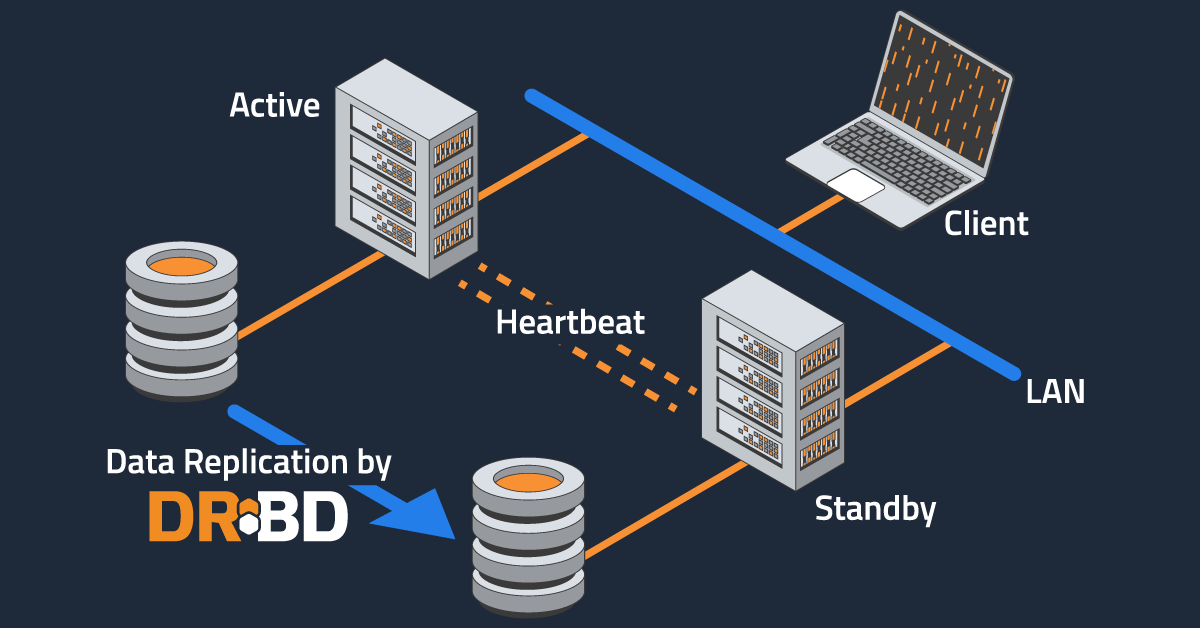
You have likely been reading about high availability (HA) everywhere and all the time, which is perhaps fitting for its name. This post will briefly talk about how DRBD® and a complimentary cluster resource manager, such as DRBD Reactor, can help you create a shared-nothing HA cluster.
The primary reason that you might want create a shared-nothing HA cluster is to keep your critical applications and services running and accessible. More and more, users have the expectation for services to be “always on.” This is especially true for businesses such as virtual private server (VPS) providers, e-commerce sites, digital payment platforms, and others. Even services that only have internal users, for example, a team of application developers or database administrators, can likely benefit from HA clustering if it means no downtime for their systems. A shared-nothing HA cluster can ensure that your team has no loss of productivity through events such as systems maintenance, upgrades, or failures.
The shared-nothing architecture
A shared-nothing architecture is normally based on at least two servers replicating data in real time with a cluster resource manager (CRM) handling automatic application failover in case of hardware or software failures on the active, or primary, server.
As mentioned earlier, shared-nothing HA clustering can help you stay up and running, even through routine events outside of failures, such as minimizing downtime during system maintenance.
Because data is replicated across the servers in your cluster in real time, the recovery time objective (RTO) in a failover is reduced to the time that it takes for your application to restart on the secondary server. This will usually happen in seconds if configured properly.
The flexibility and cost savings of a shared-nothing solution
The shared nothing architecture has no hardware constraints. You can use physical or virtual servers, with any type of disk, SSDs, NVMe drives, traditional spinning magnetic hard disk drives, and others. You do not need extra or dedicated hardware, and because you can use commercial off-the-shelf (COTS) devices, there is no hardware vendor lock-in. The LINBIT software mentioned in this article is open source so there is no software vendor lock-in either. The data that you make highly available by using DRBD remains accessible and recoverable using common tools familiar to most Linux system administrators, at all times, independent of whether DRBD is running or not.
How DRBD fits in
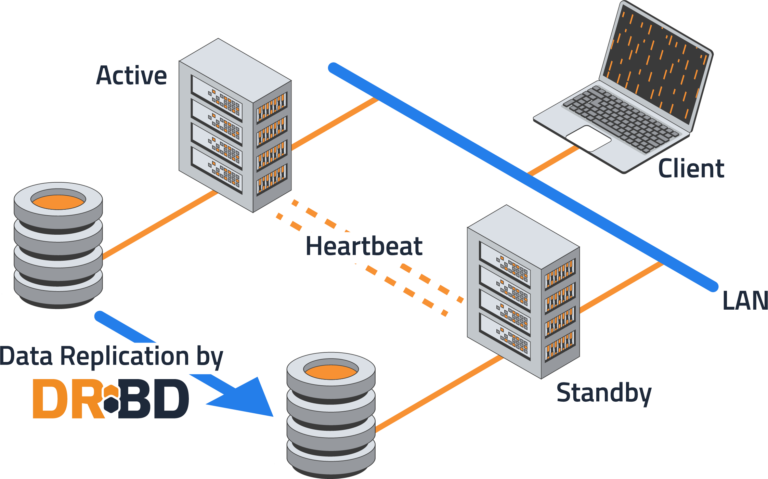
DRBD block replication in real time, also known as synchronous or Protocol C in DRBD-speak, is done between servers through standard network transport services, such as TCP/IP or RDMA. As mentioned earlier, real-time replication helps to make node failovers happen more quickly, because a perfect copy of data is available on a peer node or nodes in the shared-nothing HA cluster. After a CRM detects an issue with a node currently hosting data or services, failover can then happen as quickly as supporting services can be started on a peer node.
Alternatively, you can configure other DRBD replication protocols, depending on your environment and needs. You also might consider using DRBD Proxy for replicating data over distances, for disaster recovery purposes.
Running DRBD for Windows
DRBD is no longer limited to running exclusively on Linux systems. LINBIT®, the creator and primary developer of DRBD for more than 20 years, also offers WinDRBD® for Microsoft Windows. WinDRBD is wire-compatible with DRBD version 9. This means that you are no longer tied to using Linux servers for DRBD HA data replication. You can even replicate your data in a mixed Windows and Linux environment. If you are interested in learning more about WinDRBD, this article, Setting Up a Highly Available SMB Share for Windows by Using WinDRBD & DRBD, gives instructions for an example use case.
Using a cluster resource manager to handle automatic failovers
By using a CRM, such as DRBD Reactor, Pacemaker, or SIOS Lifekeeper, you can automate a task that a system administrator would otherwise need to do manually: failing over services to another cluster node if the node currently hosting services goes down. This might be because the node has a disk failure, loses its network connection, or some other event that prevents it from serving data reliably in the moment.
Using DRBD Reactor to manage highly available services
The LINBIT team created and developed DRBD Reactor to provide reliable CRM capabilities to clusters with DRBD replicated storage while being less complex to configure and manage than a CRM such as Pacemaker. You can learn more about the differences between DRBD Reactor and Pacemaker by reading a LINBIT blog article on the topic, “DRBD Reactor & Pacemaker: A Side-by-Side Comparison”.
Generally, DRBD Reactor is an easier to configure CRM than Pacemaker but it does have some limitations which might make Pacemaker a better fit for some use cases. For example, a DRBD Reactor cluster requires three nodes because it uses the DRBD quorum feature to prevent data divergence (so-called split-brain events). A LINBIT video comparing DRBD Reactor and Pacemaker has a helpful segment that overviews some of the differences and limitations of each CRM.
There is also an introduction to using DRBD Reactor as an alternative CRM in the article “Implementing High Availability by Using DRBD Reactor and its Promoter Plugin as an Alternative Cluster Resource Manager”. The article includes design and implementation details, example commands for setting up a basic highly available file system mount, and a couple of failover examples where the file system mount persists after node-level failures.
Conclusion
The LINBIT team supports customers who are using Pacemaker or DRBD Reactor as a CRM in HA clusters. LINBIT is also a technology partner with SIOS, whose SIOS Lifekeeper CRM solution for Linux and Windows server high availability and disaster recovery uses DRBD underneath.
Regardless of the CRM that you choose, DRBD Reactor, Pacemaker, or SIOS Lifekeeper, by using your chosen CRM with DRBD replicated storage resources, you will have a total solution for a shared-nothing high-availability cluster.
Changelog
2025-01-27:
- Added mentions of SIOS and SIOS Lifekeeper
- Made minor language improvements
2024-12-18:
- Added links to more learning resources
- Made language touch-ups and minor structural changes
2022-11-16:
- Originally published article