
Over time, LINBIT® has built a variety of software components for use in highly-available systems. These components range from DRBD® for block device replication to LINSTOR®, our SDS solution, to various plugins/scripts integrating DRBD into Pacemaker, OpenStack, OpenNebula, Proxmox, Kubernetes, and more. However, a missing component was a daemon that monitors DRBD events like a resource becoming Primary or losing connection to its peers and then reacting to it. One could apply such a component for various purposes, ranging from monitoring tasks to classic HA tasks usually carried out by complex cluster managers such as Pacemaker.
In this first part of a blog series about drbd-reactor, we will briefly overview the design and discuss the different tasks it can carry out. Then, in other blog posts, we will go into the details of every plugin.
Design
We saw multiple applications for such a component as drbd-reactor, so it was natural that we split reactor into a core component that collects DRBD events and several plugins that carry out different tasks (monitoring, HA,…). The core is responsible for collecting DRBD events, preparing them, and sending them to the plugins. Such prepared messages usually consist of the old DRBD state and the current/new one. Think of these updates as diffs. Plugins can subscribe to two different types of update message channels: coarse-grained and significant DRBD state changes, and another that is more fine-grained that contains every state change, including DRBD statistics updates (e.g., blocks out of sync).
There are different types of plugins which we will discuss in a minute. Still, it is essential to know that plugins can be instantiated multiple times, so there can be multiple instances of every plugin type. So, for example, numerous plugin instances could take care of high availability, one per DRBD resource.
Without going into details, it is important that the core/daemon can be reloaded with a new and additional configuration. It manages to stop plugin instances no longer required and start new plugin threads without losing DRBD events. Last but not least, the core has to make sure that plugins receive an initial and complete DRBD state.
We wanted to keep reactor as simple as possible, so there is no cluster communication between different DRBD reactors running on different cluster nodes. However, as we will see, this is not necessary as DRBD itself contains enough information (e.g., DRBD quorum).
Plugins
This section will provide a brief overview of the available plugins and why they exist. Then, we will discuss these plugins individually in follow-up blog posts.
Debugger
This one is the least exciting but helps developers to see what information plugins will receive. It is mentioned for completeness, but one would not use it in production; it just spits out a stream of state change messages.
UMH - User Mode Helper
Experienced DRBD users will know that DRBD (yes, the part in the Linux kernel) can call user-defined helper scripts if several important events happen, like before a resource becomes sync target. Such a script would then create a snapshot of the backing device. Over time, users found creative new ideas for what they wanted to execute scripts. Still, these ideas can be user/customer-specific, and adding tens or hundreds of new event categories to the kernel module would not make sense. So with the help of this plugin and a simple DSL (Domain Specific Language), users can execute scripts if an event they define occurs. For example, they could run a script that sends a slack message whenever a DRBD resource loses connection. Another disadvantage we can solve is that the kernel module executes such helpers stored on the host file system, which does not fit a containerized world with read-only host file systems. In contrast, drbd-reactor can be executed in a container.
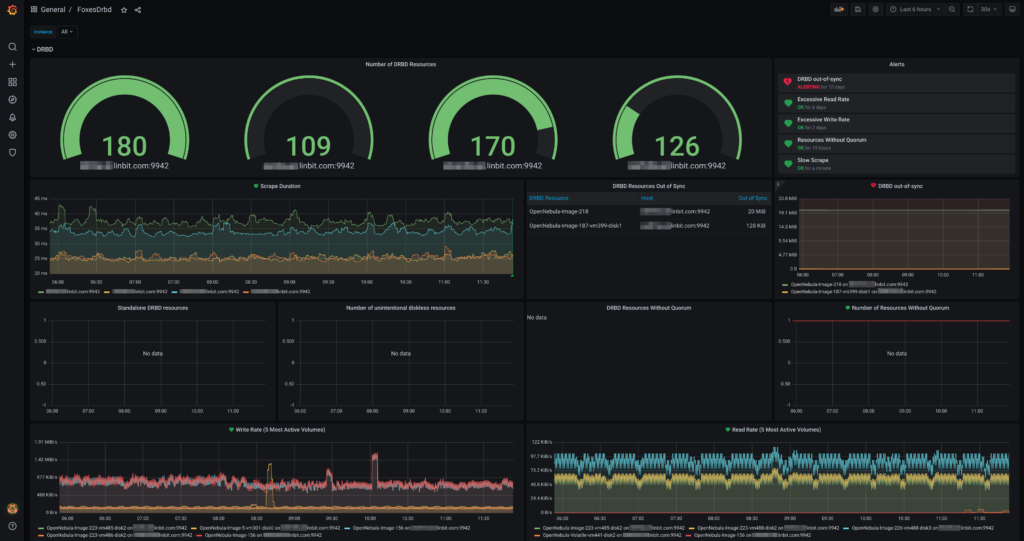
Prometheus
This plugin provides a prometheus.io compatible endpoint that exposes various statistics, including out-of-sync bytes, resource roles (e.g., Primary), and connection states (e.g., Connected). This information can then be used in every monitoring solution that supports Prometheus endpoints. We also provide a template dashboard for Grafana:
Promoter
The promoter plugin certainly is one of the most interesting ones as it allows for high availability. Its principal task is simple: If a DRBD device can be promoted, promote it to Primary and start a set of user-defined services. This could be a series such as:
- Promote the DRBD device
- Mount the device to a mount point
- Start a database that uses a DB located at the mount point
If a resource loses quorum, stop these services so that another node that still has quorum (or when quorum is established again) can start the services. The promoter plugin also supports OCF agents and failure actions such as rebooting a node on stop failures.
We developed this plugin for multiple reasons: DRBD already has a notion of quorum, and in most cases, we/our customers are interested in what is good enough. We even want to avoid having multiple notions of quorum within the cluster (e.g., DRBD quorum vs. corosync quorum). DRBD itself knows best where it has “good data” and which node to promote. Pacemaker is pretty complex, while the core of the promoter plugin is like 100 lines of code. Promoter shifts all the complexity to other existing components, like DRBD quorum and systemd for service starting. One can even think of the promoter plugin as a pretty elaborate systemd service file override and target generator. Last but not least, building Pacemaker is very time-consuming and complex, and access to packages might require extra subscriptions, while drbd-reactor is just a single cargo build away.
We recommend using this plugin for LINSTOR controller high-availability and use it as part of LINBIT vSAN.


