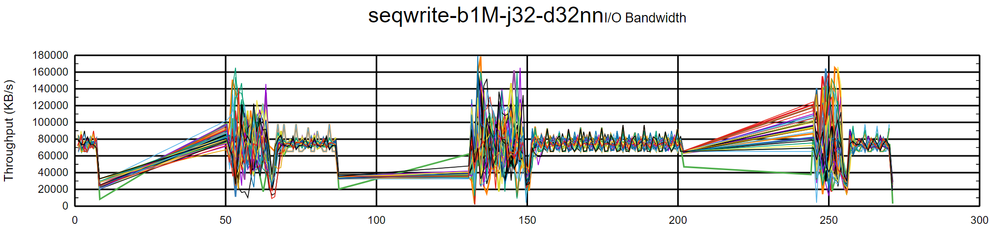
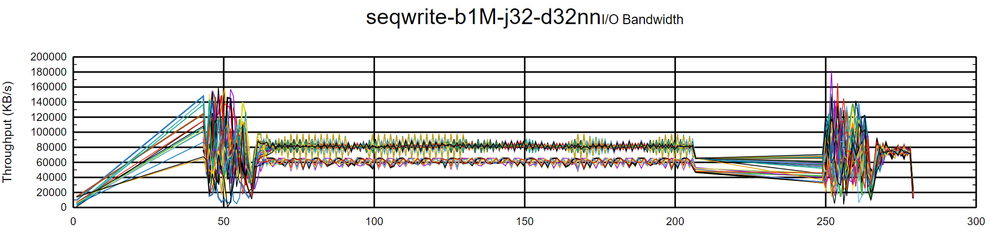
It was also noticeable that while the writes were occurring, the DRBD resource status was never reaching full synchronization, that is, reaching an “UptoDate“ status. Observability helped identify multiple TCP retransmissions and suboptimal TCP memory settings:
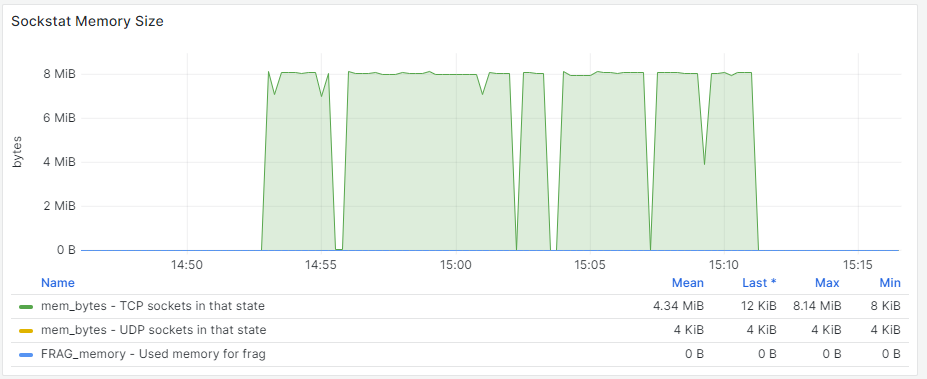
Kernel Tuning
Because of the TCP retransmissions experienced during the sequential test, the following changes have been applied to the kernel:
sysctl -w net.ipv4.tcp_slow_start_after_idle=0
sysctl -w net.core.rmem_max=56623104
sysctl -w net.core.wmem_max=56623104
sysctl -w net.core.rmem_default=56623104
sysctl -w net.core.wmem_default=56623104
sysctl -w net.core.optmem_max=56623104
sysctl -w net.ipv4.tcp_rmem='4096 87380 56623104'
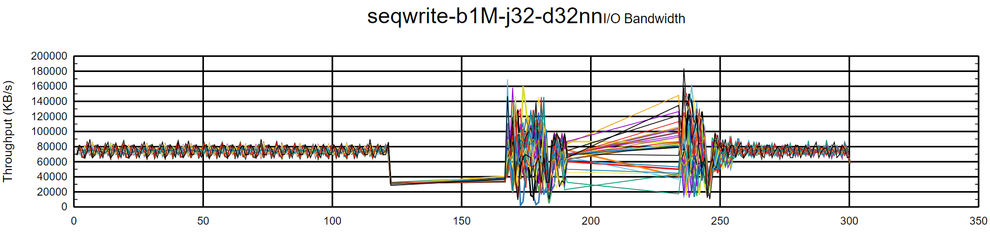
sysctl -w net.ipv4.tcp_wmem='4096 65536 56623104'After applying the kernel tuning, it was possible to obtain maximum throughput from the DRBD devices:
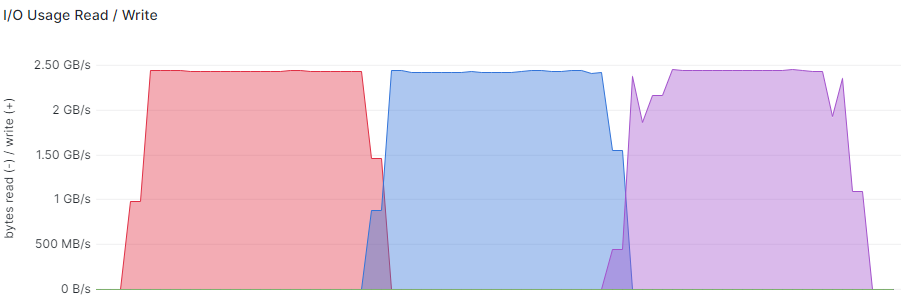
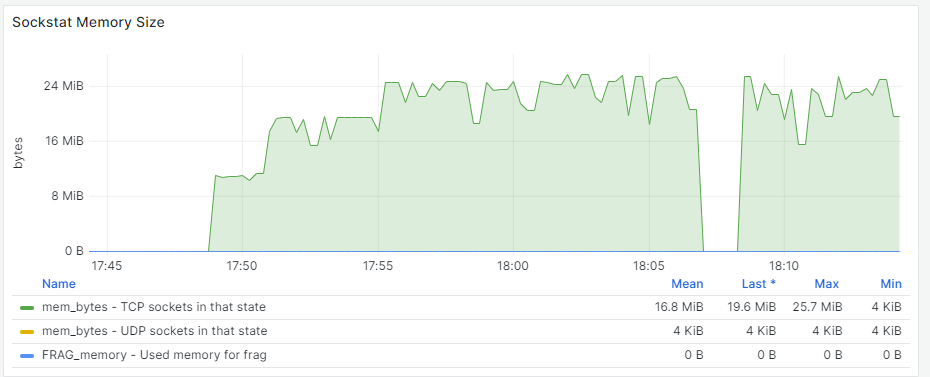
The last graph shows that the TCP memory utilized is far from reaching the custom values previously applied to the kernel.
Random write tests did not experience any drop during execution and reached an absolute result of around 170K IOPS.
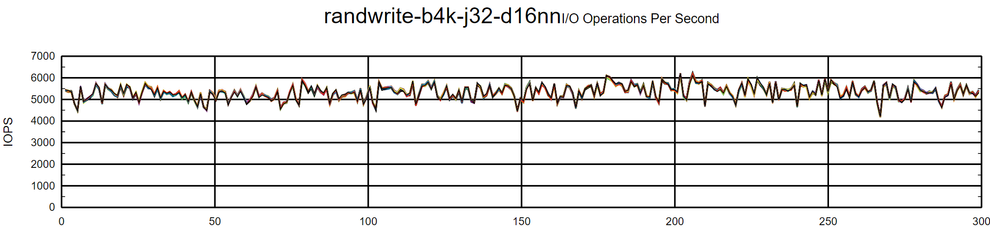
DRBD Tuning
MTU
Increasing the MTU to 9000 did not cause any improvement. As per the DRBD user manual, it is possible to get an idea of the latency difference between the DRBD device and the NVMe device using a single threaded dd command:
# dd if=/dev/zero of=/dev/drbd1 bs=4k count=100000 oflag=direct
100000+0 records in
100000+0 records out
409600000 bytes (410 MB, 391 MiB) copied, 5.20906 s, 78.6 MB/s
# drbdadm down r0
# dd if=/dev/zero of=/dev/nvme0n1 bs=4k count=100000 oflag=direct
100000+0 records in
100000+0 records out
409600000 bytes (410 MB, 391 MiB) copied, 1.15903 s, 353 MB/sCPU Mask
Because it is possible to observe CPU0 being used more than other CPUs, it seemed reasonable to allocate 24 CPUs to the DRBD resource, because 64 CPUs are available (with HT enabled):
options {
cpu-mask FFFFFF;
...
}During the write workload it is possible to observe the utilization of only one CPU, probably the one used by DRBD resource:
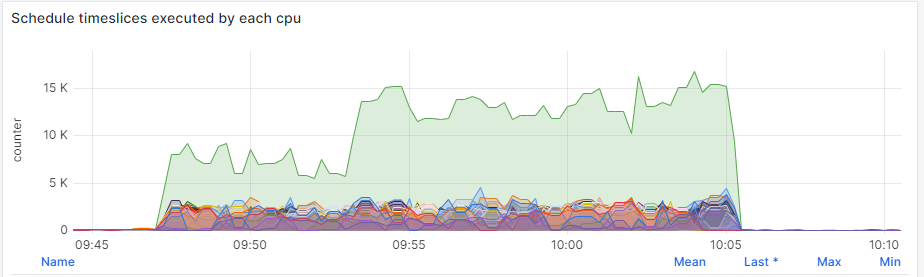
After setting up CPU mask to use the first 24 CPUs and let Fio jobs use the others: cpus_allowed=24-63, the CPUs consumption seems better distributed:
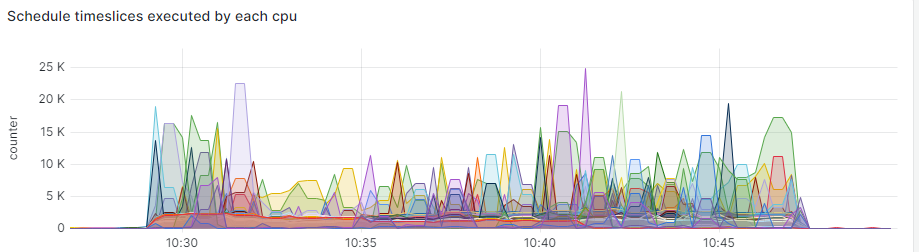
Finally the same CPUs masked by DRBD have been utilized by the Fio jobs:
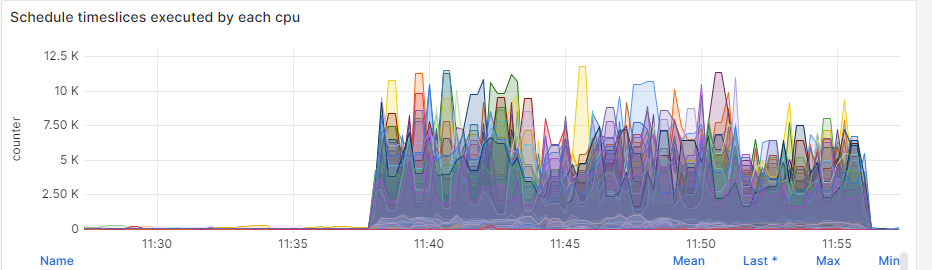
In both cases, it was not possible to observe an improvement of the random test results.
Read Balancing
Read tests were run again after enabling read balancing feature in “round robin“ mode across multiple paths:
[...]
disk {
read-balancing round-robin;
}
[...]
connection {
path {
host "idnode10.e4red" address 192.168.100.110:7900;
host "idnode12.e4red" address 192.168.100.112:7900;
}
path {
host "idnode10.e4red" address 192.168.100.111:7900;
host "idnode12.e4red" address 192.168.100.113:7900;
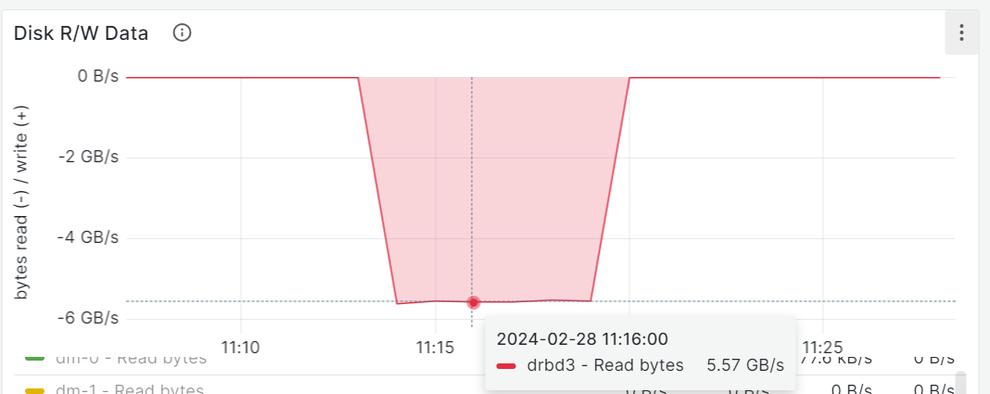
}As expected, enabling read balancing improved sequential read performance transfer speed by approximately 40%, but a reduction to around 190K IOPS with the random read workload was observed:
External Metadata
Random tests were run again with an external metadata device, to verify if this could improve the test results:
[...]
meta-disk /dev/nvme1n1;
[...]While using external metadata device nvme1n1, we can observe that reads occur only on the DRBD disk device and performances seem pretty much the same as without external metadata. Only during the write workload was it possible to notice some writes happening on the external metadata device with a slight decrease in latency values:
External Metadata
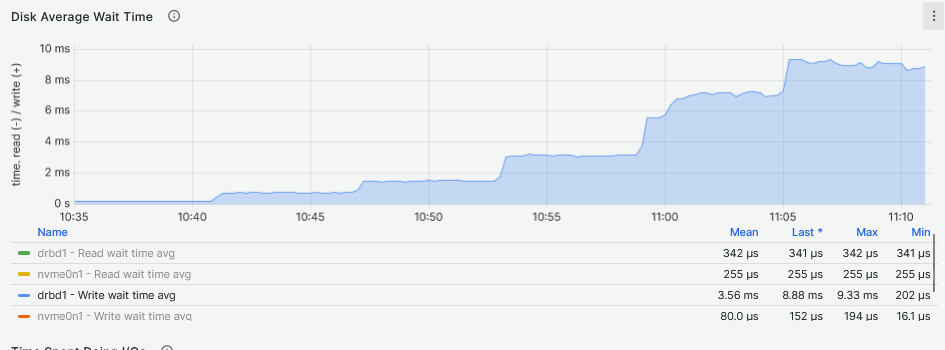
Internal Metadata
Scaling Random Performances
Further tests were carried out in order to understand why there is such a performance degradation while executing random workloads. During these tests the focus was on a single NVMe device resource, first the KIOXIA KCD6 and then Scaleflux CSDS drives. The following DRBD configuration was in place:
resource "r0" {
device /dev/drbd1;
disk "/dev/nvme0n1";
meta-disk internal;
protocol C;
net {
transport "tcp";
load-balance-paths yes;
rcvbuf-size 10M;
sndbuf-size 10M;
max-buffers 20k;
}
on "idnode10.e4red" {
node-id 10;
}
on "idnode12.e4red" {
node-id 12;
}
connection {
path {
host idnode10.e4red address 192.168.100.110:7000;
host idnode12.e4red address 192.168.100.112:7000;
}
path {
host idnode10.e4red address 192.168.100.111:7000;
host idnode12.e4red address 192.168.100.113:7000;
}
}
}The following Fio tests were used, executing random read and write workloads scaling from 1 to 64 workers per Fio job:
[global]
description=DRBD random
ioengine=libaio
time_based=1
startdelay=60
ramp_time=60
runtime=300
direct=1
📝 NOTE: The
filenameproperty will change according to the following devices:
drbd1based on the KIOXIA KCD61VUL3T20drbd2based on the Scaleflux CSDU5SPC38nvme0n1the actual KIOXIA KCD61VUL3T20nvme2n1the actual Scaleflux CSDU5SPC38
All the graphs that follow report the results for reads (below 0 on the x axis) and writes (above 0 on the x axis) in sequence. Each of the Fio jobs last five minutes in the following order: 1, 8, 16, 32, 48 and 64 workers.
KIOXIA KCD61VUL3T20
In the first image below, graphs were generated while running the tests on the NVMe bare device and in the second image, graphs were generated from tests run on the DRBD device on top of that NVMe drive:
Reads
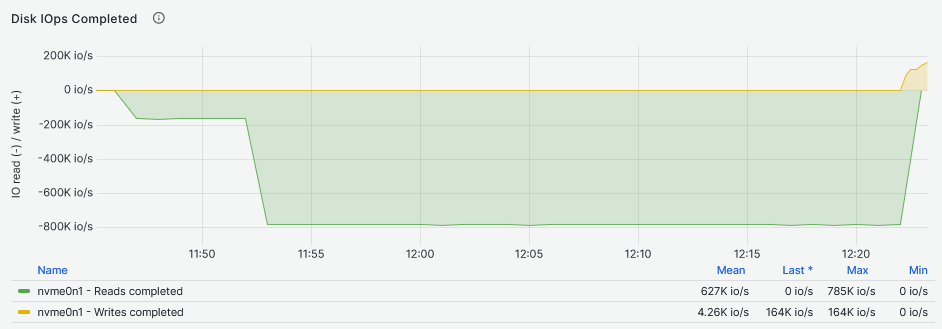
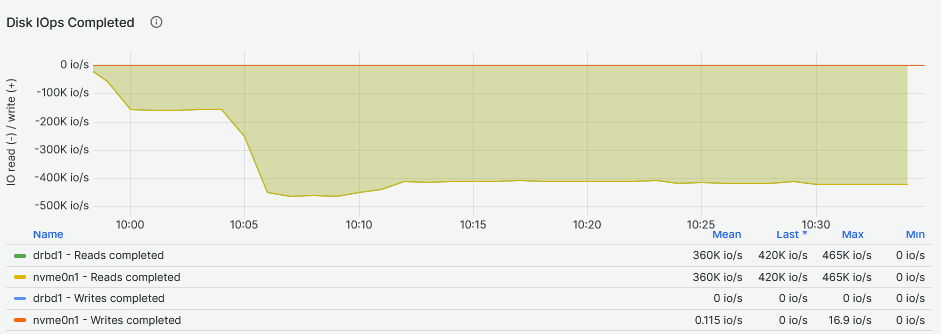
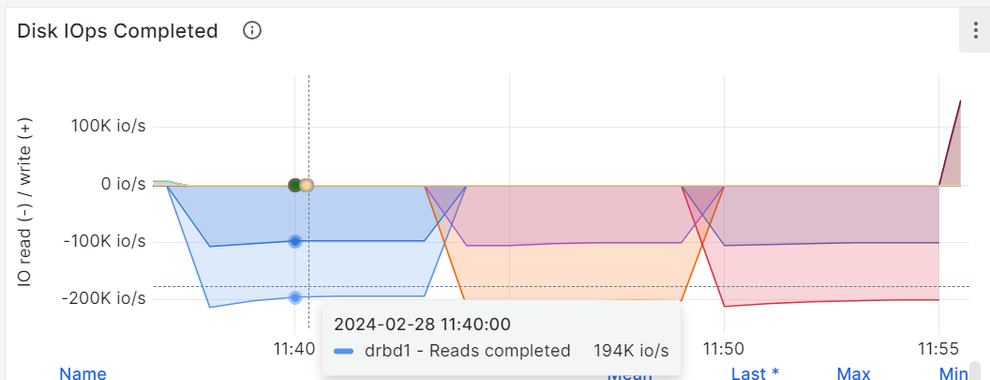
In the graphs above, it is possible to see that in the first five minutes of the single worker Fio job, the IOPS for the DRBD device, are similar to the bare NVMe drive. A noticeable difference starts to appear when we increase the number of workers to 8: the second five minutes frame. The NVMe drive exploits its parallelization capabilities and handles the multiple workers Fio jobs at a constant IOPS rate . Final observation: DRBD seems to perform slightly better, adding around 50K IOPS while still handling eight workers and stabilizes for the rest of the Fio jobs at 16, 32, 48 and 64 Fio workers.
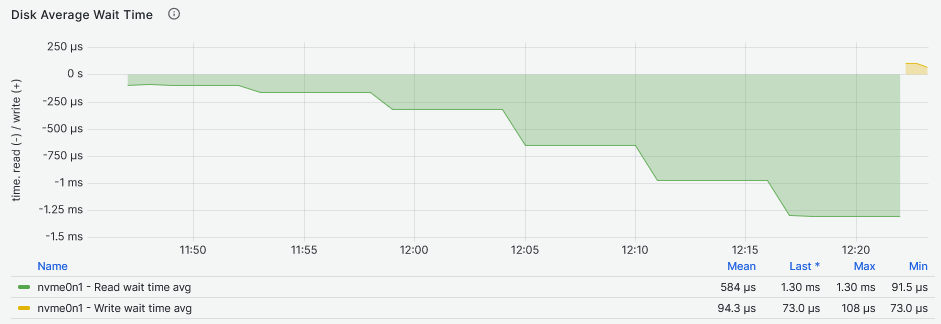
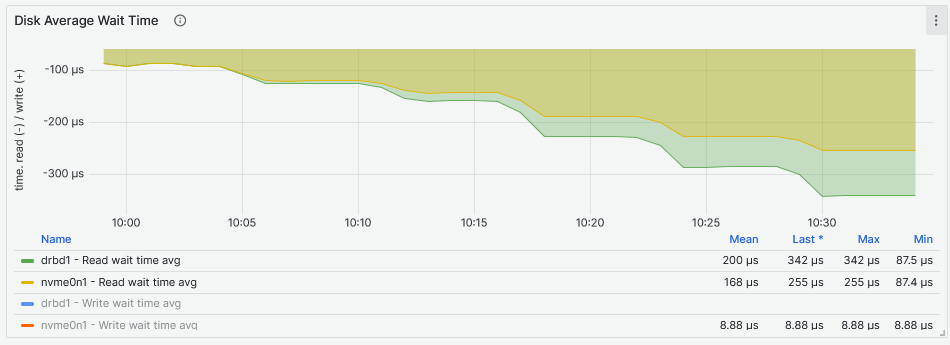
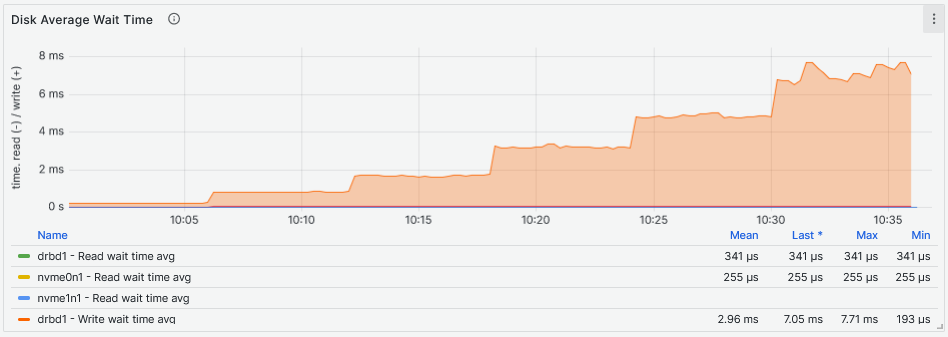
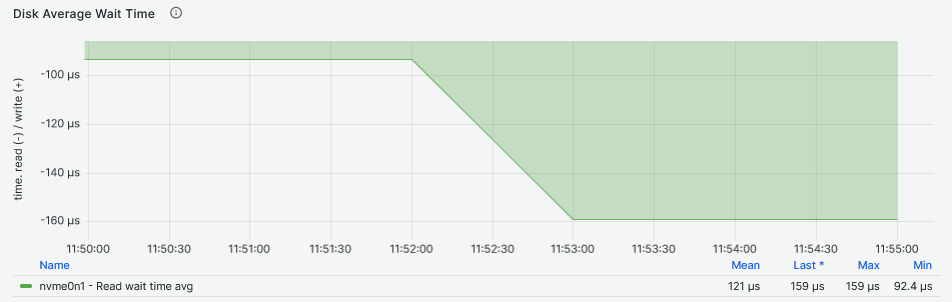
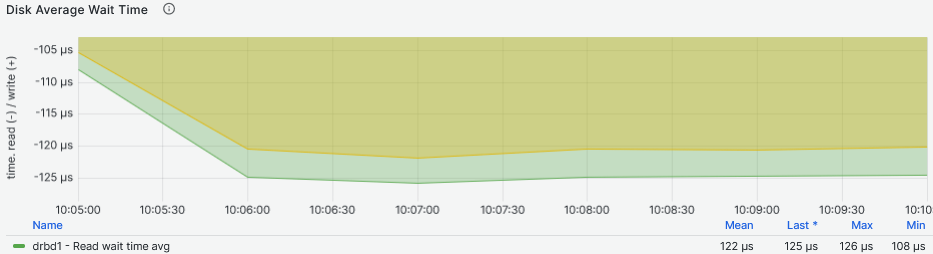
Looking at the latency two things are striking from the graphs above. The first thing is that the second graph shows that the DRBD device latency increases more than the NVMe drive latency with the increase of the Fio workers. The second thing is that the NVMe device increases latency more than the DRBD device while providing higher IOPS to more workers reaching above 1ms. The NVMe drive reaches maximum IOPS between 11:50 and 11:55 while the DRBD device reaches its maximum between 10:05 and 10:10, both while servicing eight Fio workers. If we have to compare the I/O latency, the NVMe drive achieves 159us and the DRBD device 125us:
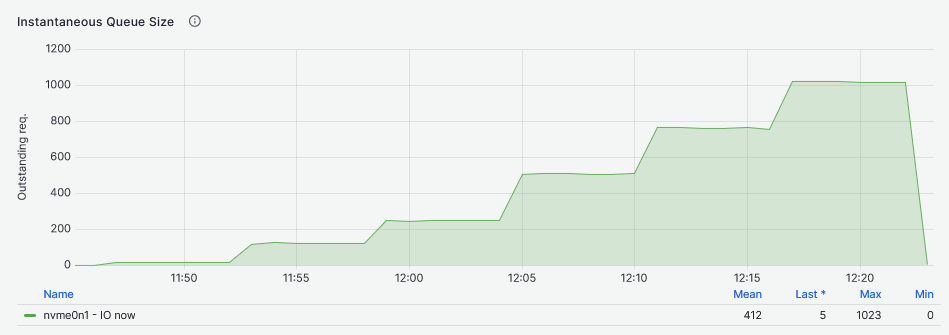
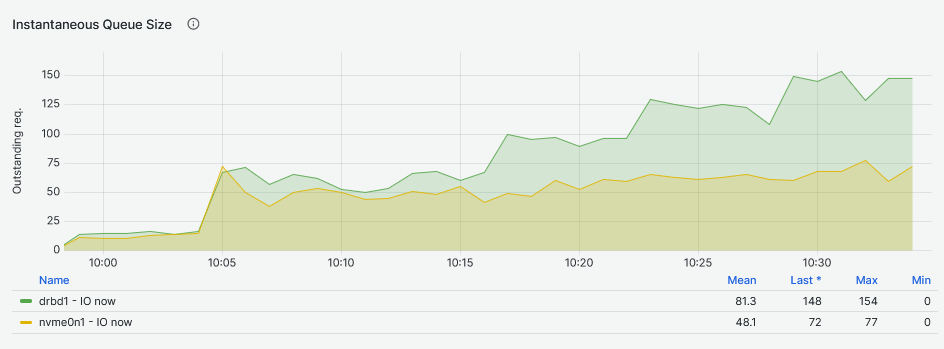
Testing the NVMe drive, the more I/O requests waiting in queue are a consequence of increasing the Fio workers, each worker configured to use a queue depth of 16. The queued I/O is in line with the expected queue values: 1024 for 64 workers, 768 for 48, and so on. For the DRBD device this rule is valid only for the single worker node (remember that IOPS and latency are at the same values as for the NVMe drive at this stage). The queue size increases at a much slower pace.
Finally, looking at the second graph, it shows the DRBD device I/O queue increasing after the single worker Fio job at a slower pace that eventually becomes higher than the NVMe drive I/O queue.
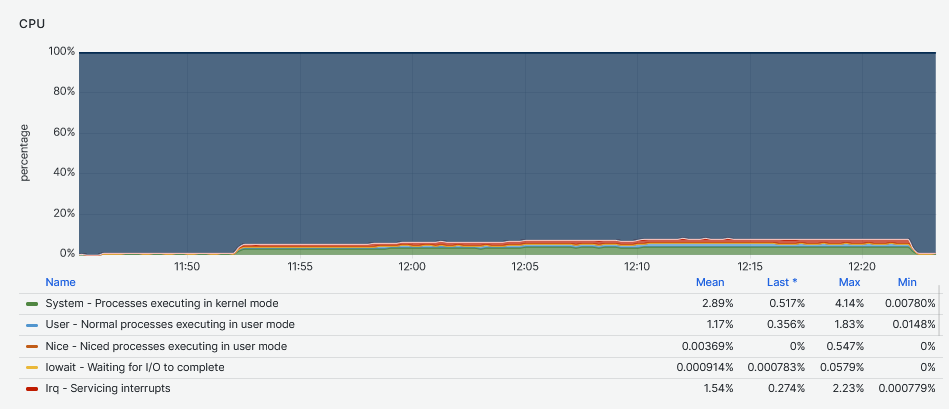
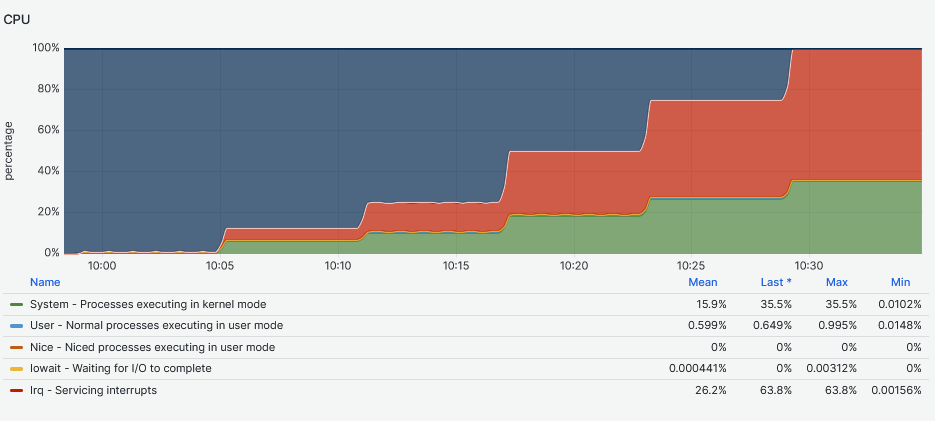
The second graph clearly shows the impact of the multiple workers jobs on the DRBD device. The node was dedicated to run only these Fio tests and the DRBD engine. Because the graph on the top does not have such CPU utilization, this suggests that the CPU system and IRQ servicing time is mostly caused by DRBD.
Writes
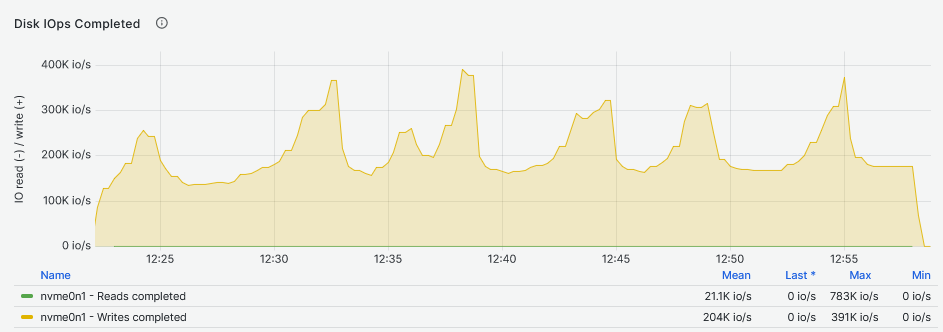
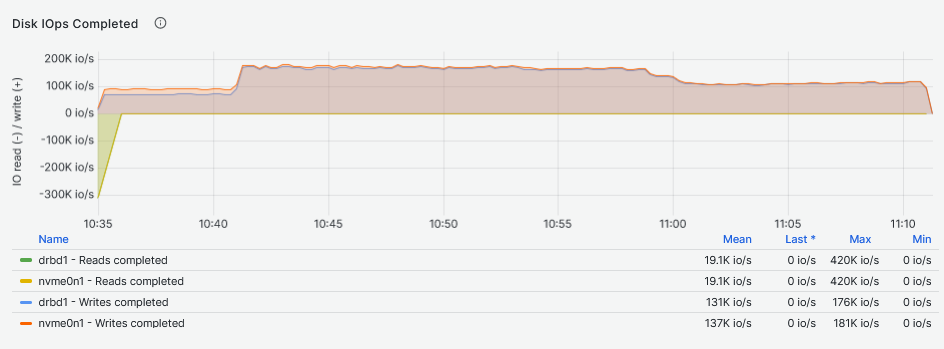
As shown in the top graph, the NVMe drive performance can reach peaks of 390K IOPS while a more realistic and consistent number is about 170K IOPS. The DRBD device could reach its maximum performances while running 8, 16 and 32 workers Fio jobs. This is perfectly in line with the NVMe drives consistent performance (and vendor spec sheet values). As for the reads, using 48 and 64 workers, the performance drops to about 130K IOPS.
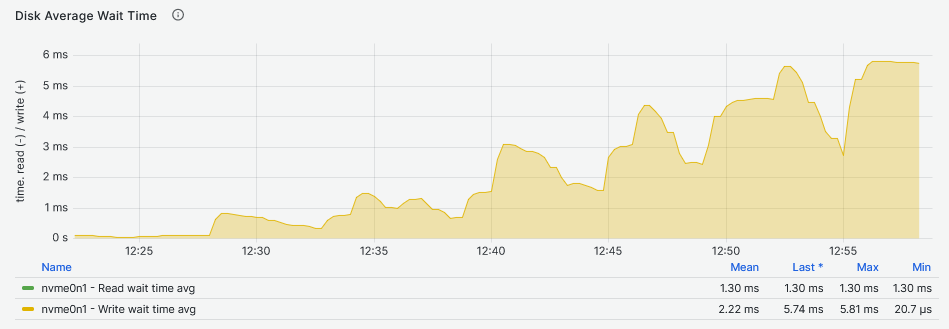
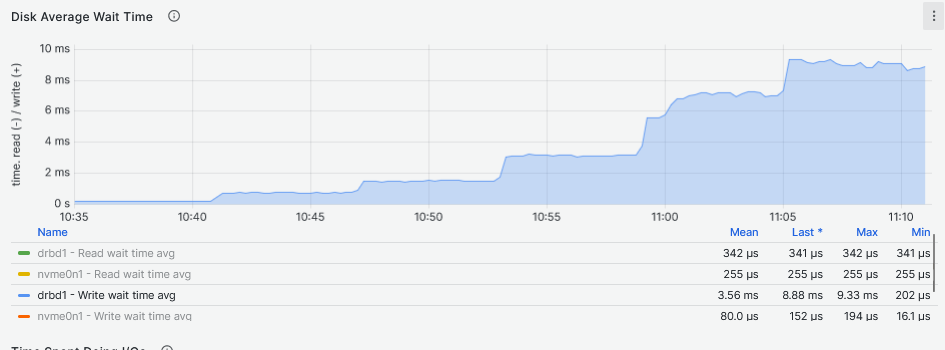
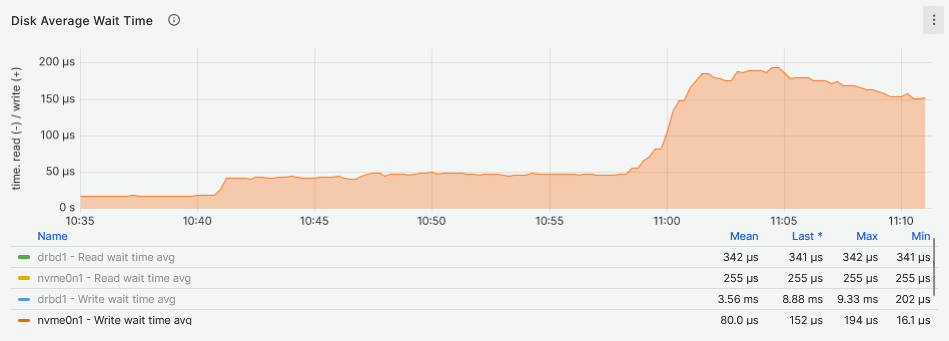
By looking at the latency graphs, it becomes clear that the latency comes from the DRBD device and not the underlying storage. Here, the sync replica must be taken into account. As for the IOPS, the DRBD device can maintain a very stable and consistent flat line that grows with the growth of the Fio workers count. Because the NVMe drive and DRBD device IOPS are the same for the second and third graphs below, the increase of latency starting at 11:00 (48 and 64 workers) for the NVMe drive, could be the reason why there is a drop in IOPS on the DRBD device.
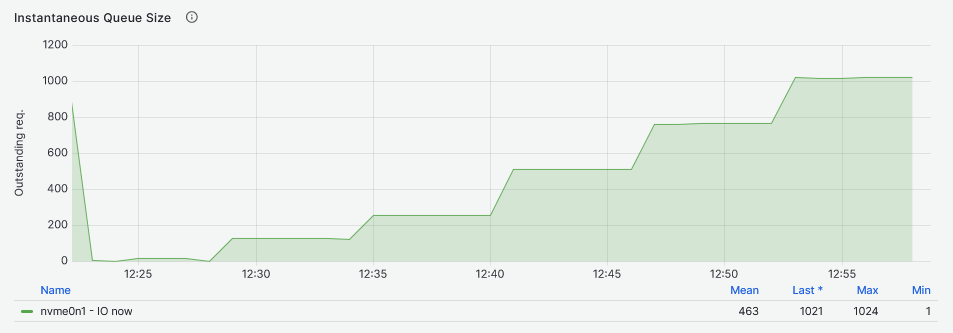
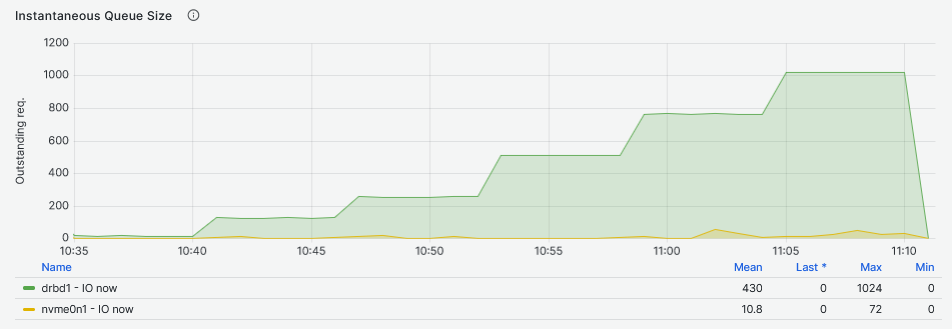
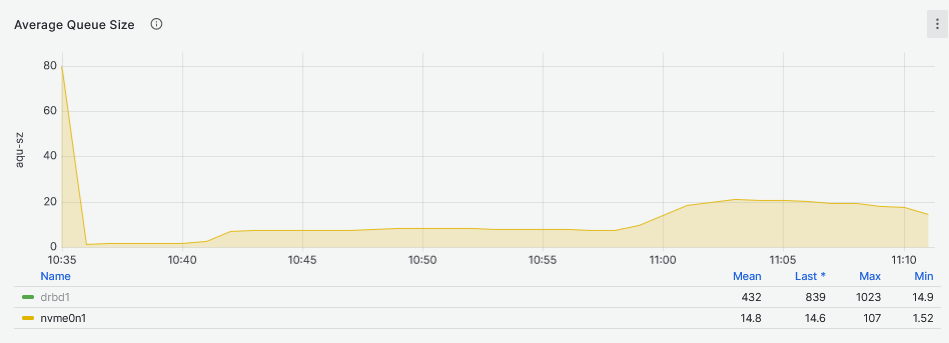
In contrast with the read workloads, the queue size of the DRBD device is almost identical to that of the NVMe drive.
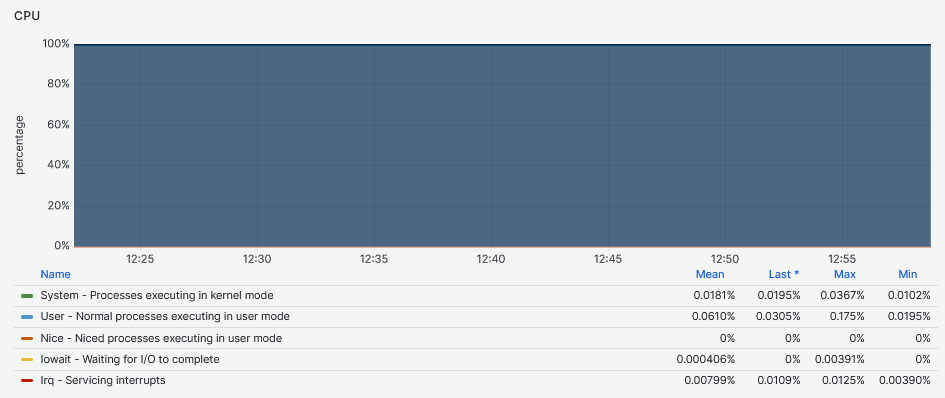
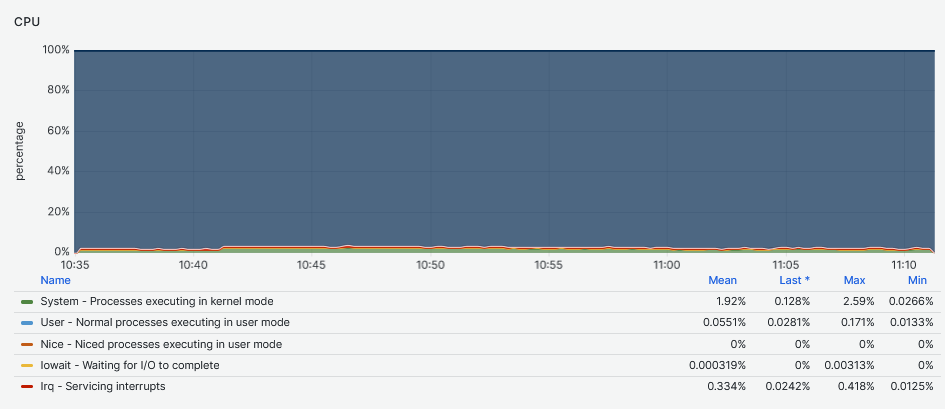
Also, the impact on the CPU is negligible during writes as opposed to read workloads.
Conclusion
The tests showed how DRBD is an efficient replication engine even when using NVMe drives. Albeit the tests have been carried out only with a single NVMe device, it was possible to reach its maximum transfer speed with a negligible CPU consumption. Configurations with more NVMe drives as stand alone resources or aggregated via specialized RAID engines, will be part of the next tests.
Thanks to the read balancing feature it was even possible to almost double the performance of the sequential read workload. This feature, however, is not suggested for random workloads.
Random writes performed as good as the drive spec sheet with a slight drop when running Fio jobs with 48 and 64 workers.
Albeit it was not possible to reach the drive maximum IOPS during random reads workload with higher Fio workers count, the DRBD device latency remained below the 400us with 64 worker nodes. The high queuing of the DRBD device in contrast with the underlying NVMe drive suggests that this behavior is a consequence of the DRBD engine design.
CPU masking is probably a feature to further explore while testing multiple drives or real life workloads.
DRBD Functionality
DRBD was very easy to implement and configure for a single resource. Its CLI is easy to grasp and once there is a good overview of the overall features, it’s not so hard to apply changes to the drbd.conf files, thanks to the excellent man pages made available.
Further testing needs to be carried out employing RDMA either by using the Linux OFED native drivers or by installing MOFED and re-compiling DRBD.
Prometheus node exporter includes DRBD extension however, some DRBD versions ago, stats are not populated in /proc/drbd anymore thus the exporter metrics are empty. To solve this, it is possible to install DRBD Reactor Prometheus plugin.
Other features such as disaster recovery, trim, device verification and traffic integrity settings are yet to be explored.


