DRBD9 ユーザーズガイド
はじめにお読みください
本書はDistributed Replicated Block Device (DRBD)を利用するための完全なリファレンスガイドです。同時にハンドブックとしても活用できるように編集してあります。
本書はDRBDプロジェクトのスポンサーである LINBIT がそのコミュニティ向けに作成しています。そしてコミュニティにとって有益であることを願って無償で公開しています。本ユーザーズガイドは、随時更新しています。DRBDの新しいリリースと同時に、その新機能の説明を追加する予定です。オンラインHTML版は https://linbit.com/drbd-user-guide/drbd-guide-9_0-ja/ で公開しています。
| このガイドはDRBDの最新バージョンのユーザーを対象にしています。DRBDバージョン8.4をご使用の場合には https://linbit.com/drbd-user-guide/users-guide-drbd-8-4-japanese-version/ から対応するバージョンをご利用ください。 |
Use the LINBIT community forum to submit comments.
このガイドは次のように構成されています。
-
DRBDの紹介 ではDRBDの基本的な機能を扱います。Linuxの I/OスタックにおけるDRBDの位置付け、DRBDの基本コンセプトなど、基礎となる事項を取り扱います。また、DRBDのもっとも重要な機能について説明します。
-
DRBDのコンパイル、インストールおよび設定 ではDRBDのビルド方法、コンパイル済みのパッケージからのインストール方法、またクラスタシステムでのDRBDの運用方法の概要について説明します。
-
DRBDの使い方 ではリソース設定ファイルと一般的なトラブルシューティングについて説明します。
-
DRBDとアプリケーションの組み合わせ では、DRBDを活用してアプリケーションにストレージレプリケーションと高可用性を追加する方法を扱います。PacemakerクラスターマネージャーへのDRBD統合をはじめ、高度なLVM構成、DRBDとGFSの統合、DRBDでのOCFS2の利用、さらには、設定やデプロイがより容易なクラスターリソースマネージャーとして、LINBIT社が開発したオープンソースのDRBD Reactorソフトウェアについても解説しています
-
DRBDパフォーマンスの最適化 ではパフォーマンスを向上させるDRBDの設定について説明します。
-
さらに詳しく知る ではDRBDの内部構造を説明します。読者に有益と思われる他の情報リソースについても紹介します。
-
付録:
-
最近の変更 はこれまでのDRBDバージョンと比較した、DRBD9.0での変更点の概要です。
-
DRBDトレーニングやサポートサービスにご興味のある方は [email protected] または [email protected] にお問い合せください。
DRBDの紹介
1. DRBDの基礎
Distributed Replicated Block Device (DRBD)は、ストレージのレプリケーション(複製)のためのソフトウェアで、シェアードナッシングを実現します。DRBDはサーバ間でブロックデバイス(ハードディスク、パーティション、論理ボリュームなど)の内容をミラーします。
DRBDによるミラーは次の特徴を持ちます。
-
リアルタイムレプリケーション. 上位アプリケーションがデバイスのデータを書き換えると、そのデータをリアルタイムでレプリケートします。
-
アプリケーションから透過的. アプリケーションは、データが複数のホスト上に格納されていることを意識する必要はありません。
-
同期 または 非同期 の両方に対応同期でミラーリングを行う場合には、すべてのホストのディスクへの書き込みが完了した後で、アプリケーションが完了通知を受け取ります。非同期でミラーリングを行う場合には、ローカルディスクへの書き込みが完了したときに、すぐにアプリケーションが完了通知を受け取ります。この際、他のホストへの書き込みは後で行われます。
1.1. カーネルモジュール
DRBDのコア機能はLinuxのカーネルモジュールとして実装されています。OSのI/Oスタックの下位の階層でDRBDは仮想的なブロックデバイスを作ります。このために、DRBDは非常に柔軟で応用範囲が広く、さまざまなアプリケーションの可用性を高めるために利用できます。
その定義とLinuxカーネルアーキテクチャとの関連にもとづき、DRBDは上位レイヤに関して一切関知しません。このため、DRBDは上位レイヤに対しては何ら機能を付与できません。たとえば、DRBDはファイルシステムの障害を検出できません。またext3やXFSなどのファイルシステムに対してアクティブ-アクティブクラスタ機能を追加することもできません。

1.2. ユーザー空間の管理ツール
DRBDにはカーネルモジュールと通信を行う管理ツールがいくつか用意されています。トップレベルのものからボトムレベルの順に以下に説明します。
drbdadmDRBD-utilsプログラムスイートの高度な管理ツール。設定ファイル /etc/drbd.conf からすべてのDRBD設定パラメータを取得し、drbdsetup と drbdmeta のフロントエンドとして機能します。drbdadm には、-d オプションを付けて呼び出すことで、実際にそれらのコマンドを呼び出さずに drbdadm が発行する drbdsetup と drbdmeta の呼び出しを表示する「ドライラン」モードがあります。
drbdsetupカーネルにロードされたDRBDモジュールを設定します。 drbdsetup の全パラメータはコマンドラインで指定する必要があります。 drbdadm と drbdsetup を分離していることで最大限の柔軟性を確保しています。ほとんどのユーザーは drbdsetup を使う事はないでしょう。
drbdmetaDRBDメタデータ構造を作成、ダンプ、復元、および変更する機能を提供します。drbdsetup と同様に、ほとんどのユーザーは直接 drbdmeta を使用する必要はほとんどありません。
1.3. リソース
DRBDでは、レプリケートするデータセットに関するさまざまな属性を総称して リソース と呼びます。リソースは以下の要素で構成されます。
個々のリソースを区別するために、ホワイトスペース以外のUS-ASCII文字で表される任意の名前を与えることができます。
DRBD 9.2.0から、リソースの命名規則がより厳密になりました。DRBD 9.2.xでは、リソース名には英数字、., +, _ , - の文字のみを受け付けます(正規表現: [0-9A-Za-z.+_-]*)。以前の動作に依存している場合は、厳密な名前のチェックを無効にすることで元の動作を復元することができます: echo 0 > /sys/module/drbd/parameters/strict_names。
|
どのリソースも、複数のレプリケーションストリームを共有する ボリュームのうちの1つを構成するレプリケーショングループですDRBDは、リソース内のすべてのボリューム間で書き込みの忠実性を保証します。ボリュームは 0 から番号付けされ、1つのリソースにおいて、最大で65,535ボリュームまで可能です。ボリュームにはレプリケートされたデータセットを含み、DRBD内部で使用するメタデータのセットも含みます。
drbdadm コマンドでは、リソース内のボリュームを、リソース名とボリューム名を <resource>/<volume> のように記述して指定します。
DRBDが管理する仮想的なブロックデバイスです。DRBDが管理する仮想的なブロックデバイスで、147のメジャー番号を持ち、minor番号は0から順次割り振られます。各DRBDデバイスは、リソース内の1つのボリュームに該当します。関連付けられたブロックデバイスは通常 /dev/drbdX の形式になり、 X はデバイス番号です。通常 udev は #/dev/drbd/by-res/#resource/vol-nr にあるリソース名とボリューム名を含むシンボリックリンクも作成します。
DRBD のインストール方法によっては、RPM ベースのシステムに drbd-udev パッケージをインストールして、DRBD udev ルールをインストールする必要がある場合があります。DRBD udev ルールがインストールされる前にDRBDリソースが作成された場合は udevadm trigger コマンドを使用して、udevルールを手動でトリガーし、DRBDリソースの udev シンボリックリンクを生成する必要があります。
|
| 初期のバージョンのDRBDは、NBDのデバイスメジャー番号43を勝手に使っていました。現在は 147 という番号が、DRBD デバイスメジャー番号として、 allocated に登録されています。 |
コネクション はレプリケートされるデータセットを共有する、2つのホスト間の通信リンクです。DRBD9では、各リソースが複数のホストで設定できますが、この場合、現在のバージョンではホスト間にフルメッシュ型の接続が必要です。つまり、リソース用に各ホストは他のホストへの接続が必要です。
drbdadm では、コネクションはリソース名とコネクション名(デフォルトでは対向のホスト名)で指定されます。
1.4. リソースのロール
DRBDのすべての リソース は プライマリ または セカンダリ のどちらかのロール(役割)を持っています。
| 「プライマリ」と「セカンダリ」という用語は適当に選んだものではないことを理解してください。DRBD開発者は意図的に「アクティブ」と「パッシブ」という用語を避けました。 プライマリ と セカンダリ は ストレージ の可用性に関する概念です。一方、 アクティブ と パッシブ は アプリケーション の可用性に関する概念です。ハイアベイラビリティクラスタ環境では、一般的にアクティブノードのDRBDは プライマリ になりますが、これが例外のないルールだということではありません。 |
-
プライマリロールのDRBDデバイスでは、データの読み込みと書き込みが制約なく行えます。 この状態のストレージに対しては、ファイルシステムの作成やマウントが可能であり、 ブロックデバイスに対する下位デバイスI/OやダイレクトI/O等も可能です。
-
セカンダリ ロールのDRBDデバイスは、対向するノードのすべてのデータの更新を受け取りますが、 他からのアクセスは受け付けません。 つまり自ノードのアプリケーションからのアクセスについても、読み込みと書き込みの両方とも一切受け付けません。 読み込みすら受け付けない理由は、 キャッシュの透過性を保証するためです。 もしもセカンダリリソースが自ノードからのアクセスを受け付けると、この保証ができなくなります。
リソースのロールは、もちろん 手動で切り替えできる他に、クラスタ管理アプリケーションの何らかの自動化アルゴリズムによって、または 自動プロモーション でも切り替えられます。セカンダリからプライマリへの切り替えを 昇格 と呼びます。一方プライマリからセダンダリの切り替えは 降格 と呼びます。
1.5. ハードウェアと環境の要件
DRBD のハードウェア、環境の要件と制限を以下に示します。DRBD は、数 KiB の物理ストレージとメモリで動作しますし、数 TiB のストレージと数 MiB メモリで動作するようにスケールアップもできます。
1.5.2. 必要なメモリ
DRBDはストレージ1TiBにつき約32MiBのRAMを必要とします[1]。したがって、DRBDの最大ストレージ容量(1PiB)を扱う場合、オペレーティングシステム、ユーザ空間、バッファキャッシュなどの分を考慮する前の段階で、DRBDのビットマップだけで32GiBのRAMが必要になります。
1.5.3. CPU 要件
DRBD 9 は、次の CPU アーキテクチャ向けのビルドがテストされています。
-
amd64
-
arm64
-
ppc64le
-
s390x
DRBD 9 の最近のバージョンは、64 ビット CPU アーキテクチャビルドのみがテストされています。32 ビット CPU アーキテクチャビルドはサポートされておらず、動作するかどうかは不明です。
1.6. FIPSコンプライアンス
この標準は、暗号モジュールの設計および実装に使用されます。 — NIST’s FIPS 140-3 publication
DRBDバージョン9.2.6以降、 TLS機能 を使用してDRBDトラフィックを暗号化することが可能になりました。ただし、DRBD自体には暗号モジュールが含まれていません。DRBDは、ktls-utils パッケージ( tlshd デーモンで使用される)または Linuxカーネル暗号API で参照される 暗号モジュールを使用します。いずれの場合も、DRBDがトラフィックを暗号化するために使用する暗号モジュールは、FIPS準拠であり、FIPSモードが有効になっているオペレーティングシステムを使用している限り、FIPS準拠になります。
TLS機能を有効にしていない場合、DRBDは暗号モジュールを使用しません。
DRBDのバージョン9.2.6以前では、暗号化を利用する場合、DRBD自体ではなく別のブロックレイヤーで実装する必要がありました。Linux Unified Key Setup(LUKS)はそのような実装の一例です。 LINSTORユーザーガイド には、LINSTORをDRBDレイヤーの下にLUKSレイヤーを重ねる方法についての詳細が記載されています。
| LINSTORの外でDRBDを使用している場合、DRBDの上にLUKSを重ねることができます。ただし、この実装は推奨されていません。なぜなら、DRBDがディスクレスにアタッチしたりリソースを自動昇格したりできなくなるからです。 |
2. DRBDの機能
本章ではDRBDの有用な機能とその背景にある情報を紹介します。いくつかの機能はほとんどのユーザーにとって重要な機能ですが、別のいくつかの機能については特定の利用目的においてのみ関係します。これらの機能を使うために必要な設定方法については、 DRBDの使い方 および トラブルシューティングとエラーからの回復 を参照してください。
2.1. シングルプライマリモード
シングルプライマリモードでは、個々の リソース は、任意の時点でクラスタメンバのどれか1台のみプライマリになれます。どれか1台のクラスタノードのみがデータを更新できることが保証されるため、従来の一般的なファイルシステム(ext3、ext4、XFSなど)を操作するのに最適な処理モードと言えます。
一般的なハイアベイラビリティクラスタ(フェイルオーバタイプ)を実現する場合、DRBDをシングルプライマリモードで設定してください。
2.2. デュアルプライマリモード
デュアルプライマリモードでは、リソースは一度に 2 つのノードでプライマリの役割を担うことができます。したがって、データへの同時アクセスが可能であるため、このモードでは通常、分散ロックマネージャーを利用する共有クラスターファイルシステムを使用する必要があります。 利用できるファイルシステムには GFS や OCFS2 があります。
2つのノード経由でのデータへの同時アクセスが必要なクラスタシステムの負荷分散をはかりたい場合、デュアルプライマリモードが適しています。例えばライブマイグレーションが必要な仮想化環境などです。 このモードはデフォルトでは無効になっており、DRBD設定ファイルで明示的に有効にする必要があります。
特定のリソースに対して有効にする方法については、 デュアルプライマリモードを有効にする を参照してください。
2.3. レプリケーションのモード
DRBDは3種類のレプリケーションモードをサポートしています。
非同期レプリケーションプロトコルプライマリノードでのディスクへの書き込みは、自機のディスクに書き込んだ上でレプリケーションパケットを自機のTCP送信バッファに送った時点で、完了したと判断されます。システムクラッシュなどの強制的なフェイルオーバが起こると、データを紛失する可能性があります。クラッシュが原因となったフェイルオーバが起こった場合、待機系ノードのデータは整合性があると判断されますが、クラッシュ直前のアップデート内容が反映されない可能性があります。プロトコルAは、遠隔地へのレプリケーションに最も適しています。 DRBD Proxyと組み合わせて使用すると、効果的なディザスタリカバリソリューションとなります。詳しくは DRBD Proxyによる遠距離レプリケーション を参照ください。
メモリ同期(半非同期)レプリケーションプロトコル。プライマリノードでのディスクへの書き込みは、自機のディスクに書き込んだ上でレプリケーションパケットが他機に届いた時点で、完了したと判断されます。通常、システムクラッシュなどの強制的なフェイルオーバでのデータ紛失は起こりません。しかし、両ノードに同時に電源障害が起こり、プライマリノードのストレージに復旧不可能な障害が起きると、プライマリ側にのみ書き込まれたデータを失う可能性があります。
同期レプリケーションプロトコルプライマリノードでのディスクへの書き込みは、両ノードのディスクへの書き込みが終わった時点で完了したと判断されます。このため、どちらかのノードでデータを失っても、系全体としてのデータ紛失には直結しません。当然ながら、このプロトコルを採用した場合であっても、両ノードまたはそのストレージサブシステムに復旧できない障害が同時に起こると、データは失われます。
このような特質にもとづき、もっとも一般的に使われているプロトコルはCです。
レプリケーションプロトコルを選択するときに考慮しなければならない要因が2つあります。 データ保護 と レイテンシ遅延 です。一方で、レプリケーションプロトコルの選択は スループット にはほとんど影響しません。
レプリケーションプロトコルの設定例については、 リソースの設定 を参照してください。
2.4. 2重以上の冗長性
DRBD supports replicating data to up to 32 nodes simultaneously. In practice, 3-, 4-, or 5-way redundancy is usually sufficient. Beyond that, other factors become the leading cause of downtime.
2.5. リソースの自動プロモーション
DRBD automatically promotes a resource to the primary role when one of its volumes is mounted or opened for writing. As soon as all volumes are unmounted or closed, the role of the resource changes back to secondary. This behavior is controlled by the auto-promote option, which is enabled by default.
Automatic promotion will only succeed if the cluster state allows it (that is, if an explicit drbdadm primary command would succeed). Otherwise, mounting or opening the device will fail.
2.6. 複数の転送プロトコル
DRBDは複数のネットワークプロトコルに対応しています。現在、TCPとRDMAの2つのトランスポートに対応しています。各トランスポートの実装はOSのカーネルモジュールを使用しています。
2.6.1. TCPトランスポート
DRBDのパッケージファイルには drbd_trasport_tcp.ko が含まれ、これによって実装されています。 その名の通り、TCP/IPプロトコルを使ってマシン間のデータ転送を行います。
DRBDのレプリケーションおよび同期フレームワークのソケットレイヤーは複数のトランスポートプロトコルに対応しています。
標準的かつDRBDのデフォルトのプロトコルです。IPv4が有効なすべてのシステムで利用できます。
レプリケーションと同期用のTCPソケットの設定においては、IPv6もネットワークプロトコルとして使用できます。アドレシング方法が違うだけで、動作上もパフォーマンス上もIPv4と変わりはありません。
SDPは、InfiniBandなどのRDMAに対応するBSD形式ソケットです。SDPは多くのディストリビューションでOFEDスタックの一部として利用されていましたが、現在は 非推奨 です。SDPはIPv4形式のアドレシングに使用しますインフィニバンドを内部接続に利用すると、SDPによる高スループット、低レイテンシのDRBDレプリケーションネットワークを実現することができます。
スーパーソケットはTCP/IPスタック部分と置き換え可能なソケット実装で、モノリシック、高効率、RDMA対応などの特徴を持っています。きわめてレイテンシが低いレプリケーションを実現できるプロトコルとして、DRBDはSuperSocketsをサポートしています。現在のところ、SuperSocketsはDolphin Interconnect Solutionsが販売するハードウェアの上でのみ利用できます。
2.6.2. RDMAトランスポート
DRBD バージョン 9.2.0 以降、 drbd_transport_rdma カーネルモジュールがオープンソースコードとして利用可能になりました。
LINBIT の tar archived DRBD releases page または DRBD GitHub repository からオープンソースコードをダウンロードできます。
あるいは、LINBIT の顧客であれば、 drbd_transport_rdma.ko カーネルモジュールが LINBIT の顧客ソフトウェアリポジトリで利用できます。
このトランスポートはverbs/RDMA APIを使ってInfiniBand HCAsやiWARPが使えるNIC、またはRoCEが使えるNICでデータ転送をします。TCP/IPで使用するBSDソケットAPIと比較して、verbs/RDMA APIでは非常に低いCPU負荷でデータ転送が行えます。
TCPトランスポートのCPUロード/メモリ帯域が制約要因であれば、高い転送率が可能となります。 適切なハードウェアでRDMAトランスポートを使用すれば高い転送率を実現することができます。
転送プロトコルはリソースのコネクションごとに設定することができます。詳細は トランスポートプロトコルの設定 を参照ください。
2.7. 複数の path
DRBDは接続ごとに複数のパスを設定することができます。TCP転送では、接続ごとに通常1つのパスしか使用されませんが、 TCPロードバランシング機能 を設定している場合は複数のパスを利用できます。一方、RDMA転送では、1つの接続の複数のパスでネットワークトラフィックのバランスを取ることができます。詳細については、 複数の経路の設定 を参照してください。
2.8. 効率的なデータ同期
同期ならびに再同期は、レプリケーションとは区別されます。レプリケーションは、プライマリノードでのデータの書き込みに伴って実施されますが、同期はこれとは無関係です。同期はデバイス全体の状態に関わる機能です。
プライマリノードのダウン、セカンダリノードのダウン、レプリケーション用ネットワークのリンク中断など、さまざまな理由によりレプリケーションが一時中断した場合、同期が必要になります。DRBDの同期は、もともとの書き込み順序ではなくリニアに書き込むロジックを採用しているため、効率的です。
-
何度も書き込みが行われたブロックの場合でも、同期は1回の書き込みですみます。このため、同期は高速です。
-
ディスク上のブロックレイアウトを考慮して、わずかなシークですむよう、同期は最適化されています。
-
同期実行中は、スタンバイノードの一部のデータブロックの内容は古く、残りは最新の状態に更新されています。この状態のデータは inconsistent (不一致)と呼びます。
DRBDでは、同期はバックグラウンドで実行されるので、アクティブノードのサービスは同期によって中断されることはありません。
| 重要:データに不一致箇所が残っているノードは、多くの場合サービスに利用できません。このため、不一致である時間を可能な限り短縮することが求められます。そのため、DRBDは同期直前のLVMスナップショットを自動で作成するLVM統合機能を実装しています。これは同期中であっても対向ノードと consistent (一致する)一致するコピーを保証します。この機能の詳細については DRBD同期中の自動LVMスナップショットの使用 をご参照ください。 |
2.8.1. 可変レート同期
可変レート同期(8.4以降のデフォルト)の場合、DRBDは同期のネットワーク上で利用可能な帯域幅を検出し、それと、フォアグランドのアプリケーションI/Oからの入力とを比較する、完全自動制御ループに基づいて、最適な同期レートを選択します。
可変レート同期に関する設定の詳細については、 可変同期速度設定 を参照してください。
2.8.2. 固定レート同期
固定レート同期の場合、同期ホストに対して送信される1秒あたりのデータ量( 同期速度 )には設定可能な静的な上限があります。この上限に基づき、同期に必要な時間は、次の簡単な式で予測できます。

tsync は同期所要時間の予測値です。 D は同期が必要なデータ量で、リンクが途絶えていた間にアプリケーションによって更新されたデータ量です。 R は設定ファイルに指定した同期速度です。ただし実際の同期速度はネットワークやI/Oサブシステムの性能による制約を受けます。
固定レート同期に関する設定の詳細については 同期速度の設定 を参照してください。
2.8.3. チェックサムベース同期
DRBDの同期アルゴリズムは、データダイジェスト(チェックサム)を使うことによりさらに効率化されています。チェックサムベースの同期を行うことで、より効率的に同期対象ブロックの書き換えが行われます。DRBDは同期を行う前にブロックを 読み込み ディスク上のコンテンツのハッシュを計算します。このハッシュと、相手ノードの同じセクタのハッシュを比較して、値が同じであれば、そのブロックを同期での書き換え対象から外します。これにより、DRBDが切断モードから復旧し再同期するときなど、同期時間が劇的に削減されます。
同期に関する設定の詳細は チェックサムベース同期の設定 をご参照ください。
2.9. レプリケーションの中断
DRBDが正しく設定されていれば、DRBDはレプリケーションネットワークが輻輳していることを検出することが可能です。その場合にはレプリケーションを 中断 します。この時、プライマリノードはセカンダリとの通信を切断するので一時的に同期しない状態になりますが、セカンダリでは整合性のとれたコピーを保持しています。帯域幅が確保されると、自動で同期が再開し、バックグラウンド同期が行われます。
レプリケーションの中断は、データセンタやクラウドインスタンス間との共有接続で遠隔地レプリケーションを行うような、可変帯域幅での接続の場合に通常利用されます。
輻輳のポリシーとレプリケーションの停止についてほ詳細は 輻輳ポリシーと中断したレプリケーションの構成 をご参照ください。
2.10. オンライン照合
オンライン照合機能を使うと、2ノードのデータの整合性を、ブロックごとに効率的な方法で確認できます。
ここで 効率的 というのはネットワーク帯域幅を効率的に利用することを意味しています。照合によって冗長性が損なわれることはありません。しかしオンライン照合はCPU使用率やシステム負荷を高めます。この意味では、オンライン照合はリソースを必要とします。
一方のノード( 照合ソース )で、低レベルストレージデバイスのブロックごとのダイジェストを計算します。DRBDはダイジェストを他方のノード( 照合ターゲット )に転送し、そこでローカルの対応するブロックのダイジェストと照合します。ダイジェストが一致しないブロックはout-of-syncとマークされ、後で同期が行われます。DRBDが転送するのはダイジェストであって、ブロックのデータそのものではありません。このため、オンライン照合はネットワーク帯域幅をきわめて効率的に活用します。
このプロセスは、照合対象のDRBDリソースを利用したまま実行できます。これが オンライン の由来です。照合によるパフォーマンス低下は避けられませんが、照合およびその後の同期作業全体を通じてサービスの停止やシステム全体を停止する必要はありません。
オンライン照合は、週または月に1回程度の頻度でcronデーモンから実行するのが妥当です。オンライン照合機能を有効にして実行する方法や、これを自動化する方法については、 オンラインデバイス照合の使用 をご参照ください。
2.11. レプリケーション用トラフィックの整合性チェック
DRBDは、MD5、SHA-1またはCRD-32Cなどの暗号手法にもとづきノード間のメッセージの整合性チェックができます。
DRBD自身はメッセージダイジェストアルゴリズムは 備えていません 。Linuxカーネルの暗号APIが提供する機能を単に利用するだけです。したがって、カーネルが備えるアルゴリズムであれば、どのようなものでも利用可能です。
本機能を有効にすると、レプリケート対象のすべてのデータブロックごとのメッセージダイジェストが計算されます。レプリケート先のDRBDは、レプリケーション用パケットの照合にこのメッセージダイジェストを活用します。 データの照合が失敗したら、レプリケート先のDRBDは、失敗したブロックに関するパケットの再送を求めます。 この機能を使うことで、データの損失を起こす可能性がある次のようなさまざまな状況への備えが強化され、DRBDによるレプリーションが保護されます。
-
送信側ノードのメインメモリとネットワークインタフェースの間で生じたビット単位エラー(ビット反転)。 この種のエラーは、多くのシステムにおいてTCPレベルのチェックサムでは検出できません。
-
受信側ノードのネットワークインタフェースとメインメモリの間で生じたビット反転。 TCPチェックサムが役に立たないのは前項と同じです。
-
何らかのリソース競合やネットワークインタフェースまたはそのドライバのバグなどによって生じたデータの損傷。
-
ノード間のネットワークコンポーネントが再編成されるときなどに生じるビット反転やデータ損傷。 このエラーの可能性は、ノード間をネットワークケーブルで直結しなかった場合に考慮する必要があります。
レプリケーショントラフィックの整合性チェックを有効にする方法については、 レプリケーショントラフィックの整合性チェックを設定 をご参照ください。
2.12. スプリットブレインの通知と自動修復
クラスタノード間のすべての通信が一時的に中断され、クラスタ管理ソフトウェアまたは人為的な操作ミスによって両方のノードが プライマリ になった場合に、スプリットブレインの状態に陥ります。それぞれのノードでデータの書き換えが行われることが可能になってしまうため、この状態はきわめて危険です。つまり、2つの分岐したデータセットが作られてしまう軽視できない状況に陥る可能性が高くなります。
クラスタのスプリットブレインは、Pacemaker などが管理するホスト間の通信がすべて途絶えたときに生じます。これとDRBDのスプリットブレインは区別して考える必要があります。このため、本書では次のような記載方法を使うことにします。
-
スプリットブレイン は、DRBDのスプリットブレインと表記します。
-
クラスタノード間のすべての通信の断絶のことを クラスタ・パーティション と表記します。
スプリットブレインに陥ったことを検出すると、DRBDは電子メールまたは他の方法によって管理者に自動的に通知できます。この機能を有効にする方法については スプリットブレインの通知 をご参照ください。
スプリットブレインへの望ましい対処方法は、 手動回復 を実施した後、根本原因を取り除くことです。しかし、ときにはこのプロセスを自動化する方がいい場合もあります。自動化のために、DRBDは以下のいくつかのアルゴリズムを提供します。
-
「若い」プライマリ側の変更を切り捨てる方法 ネットワークの接続が回復してスプリットブレインを検出すると、DRBDは 直近で プライマリに切り替わったノードのデータを切り捨てます。
-
「古い」プライマリ側の変更を切り捨てる方法 DRBDは 先に プライマリに切り替わったノードの変更を切り捨てます。
-
変更が少ないプライマリ側の変更を切り捨てる方法 DRBDは2つのノードでどちらが変更が少ないかを調べて、少ない方のノードの すべて を切り捨てます。
-
片ノードに変更がなかった場合の正常回復 もし片ノードにスプリットブレインの間にまったく変更がなかった場合、DRBDは正常に回復し、修復したと判断します。しかし、こういった状況はほとんど考えられません。仮にリードオンリーでファイルシステムをマウントしただけでも、デバイスへの書き換えが起きるためです。
自動修復機能を使うべきかどうかの判断は、個々のアプリケーションに強く依存します。データベースをレプリケーションしている場合を例とすると、変更量が少ないノードのデータを切り捨てるアプローチは、ある種のWebアプリケーションの場合には適しているかもしれません。一方で、金融関連のデータベースアプリケーションでは、 いかなる 変更でも自動的に切り捨てることは受け入れがたく、いかなるスプリットブレインの場合でも手動回復が望ましいでしょう。スプリットブレイン自動修復機能を使う場合、アプリケーションの特性を十分に考慮してください。
DRBDのスプリットブレイン自動修復機能を設定する方法については、 スプリットブレインからの自動復旧ポリシー を参照してください。
2.13. ディスクフラッシュのサポート
ローカルディスクやRAID論理ディスクでライトキャッシュが有効な場合、キャッシュにデータが記録された時点でデバイスへの書き込みが完了したと判断されます。このモードは一般にライトバックモードと呼ばれます。このような機能がない場合の書き込みはライトスルーモードです。ライトバックモードで運用中に電源障害が起きると、最後に書き込まれたデータはディスクにコミットされず、データを紛失する可能性があります。
これを解消するために、DRBDはディスクフラッシュを使用しています。ディスクフラッシュとは、関連するデータが安定した(不揮発性の)ストレージに確保された時点で完了する書き込み操作のことです。つまり、データがディスクに書き込まれたときにのみ完了し、キャッシュではなくディスクに書き込まれたことを意味します。DRBDは、複製されたデータセットとメタデータの両方に対して書き込み操作にディスクフラッシュを使用します。実際には、DRBDは、 アクティビティログ の更新や暗黙の書き込み後書き込み依存関係の強制など、必要と判断される状況で書き込みキャッシュを迂回します。これにより、停電の際でも追加の信頼性が得られます。
しかしDRBDがディスクフラッシュを活用できるのは、直下のディスクデバイスがこの機能をサポートしている場合に限られることに注意してください。最近のカーネルは、ほとんどのSCSIおよびSATAデバイスに対するフラッシュをサポートしています。LinuxソフトウェアRAID (md)は、直下のデバイスがサポートする場合に限り、RAID-1に対してフラッシュをサポートします。デバイスマッパ(LVM2、dm-raid、マルチパス)もフラッシュをサポートしています。
電池でバックアップされた書き込みキャッシュ(BBWC)は、電池からの給電による不揮発性ストレージです。このようなデバイスは、電源障害から回復したときに中断していたディスクへの書き込みをディスクにフラッシュできます。このため、キャッシュへの書き込みは、事実上安定したストレージへの書き込みと同等とみなせます。この種のデバイスが使える場合、DRBDの書き込みパフォーマンスを向上させるためにフラッシュを無効に設定するのがよいかもしれません。詳細は 下位デバイスのフラッシュを無効にする をご参照ください。
2.14. Trim/Discardのサポート
Trim と Discard は、ある範囲のデータ領域が既に使用済みで不要になって[2]、他のデータ領域として再利用してよいことをストレージに伝えるコマンドで、どちらも同じ意味を持ちます。これらは、フラッシュストレージで使用されている機能です。フラッシュストレージ(SSD、FusionIOカードなど)では上書きが困難であり、通常は消去してから新しいデータを書き込む必要があります(これにより多少のレイテンシが発生します)。詳細は wikipedia page を参照ください。
DRBDは8.4.3から trim/discard をサポートしています。設定や有効化を行う必要はありません。DRBDはローカル(下位の)ストレージシステムがそれらのコマンドをサポートしていることを検出すると、自動的に利用します。
その効果の例をあげると、大部分または全てのストレージ領域が無効になったとDRBDに伝えることで(DRBDはこれをすべての接続しているノードにリレーします)、比較的最近のmkfs.ext4であれば、初期同期時間を数TBのボリュームでも数秒から数分ほどに短縮することができます。
その後そのノードに接続する後続のリソースは Trim/Discard 要求ではなく、フル同期を行います。カーネルバージョンやファイルシステムによっては fstrim が効果を持つことがあります。
| ストレージ自体が Trim/Discard をサポートしていなくても、LVMのシンプロビジョニングボリュームなどの仮想ブロックデバイスでも同様の機能を提供しています。 |
2.15. ディスクエラー処理ストラテジー
どちらかのノードのDRBD下位ブロックデバイスがI/Oエラーを返したときに、DRBDがそのエラーを上位レイヤ(多くの場合ファイルシステム)に伝えるかどうかを制御できます。
pass_onを設定すると、下位レベルのエラーをDRBDはそのまま上位レイヤに伝えます。したがって、そのようなエラーへの対応(ファイルシステムをリードオンリーでマウントしなおすなど)は上位レイヤに任されます。このモードはサービスの継続性を損ねることがあるので、多くの場合推奨できない設定だといえます。
detach を設定すると、最初の下位レイヤでのI/Oエラーに対して、DRBDは自動的にそのレイヤを切り離します。上位レイヤにI/Oエラーは伝えられず、該当ブロックのデータはネットワーク越しに対向ノードに書き込まれます。その後DRBDはディスクレスモードと呼ばれる状態になり、すべてのI/Oは対向ノードに対して読み込んだり、書き込むようになります。このモードでは、パフォーマンスは犠牲になりますが、サービスは途切れることなく継続できます。また、都合のいい任意の時点でサービスを対向ノードに移動させることができます。
I/Oエラー処理方針を設定する方法については I/Oエラー処理方針の設定 を参照してください。
2.16. 無効データの処理ストラテジー
DRBDはデータの inconsistent(不整合状態) と outdated(無効状態) を区別します。不整合とは、いかなる方法でもアクセスできずしたがって利用できないデータ状態です。たとえば、進行中の同期先のデータが不整合データの例です。この場合、ノードのデータは部分的に古く、部分的に新しくなっており、ノード間の同期は不可能になります。下位デバイスの中にファイルシステムが入っていたら、このファイルシステムは、マウントはもちろんチェックも実行できません。
無効データは、セカンダリノード上のデータで、整合状態にあるもののプライマリ側と同期していない状態のデータをさします。一時的か永続的かを問わず、レプリケーションリンクが途切れたときに、この状態が生じます。リンクが切れている状態でのセカンダリ側の無効データは、クリーンではあるものの、対向ノードのデータ更新が反映されず古いデータ状態になっている可能性があります。サービスが無効データを使ってしまうことを防止するために、DRBDは無効データを プライマリに切り替える ことを許可しません。
DRBDにはネットワークの中断時にセカンダリノードのデータを無効に設定するためのインタフェースがあります。DRBDは無効データをアプリケーションが使ってしまうことを防止するために、このノードがプライマリになることを拒絶します。 本機能の完全は実装は、DRBDレプリケーションリンクから独立した通信経路を使用する Pacemakerクラスタ管理フレームワーク 用になされていますが、しかしこのAPIは汎用的なので、他のクラスタ管理アプリケーションでも容易に本機能を利用できます。
レプリケーションリンクが復活すると、無効に設定されたリソースの無効フラグは自動的にクリアされます。そして バックグラウンド同期 が実行されます。
2.17. 3ノードレプリケーション
| この機能はDRBDバージョン8.3.0以上で使用可能ですが、DRBDバージョン9.xでは単一階層で複数ノードが使用可能のため非推奨です。詳細は ネットワークコネクションの定義 をご参照ください。 |
3ノードレプリケーションとは、2ノードクラスタに3番目のノードを追加してDRBDでレプリケーションするものです。この方法は、バックアップやディザスタリカバリのために使われます。 このタイプの構成では一般的に DRBD Proxyによる遠距離レプリケーション の内容も関係します。
3ノードレプリケーション既存のDRBDリソースの上にもうひとつのDRBDリソースを スタック(積み重ね) することによって実現されます。次の図を参照してください。

下位リソースのレプリケーションには同期モード(DRBDプロトコルC)を使いますが、上位リソースは非同期レプリケーション(DRBDプロトコルA)で動作させます。
3ノードレプリケーションは、常時実行することも、オンデマンドで実行することもできます。常時レプリケーションでは、クラスタ側のデータが更新されると、ただちに3番目のノードにもレプリケートされます。オンデマンドレプリケーションでは、クラスタシステムとバックアップサイトの通信はふだんは停止しておき、cronなどによって定期的に夜間などに同期をはかります。
2.18. DRBD Proxyによる遠距離レプリケーション
DRBDの プロトコルA は非同期モードです。しかし、ソケットの出力バッファが一杯になると(drbd.conf マニュアルページの sndbuf-size を参照ください)、アプリケーションからの書き込みはブロックされてしまいます。帯域幅が狭いネットワークを通じて書き込みデータが対向ノードに送られるまで、そのデータを書き込んだアプリケーションは待たなければなりません。
平均的な書き込み帯域幅は、利用可能なネットワークの帯域幅によって制約されます。ソケットの出力バッファに収まるデータ量までのバースト的な書き込みは、問題なく処理されます。
オプション製品のDRBD Proxyのバッファリング機構を使って、この制約を緩和できます。DRBDプライマリノードからの書き込みデータは、DRBD Proxyのバッファに格納されます。DRBD Proxyのバッファサイズは、アドレス可能空間や搭載メモリの範囲内で自由に設定できます
データ圧縮を行うように設定することも可能です。圧縮と伸長(解凍)は、応答時間をわずかに増やしてしまいます。しかしネットワークの帯域幅が制約要因になっているのなら、転送時間の短縮効果は、圧縮と伸長(解凍)によるオーバヘッドを打ち消します。
圧縮伸長(解凍)機能は複数CPUによるSMPシステムを想定して実装され、複数CPUコアをうまく活用できます。
多くの場合、ブロックI/Oデータの圧縮率は高く、帯域幅の利用効率は向上します。このため、DRBD Proxyを使うことによって、DRBDプロトコルBまたはCを使うことも現実的なものとなります。
DRBD Proxyの設定については DRBD Proxyの使用 を参照ください。
| DRBD ProxyはオープンソースライセンスによらないDRBDプロダクトファミリの製品になります。評価や購入については [email protected] へご連絡ください。 |
2.19. トラック輸送によるレプリケーション
トラック輸送(またはディスク輸送)によるレプリケーションは、ストレージメディアを遠隔サイトに物理的に輸送することによるレプリケーションです。以下の制約がある場合に、この方法はとくに有効です。
-
合計のレプリケート対象データ領域がかなり大きい(数百GB以上)
-
予想されるレプリケートするデータの変更レートがあまり大きくない
-
利用可能なサイト間のネットワーク帯域幅が限られている
このような状況にある場合、トラック輸送を使わなければ、きわめて長期間(数日から数週間またはそれ以上)の初期同期が必要になってしまいます。トラック輸送でデータを遠隔サイトに輸送する場合、初期同期時間を劇的に短縮できます。詳細は トラックベースのレプリケーションの使用 を参照ください。
2.20. 動的対向ノード
| この記述方法はDRBDバージョン8.3.2以上で使用できます。 |
DRBDのやや特殊な使用方法に 動的対向ノード があります。動的対向ノードを設定すると、DRBDの対向同士は(通常設定の)特定のホスト名を持つノードには接続せず、いくつかのホスト間を動的に選択して接続するする事ができます。この設定において、DRBDは対向ノードをホスト名ではなくIPアドレスで識別します。
動的対向ノードの設定については 2セットのSANベースPacemakerクラスタ間をDRBDでレプリケート を参照ください。
2.21. データ再配置(ストレージの水平スケール)
例えば、会社のポリシーで3重の冗長化が要求される場合、少なくとも3台のサーバが必要になります。
しかし、データ量が増えてくると、サーバ追加の必要性に迫られます。その際には、また新たに3台のサーバを購入する必要はなく、1つのノードだけを追加をしてデータを 再配置 することができます。

上の図では、3ノードの各々に25TiBのボリュームがある合計75TiBの状態から、4ノードで合計100TiBの状態にしています。
これらはDRBD9ではオンラインで行うことができます。実際の手順については データ再配置 ご覧ください。
2.22. DRBDクライアント
DRBDの複数の対向ノード機能に、 DRBDクライアント などの新しいユースケースが追加されました。
基本的にDRBD バックエンド は3〜4、またはそれ以上(冗長化の要件に応じて)で構成できます。しかしDRBD9はそれ以上でも接続することができます。なお1つのビットマップslot[3]が ディスクレスプライマリ ( DRBDクライアント )用に予約されます。
プライマリの DRBDクライアント で実行されるすべての書き込み要求は、ストレージを備えたすべてのノードに送られます。読み込み要求は、サーバーノードの1つにのみ送られます。 DRBDクライアント は、使用可能なすべてのサーバーノードに均等に読み読み要求を送ります。
詳細は 永続的なディスクレスノード を参照ください。
2.23. DRBD クォーラム
DRBDクォーラムは、高可用性クラスターにおいてスプリットブレイン状況やデータの乖離を避けるのに役立つ機能です。DRBDクォーラムを使用することで、フェンシングやSTONITHソリューションに頼る必要はありませんが、必要に応じてこれらを使用することもできます。DRBDクォーラムには少なくとも3つのノードが必要ですが、アービトレータとして機能する第三のノードはディスクレスであることができます。アービトレータノードは、クラスター内のディスクフルストレージノードと同じハードウェア仕様を持つ必要はありません。例えば、Raspberry Piのような低消費電力のシングルボードコンピュータでさえ十分な場合があります。
DRBD クォーラムの背後にある機能コンセプトは、クラスターノードが、自身を含む、通信可能なデータセットの DRBD 実行中ノード数が、クォーラムオプションを有効にした際に指定した要件を満たす場合にのみ、DRBD レプリケーションされたデータセットを変更できるということです。ほとんどの構成では、これはノード数の過半数になります。運行中のデータセットの総ノード数の半分よりも大きい数を過半数とします。指定されたパーティション内のノードのうち、そのノード自体を含む半数以上にネットワークアクセス権限を持つノードにのみデータ書き込みを許可することで、DRBDクォーラム機能は、データセットの発散を引き起こす状況を回避できるようにします。
ただし、DRBDプライマリノードがデータセットに書き込むことができるためには、3ノードクラスターで常に2つ以上の稼働ノードが必要というわけではありません。例外もあります。たとえば、二次ノードをすべて正常に切断すると、DRBDはそれらがクラスターを離れる際にデータを古いものとしてマークします。このようにして、単一のDRBDプライマリノードがデータを書き込み続けても安全であると “判断” できるのです。この状況は、たとえばクラスター内のノードでシステムメンテナンスを実行している間などに発生する可能性があります。この方法により、アプリケーションやサービスの停止時間を引き起こさずに、クラスター内のノードを維持することができます。
DRBDのクォーラムを使用することは、Pacemakerクラスターの実行と互換性があります。Pacemakerは、DRBDリソースのマスタースコアを通じて、クォーラムまたはクォーラム喪失について通知を受けます。
DRBDのクォーラム機能に関連する構成オプションや動作にはさまざまな選択肢があります。たとえば、クラスターでクォーラムを定義する方法や、ノードがクォーラムを喪失した際にDRBDが取る可能性のあるアクションなどがあります。これに関する情報については、 クォーラム設定 セクションを参照してください。
2.23.1. クォーラムタイブレーカー
| クォーラムタイブレーカー機能は、DRBDバージョン9.0.18以降で使用できます。 |
2つのノードクラスタの基本的な問題は、それらが接続性を失うと同時に2つのパーティションを持ち、それらのどちらもクォーラムを持たず、その結果クラスタサービスが停止することです。この問題は、クォーラムタイブレーカーとして機能する3つ目のディスクレスノードをクラスターに追加することで軽減できます。
詳細は タイブレーカーとしてのディスクレスノードを使用 を参照ください。
2.24. Resync-after
DRBD は必要なすべての再同期操作を並行して実行するため、ノードはできるだけ早く最新のデータと再統合されます。これは、下位ディスクごとに 1 つの DRBD リソースがある場合にうまく機能します。
しかし、DRBD リソースが物理ディスクを共有している場合 (または単一のリソースが複数のボリュームにまたがっている場合)、これらのリソース (またはボリューム) を並行して再同期すると、非線形のアクセス パターンが発生します。ハードディスクは、線形アクセスパターンではるかに優れたパフォーマンスを発揮します。このような場合、DRBD リソース構成ファイルの disk セクション内で resync-after キーワードを使用して、再同期をシリアル化できます。
例としては こちら を参照ください。
2.25. フェールオーバークラスター
多くのシナリオでは、DRBD をフェールオーバークラスターのリソースマネージャーと組み合わせると便利です。DRBD は、DRBD Reactor やそのプロモータープラグイン (Pacemaker) などのクラスターリソースマネージャー (CRM) と統合して、フェイルオーバークラスターを作成できます。
DRBD Reactor は、DRBD イベントを監視して対応するオープンソースツールです。そのプロモータープラグインは、systemd ユニット ファイルまたは OCF リソースエージェントを使用してサービスを管理します。DRBD Reactor は DRBD のクラスタ通信のみに依存しているため、独自の通信の設定は必要ありません。
DRBD Reactor では、監視している DRBD リソースでクォーラムが有効になっている必要があるため、フェイルオーバクラスターには少なくとも 3 つのノードが必要です。制限は、コロケーションされたサービスに対してのみサービスの順序をサポートすることです。その利点の 1 つは、一時的なネットワーク障害の後にクラスターを完全に自動回復できることです。これは、その単純さと相まって、推奨されるフェールオーバークラスターマネージャーになります。さらに、DRBD Reactor は、3 つ以上のノード (クォーラム用) のデプロイメントで STONITH や冗長ネットワークを必要としないため、クラウドへの展開に完全に適しています。
Pacemaker は、高可用性クラスター向けの最も長く利用されているオープンソースクラスターのリソースマネージャーです。独自の通信レイヤー (Corosync) が必要であり、さまざまなシナリオに対処するには STONITH が必要です。STONITH には専用のハードウェアが必要な場合があり、サービス障害の影響範囲が広がる可能性があります。Pacemaker はおそらく、リソースの場所と順序の制約を表現するための最も柔軟なシステムを備えています。ただし、この柔軟性により、セットアップが複雑になる可能性があります。
さらに、Linux 用 SIOS LifeKeeper、Linux 用 HPE Serviceguard、Veritas Cluster Server など、DRBD と連携するフェイルオーバクラスターの独自のソリューションもあります。
DRBDのコンパイル、インストールおよび設定
3. コンパイル済みDRBDバイナリパッケージのインストール
3.1. LINBIT 提供パッケージ
DRBDプロジェクトのスポンサー企業であるLINBITは、商用サポートの顧客向けにバイナリパッケージを提供しています。これらのパッケージはリポジトリやパッケージマネージャーのコマンド(例: apt, dnf)を通じて利用可能であり、適切な場合はLINBITのDockerレジストリを通じても利用できます。これらのソースからのパッケージやイメージは「公式」ビルドと見なされています。
これらのビルドは次のディストリビューションで入手できます。
-
Red Hat Enterprise Linux (RHEL), versions 7, 8 and 9
-
SUSE Linux Enterprise Server (SLES), versions 12 and 15
-
Debian GNU/Linux, 9 (stretch), 10 (buster), and 11 (bullseye)
-
Ubuntu Server Edition LTS 18.04 (Bionic Beaver), LTS 20.04 (Focal Fossa), and LTS 22.04 (Jammy Jellyfish)
-
Oracle Linux (OL), versions 8 and 9
特定の配布情報に署名されたDRBDカーネルモジュールの詳細な情報については、 セキュアブートのための LINBIT カーネルモジュール署名 セクションを参照してください。
他のディストリビューションのビルドも用意していますが、十分なテストは経ていません。
LINBIT社では、新規のDRBDソースのリリースと並行してバイナリビルドをリリースしています。
SLES、RHEL、AlmaLinuxなどのRPMベースのシステムでのパッケージのインストールは、単純に dnf install (新規インストール用)または dnf update (アップグレード用)を使用することで行われます。
DEBベースのシステム(Debian GNU/Linux、Ubuntu)では、 drbd-utils および drbd-module-`uname -r` パッケージは apt install を使用してインストールされます。
3.1.1. ノードを登録し、パッケージリポジトリを構成するためのLINBITヘルパースクリプトの使用
LINBITのお客様であれば、LINBITのカスタマーリポジトリから必要なDRBDおよび依存関係をインストールすることができます。これらのリポジトリにアクセスするには、LINBITのシステムで設定されており、 LINBIT Customer Portal にアクセスできる必要があります。もしLINBITのシステムで設定されていない場合や評価アカウントをご希望の場合は、[email protected] に連絡してください。
ノードを登録するためのLINBIT Customer Portalの使用
LINBITの顧客ポータルへのアクセスが可能になったら、LINBITのPythonヘルパースクリプトを使用してクラスターノードを登録し、リポジトリへのアクセスを設定することができます。このスクリプトの詳細については、顧客ポータルの Register Nodes セクションをご覧ください。
LINBIT Manage Nodes ヘルパースクリプトのダウンロードおよび実行
LINBITヘルパースクリプトをダウンロードして実行し、ノードを登録してLINBITリポジトリへのアクセスを構成するためには、すべてのノードで次のコマンドを1つずつ入力してください。
# curl -O https://my.linbit.com/linbit-manage-node.py # chmod +x ./linbit-manage-node.py # ./linbit-manage-node.py
| スクリプトは管理者権限で実行する必要があります。 |
linbit-manage-node.py を実行する際に no python interpreter found :-( というエラーメッセージが表示された場合、Python 3をインストールするために、RPMベースのディストリビューションでは dnf -y install python3 と入力し、DEBベースのディストリビューションでは apt -y install python3 と入力してください。
|
スクリプトは、あなたにLINBITカスタマーポータルのユーザー名とパスワードを入力するように促します。資格情報を検証した後、スクリプトは、あなたのアカウントに関連付けられているクラスターとノード(すでに登録されている場合)のリストを表示します。
登録情報とリポジトリ設定をファイルに保存します。
ノードの登録情報を保存するために、ヘルパースクリプトが登録データをJSONファイルに書き込むことを求めるときには、書き込みを確認してください。
Writing registration data: --> Write to file (/var/lib/drbd-support/registration.json)? [y/N]
LINBITリポジトリの構成をノード上のファイルに保存するには、ヘルパースクリプトがファイルの linbit.repo への書き込みを促すときに、その書き込みを確認してください。
LINBIT リポジトリへのアクセスを有効にする
LINBITのノード管理ヘルパースクリプトを使用してノードを登録し、クラスターに参加させた後、スクリプトはLINBITリポジトリのメニューを表示します。
DRBDやその依存関係、関連パッケージをインストールするためには、 drbd-9 リポジトリを有効にしてください。
drbd-9 リポジトリには最新のDRBD 9バージョンが含まれています。また、LINSTOR®、DRBD Reactor、LINSTOR GUI、OCFリソースエージェントなど、他のLINBITソフトウェアパッケージも含まれています。
|
LINBITのパブリックキーをインストールし、LINBITリポジトリを検証する
LINBITリポジトリを有効にした後、選択を確認してから、LINBITの公開鍵をキーリングにインストールし、リポジトリの構成ファイルを書き込むことについて*yes*と回答することを忘れないでください。
スクリプトが終了する前に、異なるユースケースに応じてインストールできるさまざまなパッケージを提案するメッセージが表示されます。
LINBITリポジトリの検証
LINBITの管理ノード補助スクリプトが完了した後は、パッケージマネージャーのパッケージメタデータを更新した後に、 dnf info または apt info コマンドを使用して、LINBITリポジトリが有効になっているかどうかを確認できます。
RPM ベースのシステムでは、次のコマンドを入力してください。
# dnf --refresh info drbd-utils
DEB ベースのシステムでは、次のコマンドを入力してください:
# apt update && apt info drbd-utils
パッケージマネージャの info コマンドからの出力には、パッケージマネージャがLINBITリポジトリからパッケージ情報を取得していることが表示されるはずです。
Red HatやAlmaLinuxのリポジトリからパッケージを除外する
RPMベースのLinuxディストリビューションを使用している場合は、DRBDをインストールする前に、LINBITリポジトリからのみDRBDおよび関連パッケージを取得してください。これを行うためには、LINBITの顧客リポジトリのパッケージと重複するRPMベースのディストリビューションのリポジトリから特定のパッケージを除外する必要があります。
以下のコマンドは、リポジトリ構成ディレクトリ内のすべてのファイルにおいて、有効なリポジトリ行の後に「exclude」行を挿入します。ただし、LINBITリポジトリファイルを除きます。
RPMベースのディストリビューションで、有効化されているリポジトリから関連するDRBDパッケージを除外するには、以下のコマンドを入力してください:
# RPM_REPOS="`ls /etc/yum.repos.d/*.repo|grep -v linbit`" # PKGS="drbd kmod-drbd" # for file in $RPM_REPOS; do sed -i "/^enabled[ =]*1/a exclude=$PKGS" $file; done
DRBDをインストールするために、ヘルパースクリプトの提案するパッケージマネージャーのコマンドを使用します。
DRBDをインストールするには、LINBITのヘルパースクリプトが完了する前に表示されたパッケージマネージャーのコマンドを使用することができます。該当するコマンドは、この行の後に表示されました:
If you don't intend to run an SDS satellite or controller, a useful set is: [...]
|
スクリプトが完了した後でヘルパースクリプトの提案されたアクションを参照する必要がある場合は、 # ./linbit-manage-node.py --hints |
DEBベースのシステムでは、事前にコンパイルされたDRBDカーネルモジュールパッケージである drbd-module-$(uname -r) 、またはカーネルモジュールのソースバージョンである drbd-dkms をインストールすることができます。どちらか一方のパッケージをインストールしてくださいが、両方をインストールしないでください。
|
3.1.2. セキュアブートのための LINBIT カーネルモジュール署名
LINBIT は、ほとんどのカーネルモジュールオブジェクトファイルを署名します。次の表に、各ディストリビューションごとの署名開始バージョンを示します。
| ディストリビューション | モジュール署名が導入されたDRBDリリース |
|---|---|
RHEL7 |
8.4.12/9.0.25/9.1.0 |
RHEL8 |
9.0.25/9.1.0 |
RHEL9+ |
全ての利用可能なバージョン |
SLES15 |
9.0.31/9.1.4 |
Debian |
9.0.30/9.1.3 |
Ubuntu |
9.0.30/9.1.3 |
Oracle Linux |
9.1.17/9.2.6 |
公開署名鍵は rpm パッケージに含まれ、 /etc/pki/linbit/SECURE-BOOT-KEY-linbit.com.der にインストールされます。次の方法で登録できます。
# mokutil --import /etc/pki/linbit/SECURE-BOOT-KEY-linbit.com.der input password: input password again:
パスワードは自由に選択できます。再起動後、キーが実際にMOKリストに登録されるときに使用されます。
3.2. LINBIT 提供 Docker イメージ
LINBITは商用サポートカスタマー向けにDockerレポジトリを提供します。レポジトリはホスト名 ‘drbd.io’ 経由でアクセスします。
| The LINBIT container image repository (https://drbd.io) is only available to LINBIT customers or through LINBIT customer trial accounts. Contact LINBIT for information on pricing or to begin a trial. Alternatively, you may use LINSTOR SDS’ upstream project named Piraeus, without being a LINBIT customer. |
イメージを取得する前に、レジストリにログインする必要があります。
# docker login drbd.io
ログインに成功するとイメージを取得できます。ログインしてテストするには以下のコマンド実行してください。
# docker pull drbd.io/drbd-utils # docker run -it --rm drbd.io/drbd-utils # press CTRL-D to exit
3.3. ディストリビューション提供パッケージ
コンパイル済みバイナリパッケージを含め、いくつかのディストリビューションでDRBDが配布されています。これらのパッケージに対するサポートは、それぞれのディストリビュータが提供します。リリースサイクルは、DRBDソースのリリースより遅れる場合があります。
3.3.1. SUSE Linux Enterprise Server
SUSE Linux Enterprise Server (SLES) High Availability Extension (HAE) includes DRBD.
SLESの場合、DRBDは通常はYaST2のソフトウェアインストールコンポーネントによりインストールされます。これは High Availabilityパッケージセレクションに同梱されています。
コマンドラインを使用してインストールする場合は、次のコマンドを実行します。
# yast -i drbd
または
# zypper install drbd
3.3.2. CentOS
CentOSのリリース5からDRBD 8が含まれています。DRBD 9はEPEL等から探してください。
DRBDは yum でインストールします。この際には、正しいリポジトリが有効である必要があります。
# yum install drbd kmod-drbd
3.3.3. Ubuntu Linux
LINBITはUbuntu LTS用にPPAリポジトリを提供しています。 https://launchpad.net/~linbit/`archive/ubuntu/linbit-drbd9-stack. 詳細は以下をご確認ください。 Adding Launchpad PPA Repositories
# apt install drbd-utils drbd-dkms
3.4. ソースからパッケージをコンパイル
github で git tags によって生成されたリリースはある時点での git レポジトリのスナップショットです。これらはマニュアルページや configure スクリプト、あるいはその他の生成されるファイルが不足しているかもしれません。tarball からビルドするなら、 こちら を使用してください。
すべてのプロジェクトは標準のビルドスクリプト (eg, Makefile, configure) を含みます。ディストリビューション毎に固有の情報をメンテナンスすることは手間がかかり、また歴史的にすぐに最新でなくなってしまいました。標準的な方法でソフトウェアをビルドする方法を知らない場合は、LINBITによって供給されるパッケージを使ってください。
4. ソースコードからのDRBDのビルドおよびインストール
4.1. DRBDのソースコードをダウンロードする
現在のDRBDリリースと過去のリリースのソースtarファイルは、 https://pkg.linbit.com/ からダウンロード可能です。ソースtarファイルは通常、drbd-x.y.z.tar.gz という名前が付けられています。例えば、drbd-utils-x.y.z.tar.gz のように、x、y、z はメジャー番号、マイナー番号、バグ修正リリース番号を表します。
DRBDの圧縮されたソースアーカイブは、サイズが半メガバイト未満です。tarファイルをダウンロードした後は、tar -xzf コマンドを使用してその内容を展開して、現在の作業ディレクトリにダウンロードすることができます。
組織的な目的で、通常ソースコードを保管するディレクトリ(たとえば /usr/src や /usr/local/src など)に DRBD を展開してください。このガイドの例では /usr/src を前提としています。
4.2. 公開されているDRBDソースリポジトリからソースを取得する
DRBDのソースコードは公開されたGitリポジトリに保管されています。このリポジトリは https://github.com/LINBIT からオンラインで閲覧できます。DRBDソフトウェアは以下のプロジェクトから構成されています。
-
DRBDカーネルモジュール
-
DRBDユーティリティ
ソースコードは、Gitリポジトリをクローンするか、リリース用のtarファイルをダウンロードして取得できます。展開されたソースtarファイルと同じリリースのGitチェックアウトとの間には、わずかな違いが2つ存在します:
-
Gitのチェックアウトには
debian/サブディレクトリが含まれていますが、ソースtarファイルには含まれていません。これは、Debianのメンテナーからの要求によるもので、彼らは元のアップストリームtarファイルに独自のDebianビルド設定を追加することを好むためです。 -
ソースtarファイルには、事前に処理されたmanページが含まれていますが、Gitのチェックアウトには含まれていません。そのため、GitのチェックアウトからDRBDをビルドする場合は、manページをビルドするための完全なDocbookツールチェーンが必要ですが、ソースtarファイルからビルドする際にはその必要はありません。
4.2.1. DRBDカーネルモジュール
リポジトリから特定のDRBDリリースをチェックアウトするには、まずDRBDリポジトリを「クローン」する必要があります。
git clone --recursive https://github.com/LINBIT/drbd.git
このコマンドは、drbd という名前のGitチェックアウトサブディレクトリを作成します。特定のDRBDリリース(ここでは9.2.3)に相当するソースコードの状態に移動するには、以下のコマンドを入力してください。
$ cd drbd $ git checkout drbd-9.2.3 $ git submodule update
4.3. ソースコードからDRBDをビルドする
DRBDおよび関連ユーティリティのソースコードリポジトリをローカルホストにクローンした後、そのソースコードからDRBDをビルドする作業に進むことができます。
4.3.1. ビルドの前提条件の確認
ソースコードからDRBDをビルドする前に、ビルドホストは以下の前提条件を満たす必要があります。
-
必要なものは、
make、gcc、glibcの開発用ライブラリ、そしてflexスキャナージェネレーターのインストールです。モジュールをコンパイルするために使用する gccが、実行しているカーネルをビルドする際に使用したgccと同じであることを確認すべきです。システムに複数のgccのバージョンがある場合、DRBDのビルドシステムには特定のgccバージョンを選択する 機能が含まれています。 -
Gitのチェックアウトから直接ビルドする場合は、GNU Autoconfも必要です。ただし、tarファイルからビルドする場合は、この要件は必要ありません。
-
もしディストリビューションが提供している標準のカーネルを使用している場合は、対応するカーネルヘッダーパッケージをインストールする必要があります。これらは一般的に
kernel-devel、kernel-headers、linux-headersなどの名前が付けられています。この場合、 カーネルソースツリーの準備 をスキップして、 DRBDのユーザースペースユーティリティ構築ツリーの準備 に続けることができます。 -
もし標準のディストリビューションのカーネルを使っていない場合(つまり、システムがソースからカスタム設定で構築されたカーネルを実行している場合)、カーネルのソースファイルがインストールされている必要があります。
RPM ベースのシステムでは、これらのパッケージは kernel-source-version.rpmのような名前で呼ばれますが、これはkernel-version.src.rpmと間違えやすいです。前者が DRBD をビルドするために正しいパッケージです。
“Vanilla” kernel tar files from the https://kernel.org/ archive are simply named linux-version.tar.bz2 and should be unpacked in /usr/src/linux-version, with the symlink /usr/src/linux pointing to that directory.
この場合、カーネルソース(ヘッダーではなく)に対して DRBD を構築する際には、 カーネルソースツリーの準備 を続行する必要があります。
4.3.2. カーネルソースツリーの準備
DRBDを構築するために、まずは展開されたカーネルソースが格納されているディレクトリに入る必要があります。通常、それは /usr/src/linux-version 、あるいは単純に /usr/src/linux という名前のシンボリックリンクです。
# cd /usr/src/linux
次のステップは推奨されていますが、厳密に必要というわけではありません。この手順を実行する前に、既存の .config ファイルを安全な場所にコピーすることを忘れないでください。この手順は、以前のビルドや設定実行からの残留物を取り除き、カーネルソースツリーを元の状態に戻すものです。
# make mrproper
今、現在実行中のカーネル構成をカーネルソースツリーに「クローン」する時間です。これを行うためのいくつかの可能なオプションがあります:
-
最近の多くのカーネルビルドは、現在実行中の設定を圧縮形式で
/procファイルシステム経由でエクスポートしており、そこからコピーすることができます。
# zcat /proc/config.gz > .config
-
SUSEのカーネルMakefileには、
cloneconfigターゲットが含まれているため、そのようなシステムでは次のようにコマンドを実行できます。
# make cloneconfig
-
一部のインストールでは、カーネル設定のコピーを
/bootに保存しており、それによって以下の操作が可能になります。
# cp /boot/config-$(uname -r).config
-
最終的に、現在実行中のカーネルをビルドする際に使用された
.configファイルのバックアップコピーを簡単に使用できます。
4.3.3. DRBDのユーザースペースユーティリティ構築ツリーの準備
DRBDのユーザースペースのコンパイルを行う際には、まず付属の「configure」スクリプトを使用してソースツリーを構成する必要があります。
Gitのチェックアウトからビルドする際には、configure スクリプトがまだ存在しません。チェックアウトのトップディレクトリから単純に autoconf と入力することで、それを作成する必要があります。
|
configure スクリプトを --help オプションで呼び出すと、サポートされているオプションの完全なリストが表示されます。以下の表は、最も重要なオプションをまとめたものです。
| オプション | 説明 | デフォルト | 備考 |
|---|---|---|---|
–prefix |
インストールディレクトリのプレフィックス |
|
これは、ローカルにインストールされるパッケージ化されていないソフトウェアに対して、Filesystem Hierarchy Standardの互換性を維持するためのデフォルト値です。パッケージングにおいては、通常 |
–localstatedir |
ローカルステートディレクトリ |
|
デフォルトの |
–sysconfdir |
システム設定ディレクトリ |
|
デフォルトの |
–with-udev |
リソース名のような名前のシンボリックリンクを取得するために、ルールファイルを |
yes |
|
–with-heartbeat |
DRBD Heartbeat 連携をビルドします |
yes |
DRBDの Heartbeat v1 リソースエージェントまたは |
–with-pacemaker |
DRBD Pacemaker 連携をビルドします |
yes |
Pacemaker クラスタリソースマネージャーを使用する予定がない場合は、このオプションを無効にできます。 |
–with-rgmanager |
DRBD Red Hat Cluster Suite 連携をビルドします |
no |
Red Hat Cluster Suite のクラスタリソースマネージャーである |
–with-bashcompletion |
|
yes |
bash 以外のシェルを使用している場合、または |
–with-initscripttype |
使用している init システムのタイプ |
auto |
インストールする init スクリプトのタイプ(sysv、systemd、またはその両方)。 |
–enable-spec |
ディストリビューション固有の RPM spec ファイルを作成します |
no |
パッケージ作成者専用:ディストリビューションに適合した RPM spec ファイルを作成したい場合に、このオプションを使用できます。DRBDのユーザースペースRPMパッケージをビルドする も参照してください。 |
ほとんどのユーザーは、次の設定オプションを希望するでしょう。
$ ./configure --prefix=/usr --localstatedir=/var --sysconfdir=/etc
configureスクリプトは、DRBDビルドをディストリビューション固有の必要に合わせて調整します。これは、どのディストリビューションが呼び出されているかを自動検出し、それに応じてデフォルトを設定することで行われます。デフォルトを上書きする際は慎重に行ってください。
The configure script creates a log file, config.log, in the directory where it was invoked. When reporting build issues on the LINBIT Community Forum, it is usually wise to either attach a copy of that file or point others to a location from where it can be viewed or downloaded.
4.3.4. DRBDユーザースペースユーティリティの構築
DRBDのユーザースペースユーティリティを構築するには、Gitのチェックアウトのトップまたは展開されたtarファイルから次のコマンドを実行してください。
$ make $ sudo make install
これにより、管理ユーティリティ(drbdadm、drbdsetup、drbdmeta)がビルドされ、適切な場所にインストールされます。 構成ステージ で選択された他の --with オプションに基づいて、他のアプリケーションと統合するスクリプトもインストールされます。
4.3.5. DRBD カーネルモジュールのコンパイル
The DRBD kernel module source always targets the newest upstream kernel. Backward compatibility with older kernels is handled automatically by a Coccinelle-based compat system that generates the necessary patches at build time.
Building from a release tarball
Release tar files ship pre-generated compat patches for common distribution kernels. In most cases, building is straightforward:
$ cd drbd-9.x.y $ make clean $ make
By default, this builds the module for the currently running kernel (using /lib/modules/$(uname -r)/build). To build against a different kernel, set KDIR:
$ make clean $ make KDIR=/path/to/kernel/headers/or/source
For kernels without pre-generated compat patches, the build automatically uses the LINBIT “spatch as a service” web service to generate them. If you do not have internet access, you will need a local Coccinelle installation.
Building from a Git-cloned repository
Building from a Git-cloned repository requires Coccinelle (spatch) for the compat system. Refer to the DRBD README for requirements and options.
$ cd drbd $ make clean $ make
4.4. DRBDのインストール
Provided your DRBD build completed successfully, you will be able to install DRBD by issuing the commands:
$ cd drbd && sudo make install && cd .. $ cd drbd-utils && sudo make install && cd ..
DRBDのユーザースペース管理ツール(drbdadm、drbdsetup、drbdmeta)は、通常 /sbin/ などの configure に渡された prefix パスにインストールされます。
カーネルをアップグレードする際には、新しいカーネルに合わせて、DRBDカーネルモジュールを再構築して再インストールする必要があります。
一部のディストリビューションでは、カーネルモジュールのソースディレクトリを登録しておくことで、必要に応じて再構築が行われます。例えば、Debianでは dkms(8) を参照してください。
一方で、DRBDのユーザースペースツールは、新しいDRBDバージョンにアップグレードする際には、再構築して再インストールするだけで済みます。新しいカーネルと新しいDRBDバージョンの両方にアップグレードする場合、両コンポーネントをアップグレードする必要があります。
4.5. DRBDのユーザースペースRPMパッケージをビルドする
DRBDビルドシステムには、DRBDのソースツリーから直接RPMパッケージをビルドする機能が含まれています。RPMをビルドする際には、make でビルドおよびインストールする場合と基本的に同様に ビルドの前提条件の確認 が適用されますが、もちろんRPMビルドツールも必要です。
もし、実行中のカーネルとプリコンパイル済ヘッダを使用せずにビルドする場合は、 カーネルソースツリーの準備 も参照してください。
ビルドシステムは、RPMをビルドするための2つのアプローチを提供しています。より簡単な方法は、単にトップレベルのMakefileで rpm ターゲットを呼び出すことです。
$ ./configure $ make rpm
このアプローチは、事前定義されたテンプレートから仕様ファイルを自動生成し、その仕様ファイルを使用してバイナリのRPMパッケージをビルドします。
make rpm のアプローチは、複数のRPMパッケージを生成します。
| パッケージ名 | 説明 | 依存関係 | 備考 |
|---|---|---|---|
drbd |
DRBDメタパッケージ |
他のすべての |
最上位の仮想パッケージ。これをインストールすると、他のすべてのユーザーランドパッケージが依存関係として導入されます。 |
drbd-utils |
バイナリ管理ユーティリティ |
DRBDを有効にしたホストには必須 |
|
drbd-udev |
udev統合機能 |
|
|
drbd-heartbeat |
DRBD Heartbeat統合スクリプト |
|
レガシーなv1形式のHeartbeatクラスターによるDRBD管理を可能にします |
drbd-pacemaker |
DRBD Pacemaker統合スクリプト |
|
PacemakerクラスターによるDRBD管理を可能にします |
drbd-rgmanager |
DRBD RedHat Cluster Suite統合スクリプト |
|
Red Hat Cluster Suiteのリソースマネージャーである |
drbd-bashcompletion |
プログラマブルなbash補完 |
|
|
もう一つの、柔軟なアプローチは、configure にスペックファイルを生成させ、必要な変更を加え、その後 rpmbuild コマンドを使用する方法です。
$ ./configure --enable-spec $ make tgz $ cp drbd*.tar.gz `rpm -E %sourcedir` $ rpmbuild -bb drbd.spec
RPMは、システムのRPM構成(またはあなたの個人の ~/.rpmmacros 構成)に応じて作成されます。
これらのパッケージを作成した後、システム内の他の任意のRPMパッケージと同様に、それらをインストール、アップグレード、アンインストールすることができます。
注意:どんなカーネルのアップグレードでも、新しいカーネルに合わせて新しい「kmod-drbd」パッケージを生成する必要があります。詳細は [s-kabi-warning] も参照してください。
一方、DRBDユーザーランドパッケージは、新しいDRBDバージョンにアップグレードする際にのみ再作成する必要があります。新しいカーネルと新しいDRBDバージョンの両方にアップグレードする場合は、両方のパッケージをアップグレードする必要があります。
4.6. Debianパッケージの作成について
DRBDのビルドシステムには、DRBDのソースツリーから直接Debianパッケージをビルドするための機能が含まれています。Debianパッケージをビルドする場合、make でビルドおよびインストールする場合と基本的に同じように ビルドの前提条件の確認 が適用されますが、Debianのパッケージングツールを含む dpkg-dev パッケージと、DRBDを非rootユーザーとしてビルドする場合には fakeroot も必要です(強く推奨)。全てのDRBDのサブプロジェクト(カーネルモジュールと drbd-utils )は、Debianパッケージのビルドをサポートしています。
もし、実行中のカーネルとプリコンパイル済ヘッダを使用せずにビルドする場合は、 カーネルソースツリーの準備 も参照してください。
DRBDのソースツリーには、Debianパッケージングに必要なファイルが含まれている`debian` サブディレクトリがあります。ただし、そのサブディレクトリはDRBDソースtarファイルには含まれていません。その代わりに、特定のDRBDリリースに関連付けられた「タグ」を使用して Gitをチェックアウトする 必要があります。
この手法でチェックアウトを作成した後、DRBDのDebianパッケージをビルドするために以下のコマンドを発行することができます。
$ dpkg-buildpackage -rfakeroot -b -uc
この(例えば)drbd-buildpackage の呼び出しは、非特権ユーザーによるバイナリのみのビルド( -b )を有効にし、変更ファイルのための暗号署名を無効にする(-uc)ために -rfakeroot が使われています。もちろん、他のビルドオプションを使用することも可能であり、詳細は dpkg-buildpackage のmanページを参照してください。
|
このビルドプロセスにより、以下のDebianパッケージが作成されます。
-
DRBDユーザースペースツールを含むパッケージは、
drbd-utils_x.y.z-ARCH.debという名前です。 -
module-assistantに適したモジュールソースパッケージで、drbd-module-source_x.y.z-BUILD_all.debという名前です。 -
dkmsに適したdkms用のパッケージであり、drbd-dkms_x.y.z-BUILD_all.debという名前のもの。
これらのパッケージを作成した後は、システム内の他のDebianパッケージと同様に、それらをインストール、アップグレード、アンインストールすることができます。
drbd-utils パッケージは、Debianの dpkg-reconfigure 機能をサポートしており、デフォルトで表示されるmanページのバージョンを切り替えるために使用することができます(8.3、8.4、または9.0)。
インストールされたモジュールのソースパッケージから実際のカーネルモジュールをビルドしてインストールすることは、Debianの module-assistant ツールを使用することで簡単に行うことができます。
# module-assistant auto-install drbd-module
上記のコマンドの省略形も使用することができます。
# m-a a-i drbd-module
新しいカーネルへのアップグレードでは、その新しいカーネルに合わせてカーネルモジュールを再構築する必要があります(前述のように module-assistant を使用して)。対照的に、drbd-utils および drbd-module-source パッケージは、新しいDRBDバージョンにアップグレードするときにのみ再作成する必要があります。新しいカーネルと新しいDRBDバージョンの両方にアップグレードする場合は、両方のパッケージをアップグレードする必要があります。
DRBD9からは、dkms(8) を利用してDRBDカーネルモジュールの自動更新が可能になりました。drbd-dkms Debianパッケージをインストールすれば、簡単に更新することができます。
DRBDの使い方
5. 一般的な管理作業
この章では一般的なオペレーションでの管理作業を説明します。トラブルシューティングについては扱いません。トラブルシューティングについては トラブルシューティングとエラーからの回復 を参照ください。
5.1. DRBDの設定
5.1.1. 下位レベルストレージの準備
DRBDをインストールしたら、両方のクラスタノードにほぼ同じ容量の記憶領域を用意する必要があります。これがDRBDリソースの 下位レベルデバイス になります。システムの任意のブロックデバイスを下位レベルデバイスとして使用できます。たとえば、次のようなものがあります。
-
ハードドライブのパーティション(または物理ハードドライブ全体)
-
ソフトウェアRAIDデバイス
-
LVM論理ボリュームまたはLinuxデバイスマッパインフラストラクチャによって構成されるその他のブロックデバイス
-
システム内のその他のブロックデバイス
リソースを スタッキング(積み重ね) することもできます。つまり、DRBDデバイスを他のDRBDデバイスの下位レベルのデバイスとして利用することができます。リソースの積み重ねにはいくつかの注意点があります。詳しくは スタックされた3ノード構成の作成 を参照ください。
| ループデバイスをDRBDの下位レベルデバイスとして使用することもできますが、デッドロックの問題があるためお勧めできません。 |
DRBDリソースを作成する前に、そのストレージ領域を空にしておく 必要はありません 。DRBDを使用して、非冗長のシングルサーバシステムから、2ノードのクラスタシステムを作成することは一般的なユースケースですが、いくつか重要な注意点があります。(その場合には DRBDメタデータ を参照ください)
本ガイドの説明は、次のようなとてもシンプルな構成を前提としています。
-
両方のホストには、
/dev/disk/by-id/ata-[some ID]という名前の空き(現在は未使用)パーティションがあります。 -
内部メタデータ を使用する。
5.1.2. ネットワーク構成の準備
必須要件ではありませんが、DRBDによるレプリケーションの実行には、専用接続を使用することをお勧めします。この書き込みには、ギガビットイーサネット同士をケーブルで直結した接続が最適です。DRBDをスイッチを介して使用する場合には、冗長コンポーネントと bonding ドライバ( active-backup モードで)の使用を推奨します。
一般に、ルータを介してDRBDレプリケーションを行うことはお勧めできません。スループットと待ち時間の両方に悪影響を及ぼし、パフォーマンスが大幅に低下します。
ローカルファイアウォールの要件として重要な点は、通常、DRBDは7788以上のTCPポートを使用し、それぞれのTCPリソースが個別のTCPポート上で待機するということです。DRBDは 2つ のTCP接続を使用します。これらの接続が許可されるようにファイアウォールを設定する必要があります。
SELinuxやAppArmorなどのMAC (Mandatory Access Control)スキーマが有効な場合は、ファイアウォール以外のセキュリティ要件も考慮する場合があります。DRBDが正しく機能するように、 必要に応じてローカルセキュリティポリシーを調整してください。
また、DRBDに使用するTCPポートを別のアプリケーションが使用していないことも確認してください。
DRBDのバージョン9.2.6以降、トラフィックの負荷分散のために複数のTCP接続ペアをサポートするDRBDリソースを設定することが可能です。詳細は ロードバランシング DRBD トラフック セクションを参照してください。
本ガイドの説明は、次のようなとてもシンプルな構成を前提としています。
-
2つのDRBDホストそれぞれに、現在使用されていないネットワークインタフェース
eth1が存在する(IPアドレスはそれぞれ10.1.1.31と10.1.1.32)。 -
どちらのホストでも他のサービスがTCPポート7788〜7799を使用していない。
-
ローカルファイアウォール設定は、これらのポートを介したホスト間のインバウンドとアウトバウンドの両方のTCP接続を許可する。
5.1.3. リソースの設定
DRBDのすべての機能は、設定ファイル /etc/drbd.conf で制御されます。通常、この設定ファイルは、次のような内容となっています。
include "/etc/drbd.d/global_common.conf"; include "/etc/drbd.d/*.res";
通例では、/etc/drbd.d/global_common.conf にはDRBD設定の global と common セクションが含まれます。また .res ファイルには各 リソース セクションが含まれます。
drbd.conf に include ステートメントを使用せずにすべての設定を記載することも可能です。しかし、設定の見やすさの観点から、複数のファイルに分割することをお勧めします。
いずれにしても drbd.conf や、その他の設定ファイルは、すべてのクラスタノードで 正確に同じ である必要があります。
DRBDのソースtarファイルの scripts サブディレクトリに、サンプル設定ファイルがあります。バイナリインストールパッケージの場合、サンプル設定ファイルは直接 /etc にインストールされるか、 /usr/share/doc/packages/drbd などのパッケージ固有の文書ディレクトリにインストールされます。
このセクションは、DRBDを稼働させるために理解しておく必要のある設定ファイルの項目についての説明です。設定ファイルの構文と内容の詳細については drbd.conf マニュアルページを参照ください。
設定例
本ガイドでの説明は、前章であげた例をもとにする最小限の構成を前提にしています。
/etc/drbd.d/global_common.conf)global {
usage-count yes;
}
common {
net {
protocol C;
}
}
/etc/drbd.d/r0.res)resource "r0" {
device minor 1;
disk "/dev/vg0/lv0";
meta-disk internal;
on "alice" {
node-id 0;
}
on "bob" {
node-id 1;
}
connection {
host "alice" address 10.1.1.31:7789;
host "bob" address 10.1.1.32:7789;
}
}
この設定の disk 値は、LVM論理ボリュームを使用します。DRBDリソースの下位層として、LVMやZFS論理ボリュームではなく物理ディスクを使用している場合は、バスベースの名前(例: /dev/sda2)ではなく、永続的なブロックデバイス名(/dev/disk/by-id/<disk-by-id>)を使用してディスクを参照してください。これにより、バスベースの名前の変更がDRBDリソースに影響を及ぼすのを防ぐことができます。特定のディスクのIDを確認するには、lsblk -o Name,UUID,WWN コマンドを実行してください。
|
この例では、DRBDが次のように設定されます。
-
DRBDの使用状況の統計をオプトインとして含める(
usage-count参照)。 -
特に他の指定がない限り完全に同期したレプリケーションを使用するようにリソースを設定する(プロトコルC)。
-
クラスタには2つのノード
aliceとbobがある。 -
r0`という任意の名前のリソースがあり、これはLVM論理ボリュームである/dev/vg0/lv0`を下位デバイスとして使用し、内部メタデータを用いるように構成されています。 -
リソースはネットワーク接続にTCPポート7789を使用し、それぞれIPアドレス10.1.1.31と10.1.1.32にバインドされる
-
上記の構成により、リソース内に番号 0 (
0) のボリュームが 1 つ暗黙的に作成されます。
次の例では、1つのリソース内で複数のボリュームを明示的に設定します。各ノードに同じLVMボリュームグループ vg0 が存在し、各ノードに指定された論理ボリュームが含まれていると仮定します。ノード bob の volume 1 設定内の disk の値に異なる論理ボリュームを指定することで、common configuration section で指定された volume 1 の値を上書きします。これにより、 /dev/vg0/lv1 ではなく /dev/vg0/lv2 が使用されます。
/etc/drbd.d/r0.res)resource "r0" {
volume 0 {
device minor 1;
disk "/dev/vg0/lv0";
meta-disk internal;
}
volume 1 {
device minor 2;
disk "/dev/vg0/lv1";
meta-disk internal;
}
on "alice" {
node-id 0;
}
on "bob" {
node-id 1;
volume 1 {
disk "/dev/vg0/lv2";
}
}
connection {
host "alice" address 10.1.1.31:7789;
host "bob" address 10.1.1.32:7789;
}
}
-
ホストセクション(’on’ キーワード)は、リソースレベルから volume セクションを継承します。それには volume 自体が含まれる場合があり、この値は継承された値よりも優先されます。
| ボリュームは既存のデバイスの動作中にも追加できます。 新しいDRBDボリュームを既存のボリュームグループへ追加する をご参照ください。 |
DRBD の古いリリースとの互換性のために、drbd-8.4 の構成ファイルもサポートします。
resource r0 {
on alice {
device /dev/drbd1;
disk /dev/vg0/lv0;
meta-disk internal;
address 10.1.1.31:7789;
}
on bob {
device /dev/drbd1;
disk /dev/vg0/lv0;
meta-disk internal;
address 10.1.1.32:7789;
}
-
キーワードを含まない文字列は、二重引用符
"なしで記述される場合があります。 -
古いバージョン (8.4) でデバイスを指定する方法は、
/dev/drbdXデバイスファイルの名前で指定することでした。 -
2 ノード構成は、drbdadm によって割り当てられたノード番号を使用します。
-
純粋な 2 ノード構成は暗黙的な connection を使用します。
global セクション
このセクションは設定の中で1回しか使用できません。通常この設定は /etc/drbd.d/global_common.conf ファイルに記述します。設定ファイルが1つの場合は、設定ファイルの一番上に記述します。このセクションで使用できるオプションはわずかですが、ほとんどのユーザーの場合、必要なのは次の1つだけです。
usage-countDRBDプロジェクトはさまざまなバージョンのDRBDの使用状況について統計を取ります。これは、システムに新規のDRBDバージョンがインストールされるたびに、HTTPサーバに接続することにより実行されます。これを無効にするには、 usage-count no; を指定します。デフォルトは usage-count ask; で、 DRBDをアップグレードするたびにプロンプトが表示されます。
DRBD’s usage statistics are, of course, publicly available: see https://usage.drbd.org.
common セクション
このセクションで、各リソースに継承される設定を簡単に定義できます。通常この設定は /etc/drbd.d/global_common.conf に指定します。ここで定義するオプションは、リソースごとに定義することもできます。
common セクションは必須ではありませんが、複数のリソースを使用する場合は、記述することを強くお勧めします。これにより、オプションを繰り返し使用することによって設定が複雑になることを回避できます。
上の例では net { protocol C; } が common セクションで指定されているため、設定されているすべてのリソース( r0 含む)がこのオプションを継承します。ただし、明示的に別の protocol オプションが指定されている場合は除きます。使用可能なその他の同期プロトコルについては、 レプリケーションのモード を参照してください。
resource セクション
各リソースの設定ファイルは、通常 /etc/drbd.d/resource.res という名前にします。定義するDRBDリソースは、設定ファイルでresource nameを指定して名前を付ける必要があります。通常は文字または数字、アンダースコアのみを使用します。他の文字を使用することも技術的には可能ですが、より具体的な resource:_peer/volume の構文が必要になった場合、うまくいかないでしょう。
各リソースには各クラスタノードに最低2つの on <host> サブセクションも必要です。その他すべての設定は common セクション(記述した場合)から継承されるか、DRBDのデフォルト設定から取得されます。
さらに、オプションの値が両方のホストで等しい場合は、直接 resource セクションで指定することができます。このため、設定例は次のように短くすることができます。
resource "r0" {
device minor 1;
disk "/dev/vg0/lv0";
meta-disk internal;
on "alice" {
address 10.1.1.31:7789;
}
on "bob" {
address 10.1.1.32:7789;
}
}
5.1.4. ネットワークコネクションの定義
現時点では、DRBD9の通信リンクはフルメッシュである必要があります。つまり、全リソース全ノードが他の全ノードに直接のコネクションを持っている必要があります(当然、自ノードに対しては不要です)。
ホスト2台のシンプルな構成の場合、使い勝手と後方互換性のため、drbdadm は(1つの)ネットワークコネクションを自身で挿入します。
The net effect of this is a quadratic number of network connections over hosts. For the “traditional” two nodes one connection is needed; for three hosts there are three node pairs; for four, six pairs; five hosts: 10 connections, and so on. For the maximum of 32 nodes there will be 496 host pairs to connect.

以下は3つのホストでの設定ファイルの例です。
resource r0 {
device minor 1;
disk "/dev/vg0/lv0";
meta-disk internal;
on alice {
address 10.1.1.31:7000;
node-id 0;
}
on bob {
address 10.1.1.32:7000;
node-id 1;
}
on charlie {
address 10.1.1.33:7000;
node-id 2;
}
connection-mesh {
hosts alice bob charlie;
}
}
サーバに十分なネットワークカードがあれば、サーバ間をクロスケーブルで直結できます。 1つ4ポートのイーサネットカードであれば、4ノードのフルメッシュにするために1つの管理インターフェースと3つの他サーバへの接続を行うことができます。
この場合には直接接続に異なるIPアドレスを指定することができます。
resource r0 {
...
connection {
host alice address 10.1.2.1:7010;
host bob address 10.1.2.2:7001;
}
connection {
host alice address 10.1.3.1:7020;
host charlie address 10.1.3.2:7002;
}
connection {
host bob address 10.1.4.1:7021;
host charlie address 10.1.4.2:7012;
}
}
メンテナンスとデバッグを容易にするために、エンドポイントごとに異なるポートを使用することをお勧めします。これにより tcpdump を実行するときにパケットをエンドポイントに簡単に関連付けることができます。以下の例では、2 つのサーバーを使用しています。4 ノードについては 4ノードでの構成例 を参照ください。
5.1.5. 複数の経路の設定
DRBD は、connection に複数の path セクションを使用することで、connection ごとに複数の path を構成できます。次の例を参照してください。
resource <resource> {
...
connection {
path {
host alpha address 192.168.41.1:7900;
host bravo address 192.168.41.2:7900;
}
path {
host alpha address 192.168.42.1:7900;
host bravo address 192.168.42.2:7900;
}
}
...
}
2 つのエンドポイントホスト名は connection の path 内で同じである必要があります。path は異なる IP(潜在的に異なるNIC)上にある場合もあれば、異なるポート上のみである場合もあります。
TCPトランスポートは1度に1つのパスを使用しますが、 ロードバランシング DRBD トラフック を参照してロードバランシングを設定している場合は除きます。バックグラウンドのTCP接続が切断されたり、タイムアウトが発生した場合、TCPトランスポートの実装は次のパスを介して接続を確立しようと試みます。ラウンドロビン方式ですべてのパスを試行し、接続が確立されるまで続けます。
RDMA トランスポートは、connection のすべての path を同時に使用し、path 間のネットワークトラフィックを均等に分散します。
5.1.6. トランスポートプロトコルの設定
DRBDは複数のネットワーク転送プロトコルに対応しています。 トランスポートプロトコルの設定はリソースの各コネクションごとに設定できます。
TCP/IP
TCPは、 DRBD複製トラフィックのデフォルトの転送手段です。リソース構成で transport オプションが指定されていない場合、各DRBDリソース接続はTCP転送を使用します。
resource <resource> {
net {
transport "tcp";
}
...
}
以下のオプションを指定することで、tcp トランスポートを構成できます。これらのオプションは、リソース構成の net セクションに指定することができます:sndbuf-size、rcvbuf-size、connect-int、socket-check-timeout、ping-timeout、timeout、 load-balance-paths、および tls 。それぞれのオプションについての詳細については、man drbd.conf-9.0 を参照してください。
ロードバランシング DRBD トラフック
| 現時点では、同じリソースでDRBD TCPロードバランシングとTLSトラフィックの暗号化機能を同時に使用することはできません。 |
デフォルトでは、TCPトランスポートは、DRBDリソースのピア間で接続パスを直列に(つまり、一度に1つずつ)確立します。DRBDバージョン9.2.6以降、オプション`load-balance-paths` を yes に設定することで、トランスポートをすべてのパスを並列に確立できます。また、ロードバランシングが構成されている場合、トランスポートは常に送信キューが最も短いパスに複製されたトラフィックを送信します。複数のパスが確立されている場合、受信側でデータが順番に到着しない可能性があります。DRBDトランスポートの実装は、受信したデータパケットを並べ替え、元の送信順序でデータをDRBDコアに提供します。
ロードバランシング機能を使用するには、drbd-utils のバージョン9.26.0以降が必要です。もしも旧バージョンの drbd-utils がインストールされている場合、ロードバランシングを設定したリソースに対して drbdadm コマンドを実行しようとすると、「bad parser」というエラーメッセージが表示される可能性があります。
|
drbd-lb-0 というDRBDリソースにロードバランシングが設定された例の構成は、次のようになります:
drbd-lb-0.resresource "drbd-lb-0"
{
[...]
net
{
load-balance-paths yes;
[...]
}
on "node-0"
{
volume 0
{
[...]
}
node-id 0;
}
on "node-1"
{
volume 0
{
[...]
}
node-id 1;
}
on "node-2"
{
volume 0
{
[...]
}
node-id 2;
}
connection
{
path
{
host "node-0" address ipv4 192.168.220.60:7900;
host "node-1" address ipv4 192.168.220.61:7900;
}
path
{
host "node-0" address ipv4 192.168.221.60:7900;
host "node-1" address ipv4 192.168.221.61:7900;
}
}
connection
{
path
{
host "node-0" address ipv4 192.168.220.60:7900;
host "node-2" address ipv4 192.168.220.62:7900;
}
path
{
host "node-0" address ipv4 192.168.221.60:7900;
host "node-2" address ipv4 192.168.221.62:7900;
}
}
connection
{
path
{
host "node-1" address ipv4 192.168.220.61:7900;
host "node-2" address ipv4 192.168.220.62:7900;
}
path
{
host "node-1" address ipv4 192.168.221.61:7900;
host "node-2" address ipv4 192.168.221.62:7900;
}
}
}
上記の構成では、3つのDRBD接続パスが表示されていますが、3ノードクラスターでは2つだけで十分です。例えば、上記の構成がノード node-0 上にある場合、node-1 と node-2 の間の接続は構成上不要です。node-1 上では、node-0 と node-2 の間の接続も不要であり、同様に、node-2 上の構成でも同様です。それでも、すべての可能な接続をリソースの構成に含めておくと便利です。これにより、クラスター内のすべてのノードで同じ構成ファイルを使用し、各ノードで構成を編集してカスタマイズする必要がなくなります。
|
TLSによるDRBD接続の保護
| 現時点では、同じリソースでDRBD TCPロードバランシングとTLSトラフィックの暗号化機能を同時に使用することはできません。 |
DRBDリソース構成ファイルに tls ネットオプションを追加することで、tcp 転送を介した認証された暗号化されたDRBD接続を有効にすることができます。
resource <resource> {
net {
tls yes;
}
...
}
DRBDは接続を確立する際に、ユーザースペースユーティリティ(tlshd、ktls-utils パッケージの一部)にソケットを一時的に渡します。tlshd は、/etc/tlshd.conf で設定されたキーを使用して認証と暗号化を設定します。
[authenticate.client] x509.certificate=/etc/tlshd.d/tls.crt x509.private_key=/etc/tlshd.d/tls.key x509.truststore=/etc/tlshd.d/ca.crt [authenticate.server] x509.certificate=/etc/tlshd.d/tls.crt x509.private_key=/etc/tlshd.d/tls.key x509.truststore=/etc/tlshd.d/ca.crt
RDMA
DRBDリソースの複製トラフィックをTCPではなくRDMAを使うように構成することができます。これは、DRBDリソースの設定で明示的に指定することで実現できます。
resource <resource> {
net {
transport "rdma";
}
...
}
rdma トランスポートを設定する際には、リソース構成の net セクションで以下のオプションを指定することができます: sndbuf-size, rcvbuf-size, max_buffers, connect-int, socket-check-timeout, ping-timeout, timeout。各オプションの詳細については、man drbd.conf-9.0 を参照してください。
rdma 輸送は零コピー受信輸送です。その影響の1つは、max_buffers 構成オプションを rcvbuf-size をすべて保持できる十分な大きさの値に設定する必要があるということです。
rcvbuf-size はバイト単位で設定されており、一方で max_buffers はページ単位で設定されています。最適なパフォーマンスを得るためには、 max_buffers は rcvbuf-size 全体と、常にバックエンドデバイスに送信されるデータ量を保持できるだけの大きさに設定する必要があります。
|
InfiniBandホストチャネルアダプタ(HCAs)を使用している場合、 rdma トランスポートとともにIP over InfiniBand(IPoIB)を構成する必要があります。 IPアドレスはデータ転送に使用されるわけではありませんが、接続を確立する際に適切なアダプタやポートを見つけるために使用されます。
|
sndbuf-size と rcvbuf-size の設定オプションは、接続が確立される時点でのみ考慮されます。接続が確立された時に値を変更することはできますが、その変更は接続が再確立された時にのみ反映されます。
|
5.1.7. リソースを初めて有効にする
すでに述べた手順に従って最初のリソース設定を完了したら、リソースを稼働させます。
両方のノードに対して、次の手順を行います。
さきほどの構成例( resource r0{ … } )では、 <resource> は r0 となります。
この手順は、最初にデバイスを作成するときにのみ必要です。これにより、DRBDのメタデータを初期化します。
# drbdadm create-md <resource> v09 Magic number not found Writing meta data... initialising activity log NOT initializing bitmap New drbd meta data block successfully created.
| メタデータに割り当てられるビットマップスロットの数はリソースのホストの数に依存します。 デフォルトではリソース設定のホストの数をカウントします。 メタデータの作成前にすべてのホストが指定されていれば、そのまま動作します。後から追加ノード用のビットマップを付け足すことも可能ですが、手動での作業が必要になります。 |
これにより、リソースとその下位デバイス(マルチボリュームリソースの場合は、すべてのデバイス)とを結びつけます。また、対向ノードのリソースと接続します。
# drbdadm up <resource>
drbdadm status でステータスを確認するstatus コマンドの出力は次のような情報を表示します。
# drbdadm status r0
r0 role:Secondary
disk:Inconsistent
bob role:Secondary
disk:Inconsistent
この時点では Inconsistent/Inconsistent のディスク状態になっているはずです。
|
これで、DRBDがディスクリソースとネットワークリソースに正しく割り当てられ、稼働できるようになりました。次に、どちらのノードをデバイスの初期同期のソースとして使用するか指定する必要があります。
5.1.8. デバイスの初期同期
DRBDを完全に機能させるには、さらに次の2つの手順が必要です。
新しく初期化した空のディスクを使用する場合は、任意のディスクを同期元にできます。いずれかのノードにすでに重要なデータが格納されている場合は、 十分注意して、必ず そのノードを同期元として選択してください。デバイスの初期同期の方向が誤っていると、データを失うおそれがあります。慎重に行ってください。
この手順は、最初のリソース設定の際に、同期ソースとして選択した1つのノードに対してのみ実行します。次のコマンドで実行します。
# drbdadm primary --force <resource>
このコマンドを指定すると、初期フル同期が開始します。 drbdadm status で同期の進行状況を監視できます。デバイスのサイズによっては、同期に時間がかかる場合があります。
この時点で、初期同期が完了していなくてもDRBDデバイスは完全に稼働します(ただし、パフォーマンスは多少低いです)。空のディスクから開始した場合は、デバイスにファイルシステムを作成してもかまいません。これを下位ブロックデバイスとして使用し、マウントして、アクセス可能なブロックデバイスとしてさまざまな操作を実行することができます。
リソースに対して一般的な管理タスクを行う場合は、 DRBDの使い方 に進んでください。
5.1.9. 初期同期のスキップ
DRBD リソースを最初から開始する場合(貴重なデータがない場合のみ)、次のコマンドシーケンスを使用して、最初の同期をスキップできます(デバイスにデータを保存する場合は実行しないでください)。
すべてのノードで次のコマンドを実行します。
# drbdadm create-md <res> # drbdadm up <res>
コマンド drbdadm status は、すべてのディスクを Inconsistent として表示するはずです。
次に1つのノードで次のコマンドを実行します。
# drbdadm new-current-uuid --clear-bitmap <resource>/<volume>
または
# drbdsetup new-current-uuid --clear-bitmap <minor>
その後 drbdadm status を実行すると、ディスクが UpToDate として表示されるようになります(下位デバイスが同期していない場合でも)。これでディスク上にファイルシステムを作成し、使用を開始できます。
| データを保存したい場合は使用しないでください。データが壊れます。 |
5.1.10. トラックベースのレプリケーションの使用
リモートノードに同期するデータを前もってロードし、デバイスの初期同期をスキップする場合は、次の手順を行います。
初期設定済みで プライマリ に昇格し、相手ノードとの接続を切断した状態のDRBDリソースが必要です。つまり、デバイスの設定が完了し、両方のノードに同一の drbd.conf のコピーが存在し 最初のリソース昇格 をローカルノードで実行するコマンドを発行した後、
-
ローカルノードで次のコマンドを実行します。
# drbdadm new-current-uuid --clear-bitmap <resource>/<volume>
または
# drbdsetup new-current-uuid --clear-bitmap <minor>
-
リソースのデータ およびそのメタデータ の正確に同一のコピーを作成します。 たとえば、ホットスワップ可能な RAID-1ドライブの一方を抜き取ります。この場合は、もちろん 新しいドライブをセットしてRAIDセットを再構築しておくべきでしょう。 抜き取ったドライブは、正確なコピーとして リモートサイトに移動できます。別の方法としては、ローカルのブロックデバイスがスナップショットコピーをサポートする場合 (LVMの上位でDRBDを使用する場合など)は、
ddを使用してスナップショットのビット単位のコピーを作ってもかまいません。 -
ローカルノードで次のコマンドを実行します。
# drbdadm new-current-uuid <resource>
または
drbdsetupコマンドを使用します。この2回目のコマンドには
--clear-bitmapがありません。 -
対向ホストの設置場所にコピーを物理的に移動します。
-
コピーをリモートノードに追加します。ここでも物理ディスクを接続するか、リモートノードの既存のストレージに移動したデータのビット単位のコピーを追加します。レプリケートしたデータだけでなく、関連するDRBDメタデータも必ず復元するかコピーしてください。そうでない場合、ディスクの移動を正しく行うことができません。
-
新しいノードでは、メタデータ中のノードIDを修正し、2つのノード間でピアノード情報を交換する必要があります。ノードIDをリソース
r0のボリューム0で2から1に変更する例を以下に示します。これはボリュームが未使用中のときに実行する必要があります。
最初の4行をあなたのニーズに合わせて編集する必要があります。Vはボリューム番号を示すリソース名です。NODE_FROMはデータの元となるノードのノードIDです。NODE_TOはデータがレプリケートされるノードのノードIDです。META_DATA_LOCATIONはメタデータの場所であり、内部か柔軟外部かのいずれかです。
V=r0/0 NODE_FROM=2 NODE_TO=1 META_DATA_LOCATION=internal drbdadm -- --force dump-md $V > /tmp/md_orig.txt sed -e "s/node-id $NODE_FROM/node-id $NODE_TO/" \ -e "s/^peer.$NODE_FROM. /peer-NEW /" \ -e "s/^peer.$NODE_TO. /peer[$NODE_FROM] /" \ -e "s/^peer-NEW /peer[$NODE_TO] /" \ < /tmp/md_orig.txt > /tmp/md.txt drbdmeta --force $(drbdadm sh-minor $V) v09 $(drbdadm sh-md-dev $V) $META_DATA_LOCATION restore-md /tmp/md.txt
バージョン 8.9.7 以前の drbdmeta 順不同の対向ノードセクションを扱えません。エディタを用いてブロックを交換する必要があります。
|
-
リモートノードで次のコマンドを実行します。
# drbdadm up <resource>
2つのホストを接続しても、デバイスのフル同期は開始されません。代わりに、 drbdadm --clear-bitmap new-current-uuid の呼び出し以降に変更されたブロックのみを対象とする自動同期が開始されます。
以降、データの変更が 全くない 場合でも、セカンダリで アクティビティログ を含む領域がロールバックされるため、同期が短時間行われることがあります。これは チェックサムベースの同期 を使用することで緩和されます。
この手順は、リソースが通常のDRBDリソースの場合でもスタックリソースの場合でも使用できます。スタックリソースの場合は、 -S または --stacked オプションを drbdadm に追加します。
5.1.11. 4ノードでの構成例
以下は4ノードクラスタの例です。
resource r0 {
device minor 0;
disk /dev/vg/r0;
meta-disk internal;
on store1 {
address 10.1.10.1:7100;
node-id 1;
}
on store2 {
address 10.1.10.2:7100;
node-id 2;
}
on store3 {
address 10.1.10.3:7100;
node-id 3;
}
on store4 {
address 10.1.10.4:7100;
node-id 4;
}
connection-mesh {
hosts store1 store2 store3 store4;
}
}
connection-mesh 設定を確認したい場合には drbdadm dump <resource> -v を実行します。
別の例として、4ノードに直接接続でフルメッシュにできるだけのインターフェースがある場合には、[4]インターフェースにIPアドレスを指定することができます。
resource r0 {
...
# store1 has crossover links like 10.99.1x.y
connection {
host store1 address 10.99.12.1 port 7012;
host store2 address 10.99.12.2 port 7021;
}
connection {
host store1 address 10.99.13.1 port 7013;
host store3 address 10.99.13.3 port 7031;
}
connection {
host store1 address 10.99.14.1 port 7014;
host store4 address 10.99.14.4 port 7041;
}
# store2 has crossover links like 10.99.2x.y
connection {
host store2 address 10.99.23.2 port 7023;
host store3 address 10.99.23.3 port 7032;
}
connection {
host store2 address 10.99.24.2 port 7024;
host store4 address 10.99.24.4 port 7042;
}
# store3 has crossover links like 10.99.3x.y
connection {
host store3 address 10.99.34.3 port 7034;
host store4 address 10.99.34.4 port 7043;
}
}
IPアドレスやポート番号の付け方には注意してください。別のリソースであれば同じIPアドレスを使用することができますが、 71xy、72xy のようにずらしてください。
5.2. DRBDのステータスを確認する
5.2.1. リアルタイムでのDRBDリソースの監視と操作
DRBDを操作し監視する便利な方法の1つは、DRBDmonユーティリティを使用する方法です。 DRBDmonは、drbd-utils パッケージに含 まれています。 このユーティリティを実行するには、drbd-utils パッケージがインストールされているノードで`drbdmon` と入力します。
DRBDmonはCLIベースですが、ウィンドウの概念に従っており、キーボードとマウスのナビゲーションをサポートしています。DRBDmonの異なる表示は、DRBDの状態やアクティビティの異なる側面を示します。たとえば、1つの表示では、現在のノード上のすべてのDRBD リソースとその状態がリストされます。別の表示では、選択されたリソースに対するピア接続とその状態がリストされます。他のDRBDコンポーネント用の表示もあります。
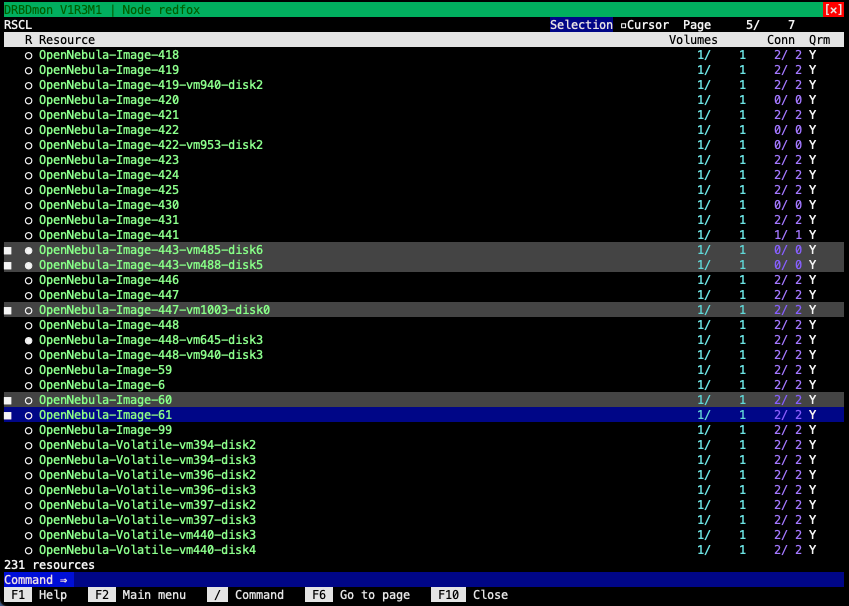
DRBDモニタ(DRBDmon)は、DRBDリソース、ボリューム、接続などの状態に関する情報を取得できるだけでなく、それらに対して操作 も行うことができます。DRBDmonには、ユーティリティ内にコンテキストに基づいたヘルプテキストがあり、ナビゲーションや使用方 法をサポートするために利用できます。DRBDmonは、CLIコマンドを入力することなく、状態情報を取得したり、操作を行ったりできるため、新しいDRBDユーザーにとって便利です。また、多数のDRBDリソースを持つクラスターで作業している経験豊富なDRBDユーザーにも役立つユーティリティです。
5.2.2. DRBD プロセスファイルを介したステータス情報の取得
In DRBD 9, /proc/drbd only shows version information. Per-resource status output has been removed. Use DRBD 管理ツールを使用したステータス情報の取得 or DRBDセットアップコマンドを使用してステータス情報を取得する instead.
|
/proc/drbd is a virtual file that was used extensively in DRBD 8.4 to display resource status. In DRBD 9, it only shows the DRBD module version and build information:
$ cat /proc/drbd version: 9.x.y (api:2/proto:118-124) GIT-hash: XXX
5.2.3. DRBD 管理ツールを使用したステータス情報の取得
一番シンプルなものとして、1つのリソースのステータスを表示します。
# drbdadm status home
home role:Secondary
disk:UpToDate
nina role:Secondary
disk:UpToDate
nino role:Secondary
disk:UpToDate
nono connection:Connecting
ここではリソース home がローカルと nina と nino にあり、 UpToDate で セカンダリ であることを示しています。つまり、3ノードが同じデータをストレージデバイスに持ち、現在はどのノードでもデバイスを使用していないという意味です。
ノード nono は接続していません。 Connecting のステータスになっています。詳細は コネクションステータス を参照してください。
drbdsetup に --verbose および/または --statistics の引数を付けると、より詳細な情報を得ることができます:
# drbdsetup status home --verbose --statistics
home node-id:1 role:Secondary suspended:no
write-ordering:none
volume:0 minor:0 disk:UpToDate
size:1048412 read:0 written:1048412 al-writes:0 bm-writes:48 upper-pending:0
lower-pending:0 al-suspended:no blocked:no
nina local:ipv4:10.9.9.111:7001 peer:ipv4:10.9.9.103:7010 node-id:0
connection:Connected role:Secondary
congested:no
volume:0 replication:Established disk:UpToDate resync-suspended:no
received:1048412 sent:0 out-of-sync:0 pending:0 unacked:0
nino local:ipv4:10.9.9.111:7021 peer:ipv4:10.9.9.129:7012 node-id:2
connection:Connected role:Secondary
congested:no
volume:0 replication:Established disk:UpToDate resync-suspended:no
received:0 sent:0 out-of-sync:0 pending:0 unacked:0
nono local:ipv4:10.9.9.111:7013 peer:ipv4:10.9.9.138:7031 node-id:3
connection:Connecting
この例では、ローカルノードについては多少異なりますが、このリソースで使用しているノードすべてを数行ごとにブロックで表示しています。以下で詳細を説明します。
各ブロックの最初の行は node-id です。(現在のリソースに対してのものです。ホストは異なるリソースには異なる node-id がつきます) また、 role (リソースのロール 参照)も表示されています。
The next important line begins with the volume specification; normally these are numbered starting by zero, but the configuration may specify other IDs as well. This line shows the replication state in the replication item (see 複製ステータス for details) and the remote disk state in disk (see ディスク状態). Then there’s a line for this volume giving a bit of statistics – data received, sent, out-of-sync, and so on. Please see パフォーマンス指標 and 接続情報データ for more information.
ローカルノードでは、最初の行はリソース名を表示します。この例では home です。最初の行には常にローカルノードが表示されますので、 Connection やアドレス情報は表示されません。
より詳細な情報については、 drbd.conf マニュアルページをご覧ください。
この例のブロックになっている他の4行は、すべての設定のあるDRBDデバイスごとになっており、最初にデバイスマイナー番号がついています。この場合にはデバイス /dev/drbd0 に対応して 0 です。
リソースごとの出力には様々なリソースに関する情報が含まれています。
5.2.4. DRBDセットアップコマンドを使用してステータス情報を取得する
| この機能はユーザスペースのDRBDが8.9.3より後のバージョンでのみ使用できます。 |
追加オプションと引数を指定してコマンド drbdsetup events2 を使用することは、 DRBD から情報を取得するための低レベルのメカニズムであり、監視などの自動ツールでの使用に適しています。
ワンショットモニタリング
一番シンプルな使用方法では、以下のように現在のステータスのみを表示します(端末上で実行した場合には色も付いています)。
# drbdsetup events2 --now r0
exists resource name:r0 role:Secondary suspended:no
exists connection name:r0 peer-node-id:1 conn-name:remote-host connection:Connected role:Secondary
exists device name:r0 volume:0 minor:7 disk:UpToDate
exists device name:r0 volume:1 minor:8 disk:UpToDate
exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:0
replication:Established peer-disk:UpToDate resync-suspended:no
exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:1
replication:Established peer-disk:UpToDate resync-suspended:no
exists -
リアルタイムモニタリング
”–now” を付けないで実行した場合には動作し続け、以下のように更新を続けます。
# drbdsetup events2 r0 ... change connection name:r0 peer-node-id:1 conn-name:remote-host connection:StandAlone change connection name:r0 peer-node-id:1 conn-name:remote-host connection:Unconnected change connection name:r0 peer-node-id:1 conn-name:remote-host connection:Connecting
そして監視用途に、”–statistics”という別の引数もあります。これはパフォーマンスその他のカウンタを作成するものです。
”drbdsetup” の詳細な出力(読みやすいように一部の行は改行しています)
# drbdsetup events2 --statistics --now r0
exists resource name:r0 role:Secondary suspended:no write-ordering:drain
exists connection name:r0 peer-node-id:1 conn-name:remote-host connection:Connected
role:Secondary congested:no
exists device name:r0 volume:0 minor:7 disk:UpToDate size:6291228 read:6397188
written:131844 al-writes:34 bm-writes:0 upper-pending:0 lower-pending:0
al-suspended:no blocked:no
exists device name:r0 volume:1 minor:8 disk:UpToDate size:104854364 read:5910680
written:6634548 al-writes:417 bm-writes:0 upper-pending:0 lower-pending:0
al-suspended:no blocked:no
exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:0
replication:Established peer-disk:UpToDate resync-suspended:no received:0
sent:131844 out-of-sync:0 pending:0 unacked:0
exists peer-device name:r0 peer-node-id:1 conn-name:remote-host volume:1
replication:Established peer-disk:UpToDate resync-suspended:no received:0
sent:6634548 out-of-sync:0 pending:0 unacked:0
exists -
”–timestamp” パラメータも便利な機能です。
5.2.5. コネクションステータス
リソースのディスク状態は drbdadm dstate コマンドを実行することで確認できます。
# drbdadm cstate <resource> Connected Connected StandAlone
確認したいのが1つのコネクションステータスだけの場合にはコネクション名を指定してください。
デフォルトでは設定ファイルに記載のある対向ノードのホスト名です。
# drbdadm cstate <resource>:<peer> Connected
リソースのコネクションステータスには次のようなものがあります。
ネットワーク構成は使用できません。リソースがまだ接続されていない、管理上の理由で切断している( drbdadm disconnect を使用)、認証の失敗またはスプリットブレインにより接続が解除された、のいずれかが考えられます。
切断中の一時的な状態です。次の状態は StandAlone です。
接続を試行する前の一時的な状態です。次に考えられる状態は、 Connecting です。
対向ノードとの通信のタイムアウト後の一時的な状態です。次の状態は Unconnected です。
対向ノードとの接続が失われた後の一時的な状態です。次の状態は Unconnected です。
対向ノードとの接続が失われた後の一時的な状態です。次の状態は Unconnected です。
対向ノードとの接続が失われた後の一時的な状態です。次の状態は Unconnected です。
一時的な状態です。対向ノードが接続を閉じています。次の状態は Unconnected です。
対向ノードがネットワーク上で可視になるまでノードが待機します。
DRBDの接続が確立され、データミラー化がアクティブになっています。これが正常な状態です。
5.2.6. 複製ステータス
各ボリュームは各接続ごとに複製ステータスを持ちます。可能な複製ステータスは以下になります。
ボリュームはこの接続を通して複製されていません。接続が Connected になっていません。す。次の状態は Unconnected です。
このボリュームへのすべての書き込みがオンラインで複製されています。これは通常の状態です。
管理者により開始されたフル同期が始まっています。次に考えられる状態は SyncSource または PausedSyncS です。
管理者により開始されたフル同期が始まっています。次の状態は WFSyncUUID です。
部分同期が始まっています。次に考えられる状態は SyncSource または PausedSyncS です。
部分同期が始まっています。次に考えられる状態は WFSyncUUID です。
同期が開始されるところです。次に考えられる状態は SyncTarget または PausedSyncT です。
現在、ローカルノードを同期元にして同期を実行中です。
現在、ローカルノードを同期先にして同期を実行中です。
ローカルノードは継続的な同期のソースですが、現在同期は一時停止しています。これは他の同期プロセスの完了を待っている依存 関係があるか、drbdadm pause-sync によって同期が手動で中断されたためかもしれません。
ローカルノードが進行中の同期の同期先ですが、現在は同期が一時停止しています。原因として、別の同期プロセスの完了との依存関係、または drbdadm pause-sync を使用して手動で同期が中断されたことが考えられます。
ローカルノードを照合元にして、オンラインデバイスの照合を実行中です。
現在、ローカルノードを照合先にして、オンラインデバイスの照合を実行中です。
リンクが負荷に対応できないので、データの複製が中断しました。このステータスは on-congestion オプションの設定で有効にできます( 輻輳ポリシーと中断したレプリケーションの構成 を参照)。
リンクが負荷に対応できないので、データの複製が対向ノードによって中断されました。このステータスは対向ノードの on-congestion オプション設定で有効にできます( 輻輳ポリシーと中断したレプリケーションの構成 を参照)。
5.2.7. リソースのロール
リソースのディスク状態は drbdadm dstate コマンドを実行することで確認できます。
# drbdadm role <resource> Primary
以下のいずれかのリソースのロールが表示されます。
The resource is currently in the primary role, and may be read from and written to. This role only occurs on one node, unless dual-primary mode is enabled.
The resource is currently in the secondary role. It normally receives updates from its peer (unless running in disconnected mode), but may neither be read from nor written to. This role can occur on more than one nodes.
リソースのロールが現在不明です。ローカルリソースロールがこの状態になることはありません。切断モードの場合に、対向ノードのリソースロールにのみ表示されます。
5.2.8. ディスク状態
リソースのディスク状態は drbdadm dstate コマンドを実行することで確認できます。
# drbdadm dstate <resource> UpToDate
ディスク状態は以下のいずれかです。
DRBDドライバにローカルブロックデバイスが割り当てられていません。原因として、リソースが下位デバイスに接続されなかった、 drbdadm detach を使用して手動でリソースを切り離した、または下位レベルのI/Oエラーにより自動的に切り離されたことが考えられます。
メタデータを読み取る際の一時的な状態として、「ディスクの状態、アタッチ」という用語が使われています。
切断され、進行中のIO処理が完了するのを待っている一時的な状態。
ローカルブロックデバイスがI/O障害を報告した後の一時的な状態です。次の状態は Diskless です。
すでに Connected のDRBDデバイスで attach が実行された場合の一時的状態です。
データが一致しません。新規リソースを作成した直後に(初期フル同期の前に)両方のノードがこの状態になります。また、同期中には片方のノード(同期先)がこの状態になります。
リソースデータは一致していますが、 無効 です。
ネットワーク接続を使用できない場合に、対向ノードディスクにこの状態が使用されます。
接続していない状態でノードのデータが一致しています。接続が確立すると、データが UpToDate か Outdated か判断されます。
データが一致していて最新の状態です。これが正常な状態です。
5.2.9. 接続情報データ
ネットワークファミリ、ローカルアドレス、対向ノードから接続を許可されたポートを表示します。
ネットワークファミリ、ローカルアドレス、接続に使用しているポートを表示します。
データのTCP送信バッファを80%より多く使用している場合にこのフラグがつきます。
5.2.10. パフォーマンス指標
コマンド drbdsetup status --verbose --statistics を使用して、パフォーマンス統計を表示できます。これは drbdsetup events2 --statistics でも利用できますが、変更ごとに changed イベントが発生するわけではありません。統計には、次のカウンターとゲージが含まれます。
ボリューム/デバイス単位:
ローカルディスクから読み取られたネットデータ (kibyte単位)。
ローカルのディスクに書き込んだ正味データ量(kibyte単位)。
メタデータのアクティビティログエリアの更新回数。
メタデータのビットマップ領域の更新回数。
まだDRBDから応答がない(完了していない)DRBDへのブロックI/Oリクエスト数。
DRBDが発行したローカルI/Oサブシステムへのオープンリクエストの数。
ローカルI/Oの輻輳を示します。
-
no:輻輳なし
-
uppeer: ファイルシステムなどDRBD より上位 のI/Oがブロックされている。代表的なものには以下がある。
-
管理者によるI/O中断。
drbdadmコマンドのsuspend-ioを参照。 -
アタッチ/デタッチ時の一時的なブロック。
-
バッファーの枯渇。DRBDパフォーマンスの最適化 参照。
-
ビットマップIO待ち
-
-
lower: 下位デバイスの輻輳
-
上位、下位両方がブロックされている。
接続単位:
対向ノードによって書き込まれているアプリケーションデータ。つまり、DRBD はそれを対向ノードに送信し、書き込まれたという確認応答を待っています。セクター単位(512バイト)。
対向ノードによって書き込まれている同期データ。つまり、DRBD は SyncSource が 同期データを対向ノードに送信し、データが書き込まれたことの確認応答を待っています。セクター単位(512バイト)。
接続とボリューム単位 (“peer device”):
同期されるデータのうち同期されたデータのパーセンテージ。
現在同期が中断されているかどうかを示す。値は no, user, peer, dependency でカンマ区切り。
対向ノードから受信したネットデータ(KiB単位)。
対向ノードへ送信したネットデータ(KiB単位)。
DRBD のビットマップによる現在この対向ノードと同期していないデータ量(KiB単位)。
対向ノードに送信されたが、対向ノードによってまだ確認されていないリクエスト数。
対向ノードから受信したが、このノードの DRBD によってまだ確認されていないリクエスト数。
過去数秒以内の同期速度。単位は MiB/秒。このユーザーズガイドの 同期速度の設定 セクションで説明されているオプションで、同期速度を変更できます。
同期が完了するまでの残り秒数。この数値は、過去数秒以内の同期速度と、同期されていないリソースの下位デバイスのサイズに基づいて計算されます。
5.3. リソースの有効化と無効化
5.3.1. リソースの有効化
通常、自動的にすべての設定済みDRBDリソースが有効になります。これは、
-
クラスタ構成に応じたクラスタ管理アプリケーションの操作による、または
-
systemd units (e.g.,
[email protected]) による
手動でリソースを起動する必要がある場合には、以下のコマンドの実行によって行うことができます。
# drbdadm up <resource>
他の場合と同様に、特定のリソース名の代わりにキーワード all を使用すれば、 /etc/drbd.conf で設定しているすべてのリソースを一度に有効にできます。
5.4. リソースの再設定
DRBDの動作中にリソースを再設定することができます。次の手順を行います。
-
/etc/drbd.confのリソース設定を変更します。 -
両方のノードで
/etc/drbd.confファイルを同期します。 -
両ノードでの
drbdadm adjust <resource>の実行
drbdadm adjust は drbdsetup を通じて実行中のリソースを調整します。保留中の drbdsetup 呼び出しを確認するには、 drbdadm を -d (dry-run,予行演習)オプションを付けて実行します。
/etc/drbd.conf の common セクションを変更して一度にすべてのリソースに反映させたいときには drbdadm adjust all を実行します。
|
5.5. リソースの昇格と降格
手動で リソースロール をセカンダリからプライマリに切り替える(昇格)、またはその逆に切り替える(降格)には、次のコマンドを実行します。
# drbdadm primary <resource> # drbdadm secondary <resource>
DRBDが シングルプライマリモード (DRBDのデフォルト)で、 コネクションステータス が Connected の場合、任意のタイミングでどちらか1つのノード上でのみリソースはプライマリロールになれます。したがって、あるリソースが他のノードに対してプライマリロールになっているときに drbdadm primary <resource> を実行すると、エラーが発生します。
リソースが デュアルプライマリモード に対応するよう設定している場合には、両方のノードをプライマリロールに切り替えることができます。これは、例えば仮想マシンのオンラインマイグレーションの際に利用できます。
5.6. 基本的な手動フェイルオーバ
Pacemakerを使わず、パッシブ/アクティブ構成でフェイルオーバを手動で制御するには次のようにします。
現在のプライマリノードで、DRBDデバイスを使用しているすべてのアプリケーションやサービスを停止し、DRBDデバイスをアンマウントし、リソースをセカンダリに降格させてください。
# umount /dev/drbd/by-res/<resource>/<vol-nr> # drbdadm secondary <resource>
プライマリにしたいノードでリソースを昇格してデバイスをマウントします。
# drbdadm primary <resource> # mount /dev/drbd/by-res/<resource>/<vol-nr> <mountpoint>
自動プロモート 機能を使用している場合はロール(プライマリ/セカンダリ)を手動で変更する必要はありません。それぞれサービス停止とアンマウント、マウントの操作のみ必要です。
5.7. systemdサービスを使用してきれいにシャットダウンする
drbd-utils バージョン9.26.0以降には、「円滑な停止」サービスである drbd-graceful-shutdown.service が含まれています。このサービスは、ノードをシャットダウンする際にクラスター全体においてDRBDの “「最後の1台」”の動作が適用されるようにし ます。
最初のDRBDデバイスが作成された時点で、優雅なシャットダウンサービスはudevサービスによって自動的に起動されます。システムをシャットダウンする際、優雅なシャットダウンサービスは、DRBDリソースをホストしているすべてのノードが正しい順序でサービスをシャットダウンし、最後のノードがクォーラムを維持できるようにします。
通常のシステムシャットダウンシーケンスでは、この介入なしには、ネットワーキングがシステムがファイルシステムをアンマウントし、DRBDデバイスを停止する前に停止することがよくあります。Graceful shutdownサービスがない場合、最後にシャットダウンする ノードがDRBDクオーラムを保持するようにするには、ノードをシャットダウンする前にファイルシステムを手動でアンマウントし、DRBDリソースを停止する必要があります。
ノード上で実行されているGraceful Shutdownサービスのおかげで、シャットダウン時にノードは自身のDRBDリソースを時代遅れとマ ークし、実行中のDRBDサービスを停止し、その後にネットワーキングサービスを停止させます。このシャットダウン手順により、クラスタを離れるDRBDノードは、ネットワークを介してその時代遅れの状態を最後のノードに伝えることができます。この方法で、クラスタを離れる最後のノードはクォーラムを維持することができます。
5.8. DRBDのアップグレード
DRBDのアップグレードは比較的簡単なプロセスです。このセクションには、特定のDRBD 9バージョンから別のDRBD 9バージョンへのアップグレードに関する警告や重要な情報が含まれています。
DRBDを8.4.xから9.xにアップグレードする場合は、 付録 の手順に従ってください。
5.8.1. DRBD 9.2.x へのアップグレード
以前の9.2ブランチ以外のバージョンからDRBD 9.2.xにアップグレードする場合は、リソース名に注意する必要があります。 DRBD 9.2.xではDRBDリソースの名前に厳格な命名規則が適用されます。デフォルトでは、DRBD 9.2.xではリソース名には英数字、。、+、、-の文字しか受け入れません(正規表現:[0-9A-Za-z.+-]*)。古い動作に依存している場合は、厳格な名前のチェックを無効にして戻すことができます:
# echo 0 > /sys/module/drbd/parameters/strict_names
5.8.2. DRBD 9.0.xからのアップグレード
DRBDの9.1および9.2ブランチにおけるワイヤプロトコルのコードに問題があるため、バージョン9.0.26以降を使用していない限り、DRBD 9.0から9.1または9.2へのアップグレードはできません。それ以前の9.0バージョンを使用している場合は、まずDRBD 9.0の最新のバグ修正バージョンにアップグレードした上で、9.1または9.2へのアップグレードを行ってください。
| バージョン9.0.26以降を使用している場合でも、より高いマイナーバージョンにアップグレードする前に、まずは9.0系の最新バージョンにアップグレードするのが最も安全です。最新の9.0バージョンは継続的インテグレーション(CI)テストで定期的に検証されているため、アップグレード元として最も安全なバージョンとなります。 |
5.8.3. 互換性
DRBDは、9.0.26より前のDRBD 9.0のバージョンを除き、マイナーバージョン間でのワイヤプロトコルの互換性を備えています。DRBDのワイヤプロトコルは、ホストのカーネルバージョンやマシンのCPUアーキテクチャに依存しません。
DRBDは、メジャーバージョン内ではプロトコル互換性があります。たとえば、すべての9.x.yリリースはプロトコル互換性があります。
5.8.4. DRBD9 のアップグレード
もし既に DRBD 9.x を稼働させている場合、新しい DRBD 9 バージョンにアップグレードするには、以下の手順に従ってください:
-
DRBDリソースが同期されていることを確認するためには、DRBDの状態を 確認する 必要があります。
-
新しいバージョン をインストールする。
-
DRBDサービスを停止するか、クラスターマネージャーを使用している場合は、アップグレードを行うクラスターノードを スタンバイ 状態にしてください。
-
新しいカーネルモジュールをロード するために、まずカーネルモジュールをアンロードしてから更新してください。
-
クラスターノードを使用している場合は、 DRBDリソースの開始し、 再びクラスターノードをオンラインにします。
これらの個々の手順は以下に詳細に記載されています。
DRBD の状態を確認する
DRBDを更新する前に、リソースが同期されていることを確認してください。drbdadm status all の出力には、リソースの状態が表示されます。以下に例として示される「data」というリソースが「UpToDate」の状態で表示されるはずです。
# drbdadm status all
data role:Secondary
disk:UpToDate
node-1 role:Primary
peer-disk:UpToDate
パッケージのアップグレード
バージョン9以内でDRBDをアップグレードする準備が整っている場合は、まずパッケージをアップグレードしてください。
RPM-based:
# dnf -y upgrade
DEB-based:
# apt update && apt -y upgrade
アップグレードが完了すると、最新のDRBD 9.xカーネルモジュールと drbd-utils がインストールされます。ただし、新しいカーネルモジュールはまだアクティブではありません。新しいカーネルモジュールをアクティブにする前に、まずクラスターサービスを一時停止する必要があります。
サービスの一時停止
クラスターサービスを手動で一時停止するか、クラスターマネージャーのドキュメントに従って停止することができます。 両方の手順について以下で説明します。クラスタマネージャーとしてPacemakerを使用している場合は、手動方法を使用しないでください。
新しいカーネルモジュールのロード
クラスターサービスを一時停止した後、DRBDモジュールは使用されていないはずなので、次のコマンドを入力してアンロードしてください。
# rmmod drbd_transport_tcp; rmmod drbd
” ERROR : Module drbd is in use ” のようなメッセージが出る場合は、まだすべてのリソースが正常に停止していません。
パッケージのアップグレードを再試行するか、アクティブなリソースを特定するために drbdadm down all コマンドを実行してください。
よくあるアンロードを妨げる原因には以下のものがあります。
-
DRBDが下位デバイスのファイルシステムにNFSエクスポートがある(
exportfs -vの出力を確認) -
ファイルシステムがまだマウントされています –
grep drbd /proc/mountsを確認してください。 -
ループバックデバイスがアクティブ (
losetup -l) -
デバイスマッパーが直接または間接的にDRBDを使用している。(
dmsetup ls --tree) -
DRBD-PV(
pvs)の LVM
| 上記はよくあるケースであり、すべてのケースを網羅するものではないという事に注意ください。 |
これで、DRBDモジュールをロードすることができます。
# modprobe drbd
次に、読み込まれているDRBDカーネルモジュールのバージョンがアップデートされた9.x.yバージョンであることを確認できます。drbdadm --version の出力には、期待しているアップグレード先の9.x.yバージョンが表示され、次のようになっているでしょう。
DRBDADM_BUILDTAG=GIT-hash: [...] build\ by\ buildd@lcy02-amd64-080\,\ 2023-03-14\ 10:21:20 DRBDADM_API_VERSION=2 DRBD_KERNEL_VERSION_CODE=0x090202 DRBD_KERNEL_VERSION=9.2.2 DRBDADM_VERSION_CODE=0x091701 DRBDADM_VERSION=9.23.1
DRBDリソースを再起動
あとはDRBDデバイスを再びupにして起動するだけです。単純に、 drbdadm up all で済みます。
次に、クラスターマネージャーを使用しているか、DRBDリソースを手動で管理しているかによって、リソースを起動する方法が異なります。クラスターマネージャーを使用している場合は、そのドキュメントに従ってください。
-
手動操作
# systemctl start drbd@<resource>.target
-
Pacemaker
# crm node online node-2
これによってDRBDは他のノードに接続し、再同期プロセスが開始します。
両方のノードがすべてのリソースで「最新」の状態に戻ると、アプリケーションをすでに更新済みのノードに移動させ、その後次にアップグレードしたいクラスターノードでも同じ手順を踏みます。
5.9. デュアルプライマリモードを有効にする
デュアルプライマリモードではリソースが複数ノードで同時にプライマリになることができます。永続的でも一時的なものでも可能です。
|
デュアルプライマリモードではリソースが同期レプリケート(プロトコルC)で設定されていることが必要です。そのためレイテンシに過敏となり、WAN環境には向いていません。 さらに、両リソースが常にプライマリとなるので、いかなるノード間のネットワーク不通でもスプリットブレインが発生します。 |
| DRBD 9.0.xのデュアルプライマリモードは、ライブマイグレーションで使用する 2 プライマリに制限されています。 |
5.9.1. 永続的なデュアルプライマリモード
デュアルプライマリモードを有効にするため、リソース設定の net セクションで、 allow-two-primaries オプションを yes に指定します。
resource <resource>
net {
protocol C;
allow-two-primaries yes;
fencing resource-and-stonith;
}
handlers {
fence-peer "...";
unfence-peer "...";
}
...
}そして、両ノード間で設定を同期することを忘れないでください。両ノードで drbdadm adjust <resource> を実行してください。
これで drbdadm primary <resource> で、両ノードを同時にプライマリのロールにすることができます。
| 適切なフェンシングポリシーを常に実装すべきです。フェンシングなしで ‘allow-two-primaries’ を設定するのは危険です。これはフェンシングなしで、シングルプライマリを使うことより危険になります。 |
5.10. オンラインデバイス照合の使用
5.10.1. オンライン照合を有効にする
オンラインデバイス照合 はデフォルトでは有効になっていません。有効にするには /etc/drbd.conf のリソース設定に以下の行を追加します。
resource <resource>
net {
verify-alg <algorithm>;
}
...
}<algorithm> は、システムのカーネル構成内のカーネルcrypto APIでサポートされる任意のメッセージダイジェストアルゴリズムです。通常は sha1 、 md5 、 crc32c から選択します。
既存のリソースに対してこの変更を行う場合は、 drbd.conf を対向ノードと同期し、両方のノードで drbdadm adjust <resource> を実行します。
5.10.2. オンライン照合の実行
オンライン照合を有効にしたら、次のコマンドでオンライン照合を開始します。
# drbdadm verify <resource>:<peer>/<volume>
コマンドを実行すると、DRBD が <peer> の <resource> の <volume> に対してオンライン照合を実行します。同期していないブロックを検出した場合は、ブロックに非同期のマークを付け、カーネルログにメッセージを書き込みます。このときにデバイスを使用しているアプリケーションは中断なく動作し続けます。また、 リソースロールの切り替え も行うことができます。
<Volume> はオプションです。省略された場合、そのリソース内のすべてのボリュームを検証します。
検証中に同期が取れていないブロックが検出された場合は、検証が完了した後に、次のコマンドを使用してそれらを再同期化す ることができます。
drbd-9.0.29 以降、推奨される方法は次のいずれかのコマンドです。
# drbdadm invalidate <resource>:<peer>/volume --reset-bitmap=no # drbdadm invalidate-remote <resource>:<peer>/volume --reset-bitmap=no
最初のコマンドは、リモートバージョンによってローカルの違いが上書きされます。 2 番目のコマンドは反対方向にそれを行います。
drbd-9.0.29 より前のバージョンでは、再同期を開始する必要があります。これを行う方法は、対向ノードをプライマリから切断し、切断している間にプライマリが少なくとも1 つのブロックを変更するようにすることです。
# drbdadm disconnect <resource>:<peer> ## write one block on the primary # drbdadm connect <resource>:<peer>
5.10.3. 自動オンライン照合
通常は、オンラインデバイス照合を自動的に実行するほうが便利です。自動化は簡単です。一方 のノードに /etc/cron.d/drbd-verify という名前で、次のような内容のファイルを作成します。
42 0 * * 0 root /sbin/drbdadm verify <resource>This will have cron invoke a device verification every Sunday at 42 minutes past midnight; so, if you come into the office on Monday morning, a quick examination of the resource’s status would show the result. If your devices are very big, and the \~32 hours were not enough, then you’ll notice VerifyS or VerifyT as replication state, meaning that the verify is still in progress.
オンライン照合をすべてのリソースで有効にした場合(例えば /etc/drbd.d/global_common.conf の common セクションに verify-alg <アルゴリズム> を追加するなど)には、以下のようにします。
42 0 * * 0 root /sbin/drbdadm verify all5.11. 同期速度の設定
バックグラウンド同期中は同期先のデータとの一貫性が一時的に失われるため、同期はできるだけ短時間で完了させるべきです。ただし、すべての帯域幅がバックグラウンド同期に占有されてしまうと、フォアグラウンドレプリケーションに使用できなくなり、アプリケーションのパフォーマンス低下につながります。これは避ける必要があります。同期用の帯域幅はハードウェアに合わせて設定する必要があります。
| 同期速度をセカンダリノードの最大書き込みスループットを上回る速度に設定しても意味がありません。デバイス同期の速度をどれほど高速に設定しても、セカンダリノードがそのI/Oサブシステムの能力より高速に書き込みを行うことは不可能です。 |
また、同じ理由で、同期速度をレプリケーションネットワークの帯域幅の能力を上回る速度に設定しても意味がありません。
5.11.1. 同期速度の計算
| 概算としては使用可能なレプリケーション帯域幅の30%程度を想定するのがよいでしょう。400MB/sの書き込みスループットを維持できるI/Oサブシステム、および110MB/sのネットワークスループットを維持できるギガビットイーサネットネットワークの場合は、ネットワークがボトルネックになります。速度は次のように計算できます。 |

この結果、 resynce-rate オプションの推奨値は 33M になります。
一方、最大スループットが80MB/sのI/Oサブシステム、およびギガビットイーサネット接続を使用する場合は、I/Oサブシステムが律速要因になります。速度は次のように計算できます。

この場合、 resync-rate オプションの推奨値は 24M です。
同じようにして800MB/sのストレージ速度で10Gbeのネットワークコネクションであれば、〜240MB/sの同期速度が得られます。
5.11.2. 可変同期速度設定
複数のDRBDリソースが1つのレプリケーション/同期ネットワークを共有する場合、同期が固定レートであることは最適なアプローチではありません。そのためDRBD 8.4.0から可変同期速度がデフォルトで有効になっています。このモードではDRBDが自動制御のループアルゴリズムで同期速度を決定して調整を行います。このアルゴリズムはフォアグラウンド同期に常に十分な帯域幅を確保し、バックグラウンド同期がフォアグラウンドのI/Oに与える影響を少なくします。
最適な可変同期速度の設定は、使用できるネットワーク帯域幅、アプリケーションのI/Oパターンやリンクの輻輳によって変わります。 DRBD Proxy の有無によっても適切な設定は異なります。DRBDの機能を最適化するためにコンサルタントを利用するのもよいでしょう。以下は(DRBD Proxy使用を想定した環境での)設定の 一例 です。
resource <resource> {
disk {
c-plan-ahead 5;
c-max-rate 10M;
c-fill-target 2M;
}
}
c-fill-target の初期値は BDP✕2 がよいでしょう。 BDP とはレプリケーションリンク上の帯域幅遅延積(Bandwidth Delay Product)です。
|
例えば、1GBit/sの接続の場合、200µsのレイテンシになります。[5]1GBit/sは約120MB/sです。120掛ける200*10-6秒は24000Byteです。この値はMB単位まで丸めてもよいでしょう。
別の例をあげると、100MBitのWAN接続で200msのレイテンシなら12MB/s掛ける0.2sです。2.5MBくらいになります。c-fill-target の初期値は3MBがよいでしょう。
他の設定項目については drbd.conf のマニュアルページを参照してください。
5.11.3. 永続的な固定同期速度の設定
ごく限られた状況[6]では、固定同期速度を使うことがあるでしょう。この場合には、まず c-plan-ahead 0; にして可変同期速度調節の機能をオフにします。
そして、リソースがバックグラウンド再同期に使用する最大帯域幅をリソースの resync-rate オプションによって決定します。この設定はリソースの /etc/drbd.conf の disk セクションに記載します。
resource <resource>
disk {
resync-rate 40M;
...
}
...
}同期速度の設定は1秒あたりの バイト 単位であり ビット 単位でない点に注意してください。デフォルトの単位は kibibyte で、 4096 であれば 4MiB となります。
| これはあくまでDRBDが行おうとする速度にすぎません。低スループットのボトルネック(ネットワークやストレージの速度)がある場合、設定した速度(いわゆる”理想値”)には達しません。 |
5.11.4. 同期速度の設定
同期すべきデータ領域の一部が不要になった場合、例えば、対向ノードとの接続が切れている時にデータを削除した場合などには Trim/Discardのサポート の有効性が感じられるかもしれません。
c-min-rate は間違われやすいです。これは同期速度の 最低値 ではなくて、この速度以上の速度低下を 意図的に 行わないという制限です。+ ネットワークとストレージの速度、ネットワーク遅延(これは回線共有による影響が大きいでしょう)、アプリケーションIO(関与することは難しいかもしれません)に応じた同期速度の管理まで 手が及ぶか どうかによります。
5.12. チェックサムベース同期の設定
チェックサムベース同期 はデフォルトでは有効になっていません。有効にするには、 /etc/drbd.conf のリソース構成に次の行を追加します。
resource <resource>
net {
csums-alg <algorithm>;
}
...
}<algorithm> は、システムのカーネル構成内のカーネルcrypto APIでサポートされる任意のメッセージダイジェストアルゴリズムです。通常は sha1 、 md5 、 crc32c から選択します。
既存のリソースに対してこの変更を行う場合は、 drbd.conf を対向ノードと同期し、両方のノードで drbdadm adjust <resource> を実行します。
5.13. 輻輳ポリシーと中断したレプリケーションの構成
In an environment where the replication bandwidth is highly variable (as would be typical in WAN replication setups), the replication link might occasionally become congested. In a default configuration, this would cause I/O on the primary node to block, which is sometimes undesirable.
If and only if you are using DRBD with DRBD Proxy, you can configure DRBD to suspend the ongoing replication in this case, causing the data set on the Primary node to pull ahead of data sets on Secondary nodes. In this suspended mode, DRBD keeps the replication channel open — it never switches to disconnected mode — but does not actually replicate until sufficient bandwidth becomes available again.
The following example is for a DRBD with DRBD Proxy configuration:
resource <resource> {
net {
on-congestion pull-ahead;
congestion-fill 2G;
congestion-extents 2000;
...
}
...
}When using DRBD Proxy with DRBD to replicate over a WAN, you can set both congestion-fill and congestion-extents together with the pull-ahead option, if you might need to try to avoid DRBD disconnections or other symptoms related to DRBD replication over a sometimes congested WAN link.
In this case, a good value for congestion-fill is 90% of the allocated DRBD proxy buffer memory.
congestion-extents の値は、影響するリソースの al-extents に設定した値の90%がよいでしょう。
5.14. I/Oエラー処理方針の設定
DRBDが 下位レベルI/Oエラーを処理する際の方針 は、リソースの /etc/drbd.conf の disk セクションの on-io-error で指定します。
resource <resource> {
disk {
on-io-error <strategy>;
...
}
...
}すべてのリソースのグローバルI/Oエラー処理方針を定義したい場合は、これを common セクションで設定します。
on-io-error オプションは on-no-data-accessible オプションとは独立しています。一部の on-io-error ストラテジーは、ピアディスク上でI/Oリクエストを再試行することを含みます。 on-no-data-accessible オプションの設定は、すべてのディスクでI/Oリクエストが失敗した場合のDRBDの動作を指示します。
on-io-error の <strategy> を次のうちの一つに設定できます:
detachこれがデフォルトで、推奨オプションです。下位レベルI/Oエラーが発生すると、DRBDはそのノードの下位デバイスを切り離し、ディスクレスモードで動作を継続します。
これにより、DRBDはディスクの状態を Inconsistent に変更し、失敗したブロックをDRBDクイック同期ビットマップで不一致としてマークし、I/O操作をサテライト(セカンダリノード)ディスク上で再試行します。少なくとも1つのサテライトでI/O操作が成功した場合、書き込み操作は成功と見なされます。DRBDは、さらに試行可能なサテライトディスクがなくなるまで読み取り操作を再試行します。
call-local-io-errorローカルI/Oエラーハンドラとして定義されたコマンドを呼び出します。このオプションを使うには、対応する local-io-error ハンドラをリソースの handlers セクションに定義する必要があります。local-io-error で呼び出されるコマンド(またはスクリプト)にI/Oエラー処理を実装するかどうかは管理者の判断です。
DRBDの以前のバージョン(8.0以前)にはもう1つのオプション panic があり、これを使用すると、ローカルI/Oエラーが発生するたびにカーネルパニックによりノードがクラスタから強制的に削除されました。このオプションは現在は使用できませんが、 local-io-error / call-local-io-error インタフェースを使用すると同じような動作を実現します。ただし、この動作の意味を十分理解した上で使用してください。
|
次のコマンドで、実行中のリソースのI/Oエラー処理方針を再構成することができます。
-
/etc/drbd.d/<resource>.resのリソース構成の編集 -
構成の対向ノードへのコピー
-
両ノードでの
drbdadm adjust <resource>の実行
5.15. レプリケーショントラフィックの整合性チェックを設定
レプリケーショントラフィックの整合性チェック はデフォルトでは有効になっていません。有効にする場合は、 /etc/drbd.conf のリソース構成に次の行を追加します。
resource <resource>
net {
data-integrity-alg <algorithm>;
}
...
}<algorithm> は、システムのカーネル構成内のカーネルcrypto APIでサポートされる任意のメッセージダイジェストアルゴリズムです。通常は sha1 、 md5 、 crc32c から選択します。
既存のリソースに対してこの変更を行う場合は、 drbd.conf を対向ノードと同期し、両方のノードで drbdadm adjust <resource> を実行します。
| この機能は本番環境での使用は想定していません。データ破壊の問題や、通信経路(ネットワークハードウェア、ドライバ、スイッチ)に障害があるかどうかを診断する場合にのみ使用してください。 |
5.16. リソースのサイズ変更
DRBD ボリュームを拡張する場合は、下から上に拡張する必要があります。最初に、すべてのノードで下位ブロックデバイスを拡張する必要があります。次に、DRBD に新しいスペースを使用するように指示します。
DRBD ボリュームが拡張された後、DRBD を使用しているものにそれを伝える必要があります。ファイルシステムを拡張する、あるいはこのボリュームが接続された状態で実行されている VM に新しい「ディスクサイズ」を認識させます。
これを行うには、通常、以下の手順を実行します。
-
すべてのノードで、バッキング論理ボリュームをリサイズします。例えば、LVMを使用している場合:
# lvextend -L +${additional_gb}g VG/LV -
一方のノードでDRBDリソースを昇格します。
# drbdadm resize ${resource_name}/${volume_number} -
DRBDのプライマリノード上でのみ、ファイルシステム固有のツールを使用してファイルシステムをリサイズします。以下の詳細、および オンライン拡張 セクションの詳細を参照してください。
ファイルシステムが異なれば、機能や管理ツールのセットも異なることに注意してください。例えば、XFS は拡張しかできません。また、引数にアクティブなマウントポイントを指定します: xfs_growfs /where/you/have/it/mounted
EXT ファミリは、拡張(オンラインでも)と縮小(オフラインのみ。最初にマウントを解除する必要があります)の両方が可能です。 ext3 または ext4 のサイズを変更するには、引数にマウントポイントではなく、(マウントされた)ブロックデバイスを指定します: resize2fs /dev/drbd#
当然、正しいDRBD( mount や df -T で表示されるもの)を使用してください。バッキング・ブロック・デバイスを使ってはいけません。DRBDが稼働している場合、それは動作しないはずです( resize2fs: Device or resource busy while trying to open /dev/mapper/VG-LV Couldn’t find valid filesystem superblock. )。 もしDRBDを停止させてオフラインで行おうとした場合、バッキングのLVやパーティションに直接ファイルシステムツールを実行したら、DRBDメタデータが破損する可能性があります。ですので、やめておいてください。
プライマリでアクティブなDRBDデバイスに対して、ファイルシステムのリサイズは 1 回だけ 実行します。DRBDはファイルシステム構造の変更をレプリケートします。そのためにDRBDを使用しています。
また、XFS ボリュームで resize2fs を使用したり、EXT で XFS ツールを使用したりしないでください。使用中のファイルシステムに適したツールを使用してください。
resize2fs で /dev/drbd7 をオープンしたとき、スーパーブロックの不正なマジックナンバーは、これが EXT ファイルシステムではないことを伝えているので、代わりに他のツールを試す必要があります。例えば xfs_growfs です。ブロックデバイスではなく、マウントポイントを引数として取ることに注意してください。
DRBDボリュームを縮小する場合、トップからボトムに向かって縮小する必要があります。まず、切り詰めたいスペースが誰も使用していないことを確認してください。次にファイルシステムを縮小します(ファイルシステムがその機能をサポートしている場合)。その後、DRBDにそのスペースの使用を停止するよう指示します。DRBD内部のメタデータは、バッキングデバイスの「末尾」にあるため、これは簡単ではありません。
DRBD がスペースを使用しないことが確実になったら、たとえば lvreduce を使用して、下位デバイスからスペースを切り離すことができます。
5.17. リソースのバッキングディスク名の変更
このガイドの他の場所でも述べているように、DRBDリソースを構成する際は、バスベースの名前付け(/dev/nvme4n1)ではなく、永続的なブロックデバイス名(/dev/disk/by-id/nvme-eui.cea2bf2ea901ceb4)を使用することが推奨されます。これにより、バスベースの名前の変更がDRBDリソースに影響を及ぼす可能性を防ぐことができます。バスベースの名前付けを使用している既存のDRBDリソースがある場合は、永続的なブロックデバイス名を使用するように再構成できます。これを行うには、リソースの再設定 にある手順の一般的な概要に従って、以下の手順を実行してください。
-
DRBDリソース設定ファイルで使用されているバスベースの名前を、永続的なブロックデバイス名に変更します。
lsblk -o Name,UUID,WWNコマンドを実行することで、指定されたノード上の特定のディスクのIDを確認できます。 -
再度変更した設定をコピーして、以下のコマンドを
-
各ノードで次回の再起動を待つか、あるいは適切なメンテナンスウィンドウ中に各ノードで
drbdadm adjustコマンドを入力してください。これにより、DRBDディスクが一時的にデタッチおよび再アタッチされます。その後、DRBDはリソースの再設定に使用した永続的なブロックデバイス名を使用するようになります。
5.17.1. オンライン拡張
動作中(オンライン)に下位ブロックデバイスを拡張できる場合は、これらのデバイスをベースとするDRBDデバイスについても動作中にサイズを拡張することができます。その際に、次の2つの条件を満たす必要があります。
-
影響を受けるリソースの下位デバイスが、 LVMやEVMSなどの論理ボリューム管理サブシステムによって管理されている。
-
現在、リソースのコネクションステータスが
Connectedになっている。
両方のノードの下位ブロックデバイスを拡張したら、一方のノードだけがプライマリ状態であることを確認してください。プライマリノードで次のように入力します。
# drbdadm resize <resource>
新しいセクションの同期がトリガーされます。同期はプライマリノードからセカンダリノードへ実行されます。
追加する領域がクリーンな場合には、追加領域の同期を—assume-cleanオプションでスキップできます。
# drbdadm -- --assume-clean resize <resource>
5.17.2. オフライン拡張する
DRBDが非アクティブの状態で両ノードのバックアップブロックデバイスが成長され、かつDRBDリソースが 外部メタデータ を使用している場合、新しいサイズが自動的に認識されます。管理者の介入は不要です。次に両ノード上でDRBDが再アクティブ化され、ネットワーク接続が正常に確立された後、DRBDデバイスは新しいサイズを持つようになります。
ただし、DRBD リソースが 内部メタデータ を使用するように設定されている場合、新しいサイズが利用可能になる前にこのメタデータを成長したデバイスの末尾に移動する必要があります。これを行うには、以下の手順を完了してください。
| これは高度な手順です。慎重に検討した上で実行してください。 |
-
DRBDリソースを停止します。
# drbdadm down <resource>-
リサイズする前にメタデータをテキストファイルに保存してください。
# drbdadm dump-md <resource> > /tmp/metadata
両方のノードでこれを行う必要があります。各ノードには個別のダンプファイルを使用してください。片方のノードでメタデータをダンプして、単にダンプファイルを相手のノードにコピーすることはやめてください。この方法ではうまくいきません。
-
両方のノードの下位ブロックデバイスを拡大します。
-
/tmp/metadataファイルのサイズ情報(la-size-sect)を書き換えます。la-size-sectは、必ずセクタ単位で指定する必要があります。 -
メタデータ領域の再初期化をします。
# drbdadm create-md <resource>
-
修正されたメタデータを両方のノードに再インポートしてください。
# drbdmeta_cmd=$(drbdadm -d dump-md <resource>)
# ${drbdmeta_cmd/dump-md/restore-md} /tmp/metadata
Valid meta-data in place, overwrite? [need to type 'yes' to confirm]
yes
Successfully restored meta data
この例では bash パラメータ置換を使用しています。他のシェルの場合、機能する場合もしない場合もあります。現在使用しているシェルが分からない場合は、 SHELL 環境変数を確認してください。
|
-
再度DRBDリソースを起動します。
# drbdadm up <resource>
-
一方のノードでDRBDリソースを昇格します。
# drbdadm primary <resource>
-
最後に、拡張したDRBDデバイスを活用するために、ファイルシステムを拡張します。
5.17.3. オンライン縮小
| 警告 : オンラインでの縮小は外部メタデータ使用の場合のみサポートしています。 |
DRBDデバイスを縮小する前に、DRBDの上位層(通常はファイルシステム)を縮小 しなければいけません 。ファイルシステムが実際に使用している容量を、DRBDが知ることはできないため、データが失われないように注意する必要があります。
| ファイルシステムをオンラインで縮小できるかどうかは、使用しているファイルシステムによって異なります。ほとんどのファイルシステムはオンラインでの縮小をサポートしません。XFSは縮小そのものをサポートしません。 |
オンラインでDRBDを縮小するには、その上位に常駐するファイルシステムを縮小した_後に_ 、次のコマンドを実行します。
# drbdadm resize --size=<new-size> <resource><new-size> には通常の乗数サフィックス(K、M、Gなど)を使用できます。DRBDを縮小したら、DRBDに含まれるブロックデバイスも縮小できます(デバイスが縮小をサポートする場合)。
DRBDのメタデータがボリュームの想定される箇所に 実際に 書き込まれるように下位デバイスのリサイズ後に drbdadm resize <resource> を実行してもよいでしょう。
|
5.17.4. オフライン縮小
もしDRBDが非アクティブの状態でバッキングブロックデバイスを縮小しようとすると、外部メタデータを使用している場合はブロックデバイスが現在のサイズよりも小さくなるため、次のアタッチ試行時にDRBDはこのブロックデバイスにアタッチを拒否します。または、内部メタデータを使用している場合はDRBDメタデータがバッキングブロックデバイスの末尾に書き込まれるため、メタデータが見つからなくなります。これらの問題を回避するためには、 online shrinking を使用できない場合には、この手順を使用してください。
| これは高度な手順です。慎重に検討した上で実行してください。 |
-
DRBDがまだ動作している状態で、一方のノードのファイルシステムを縮小します。
-
DRBDリソースを停止します。
# drbdadm down <resource>
-
縮小する前にメタデータをテキストファイルに保存してください。
# drbdadm dump-md <resource> > /tmp/<resource>-metadata
dump-mdコマンドがメタデータについての「不正な」警告で失敗した場合、まず指定したリソースのアクティビティログを適用するためにdrbdadm apply-al <resource>コマンドを実行する必要があります。その後で、dump-mdコマンドを再試行することがで きます。DRBDリソースに設定されたすべてのノードのメタデータを、各ノードごとに別々のダンプファイルを使用して取得してください。
メタデータを1つのノードにダンプして、単にそのダンプファイルをピアノードにコピーしないでください。これはうまくいきません。 -
各ノードで構成されたDRBDリソースのバッキングブロックデバイスを縮小してください。
-
各ノードで、ファイル
/tmp/<resource>-metadata中のサイズ情報 (la-size-sect) をセクター単位で適切に調整してください。la-size-sectはセクター単位で指定する必要があることを覚えておいてください。 -
*内部メタデータを使用している場合は、メタデータ領域を再初期化します(この時点では、縮小によりおそらく内部メタデータが失われています)。
# drbdadm create-md <resource>
-
各ノードで修正されたメタデータを再度インポートしてください。
# drbdmeta_cmd=$(drbdadm --dry-run dump-md <resource>) # ${drbdmeta_cmd/dump-md/restore-md} /tmp/<resource>-metadata Valid meta-data in place, overwrite? [need to type 'yes' to confirm] yes 再起動 メタデータの復元に成功しました。この例では、修正されたメタデータを復元するために必要な drbdmeta restore-mdコマンドを生成するために、BASHパラメータ置換が使用されています。他のシェルでは機能しないかもしれません。現在使用しているシェルが何かわからない場合は、SHELL環境変数を確認してください。 -
再度DRBDリソースを起動します。
# drbdadm up <resource>
5.18. 下位デバイスのフラッシュを無効にする
| バッテリバックアップ書き込みキャッシュ(BBWC)を備えたデバイスでDRBDを実行している場合にのみ、デバイスのフラッシュを無効にできます。ほとんどのストレージコントローラは、バッテリが消耗すると書き込みキャッシュを自動的に無効にし、バッテリが完全になくなると即時書き込み(ライトスルー)モードに切り替える機能を備えています。このような機能を有効にすることを強くお勧めします。 |
BBWC機能を使用していない、またはバッテリが消耗した状態でBBWCを使用しているときに、DRBDのフラッシュを無効にすると、 データが失われるおそれがあります したがって、これはお勧めできません。
DRBDは 下位デバイスのフラッシュ を、レプリケートされたデータセットとDRBD独自のメタデータについて、個別に有効と無効を切り替える機能を備えています。この2つのオプションはデフォルトで有効になっています。このオプションのいずれか(または両方)を無効にしたい場合は、DRBD設定ファイルの /etc/drbd.conf の disk セクションで設定できます。
レプリケートされたデータセットのディスクフラッシュを無効にするには、構成に次の行を記述します。
resource <resource>
disk {
disk-flushes no;
...
}
...
}DRBDのメタデータでディスクフラッシュを無効にするには、次の行を含めます:
resource <resource>
disk {
md-flushes no;
...
}
...
}リソースの構成を修正し、また、もちろん両ノードの /etc/drbd.conf を同期したら、両ノードで次のコマンドを実行して、これらの設定を有効にします。
# drbdadm adjust <resource>
1台のサーバのみがBBWCがある場合[7]には、ホストセクションに以下のような設定をしてください。
resource <resource> {
disk {
... common settings ...
}
on host-1 {
disk {
md-flushes no;
}
...
}
...
}5.19. スプリットブレイン時の動作の設定
5.19.1. スプリットブレインの通知
スプリットブレインが 検出される と、DRBDはつねに split-brain ハンドラを呼び出します(設定されていれば)。このハンドラを設定するには、リソース構成に次の項目を追加します。
resource <resource>
handlers {
split-brain <handler>;
...
}
...
}
<handler> はシステムに存在する任意の実行可能ファイルです。
DRBDディストリビューションでは /usr/lib/drbd/notify-split-brain.sh という名前のスプリットブレイン対策用のハンドラスクリプトを提供しています。これは指定したアドレスに電子メールで通知を送信するだけのシンプルなものです。root@localhost (このアドレス宛のメールは実際のシステム管理者に転送されると仮定)にメッセージを送信するようにハンドラを設定するには、 split-brain handler を次のように記述します。
resource <resource>
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
...
}
...
}
実行中のリソースで上記の変更を行い(ノード間で設定ファイルを同期すれば)、後はハンドラを有効にするための他の操作は必要ありません。次にスプリットブレインが発生すると、DRBDが新しく設定したハンドラを呼び出します。
5.19.2. スプリットブレインからの自動復旧ポリシー
| DRBDを設定して、スプリットブレイン(またはその他)のシナリオから生じるデータの相違を自動的に解決するように構成することは、潜在的な 自動データ損失 の設定です。その影響を理解し、問題があると判断した場合は設定しないでください。 |
| むしろ、フェンシングポリシー、クォーラム設定、クラスタマネージャの統合、クラスタマネージャの冗長化通信リンクなどを調べて、まず最初にデータの相違状況をつくらないようにすべきです。 |
スプリットブレインからの自動復旧ポリシーには、状況に応じた複数のオプションが用意されています。DRBDは、スプリットブレインを検出したときのプライマリロールのノードの数にもとづいてスプリットブレイン回復手続きを適用します。そのために、DRBDはリソース設定ファイルの net セクションの次のキーワードを読み取ります。
after-sb-0priスプリットブレインが検出されたときに両ノードともセカンダリロールの場合に適用されるポリシーを定義します。次のキーワードを指定できます。
-
disconnect: 自動復旧は実行されません。split-brainハンドラスクリプト(設定されている場合)を呼び出し、 コネクションを切断して切断モードで続行します。 -
discard-younger-primary: 最後にプライマリロールだったホストに加えられた変更内容を破棄して ロールバックします。 -
discard-least-changes:変更が少なかったほうのホストの変更内容を破棄してロールバックします。 -
discard-zero-changes: 変更がなかったホストがある場合は、 他方に加えられたすべての変更内容を適用して 続行します。
after-sb-1priスプリットブレインが検出されたときにどちらか1つのノードがプライマリロールである場合に適用されるポリシーを定義します。次のキーワードを指定できます。
-
disconnect:after-sb-0priと同様にsplit-brainハンドラスクリプト(構成されている場合)を呼び出し、 コネクションを切断して切断モードで続行します。 -
consensus:after-sb-0priで設定したものと同じ復旧ポリシーが適用されます。 これらのポリシーを適用した後で、 スプリットブレインの犠牲ノードを選択できる場合は自動的に解決します。それ以外の場合は、disconnectを指定した場合と同様に動作します。 -
call-pri-lost-after-sb:after-sb-0priで指定した復旧ポリシーが適用されます。 これらのポリシーを適用した後で、 スプリットブレインの犠牲ノードを選択できる場合は、犠牲ノードでpri-lost-after-sbハンドラを起動します このハンドラはhandlersセクションで設定する必要があります。 また、クラスタからノードを強制的に削除します。 -
discard-secondary: 現在のセカンダリロールのホストを、 スプリットブレインの犠牲ノードにします。
after-sb-2priスプリットブレインが検出されたときに両ノードともプライマリロールである場合に適用されるポリシーを定義します。このオプションは after-sb-1pri と同じキーワードを受け入れます。ただし、 discard-secondary と consensus は除きます。
上記の3つのオプションで、DRBDは他のキーワードも認識しますが、それらはめったに使用されないためここでは省略します。ここで説明されていないスプリットブレインの復旧キーワードに関しては drbd.conf のマニュアルページを参照ください。
|
たとえば、デュアルプライマリモードでGFSまたはOCFS2ファイルシステムのブロックデバイスとして機能するリソースの場合、次のように復旧ポリシーを定義できます。
resource <resource> {
handlers {
split-brain "/usr/lib/drbd/notify-split-brain.sh root"
...
}
net {
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
...
}
...
}
5.20. スタックされた3ノード構成の作成
3ノード構成では、1つのDRBDデバイスを別のデバイスの上に スタック (積み重ね)します。
| Stacking is deprecated in DRBD version 9.x, as more nodes can be implemented on a single level. See ネットワークコネクションの定義 for details. |
5.20.1. デバイススタックの留意事項
次のような事項に注意する必要があります。
-
スタックデバイス側が利用可能です。1つのDRBDデバイス
/dev/drbd0を設定して、その上位にスタックデバイス/dev/drbd10があるとします。この場合は、/dev/drbd10がマウントして使用するデバイスになります 。 -
デバイスのメタデータは、基になるDRBDデバイスとスタックされたDRBDデバイスの両方に保存されます。スタックされたデバイスでは、常に 内部メタデータ を使用する必要があります。つまり、スタックされたデバイスの有効なストレージ領域は、スタックされていないデバイスと比較して僅かに小さくなります。
-
スタックした上位デバイスを実行するには、下位のデバイスが プライマリロールになっている必要があります。
-
バックアップノードにデータを同期するには、 アクティブなノードのスタックデバイスがプライマリモードで動作している必要があります。
5.20.2. スタックリソースの設定
次の例では alice 、 bob 、 charlie という名前のノードがあり、 alice と bob が2ノードクラスタを構成し、 charlie がバックアップノードになっています。
resource r0 {
protocol C;
device /dev/drbd0;
disk /dev/vg0/lv0;
meta-disk internal;
on alice {
address 10.0.0.1:7788;
}
on bob {
address 10.0.0.2:7788;
}
}
resource r0-U {
protocol A;
stacked-on-top-of r0 {
device /dev/drbd10;
address 192.168.42.1:7789;
}
on charlie {
device /dev/drbd10;
disk /dev/vgdrbd/lv10;
address 192.168.42.2:7789; # Public IP of the backup node
meta-disk internal;
}
}
この設定の disk 値は LVM 論理ボリュームを使用しています。DRBD リソースの下層で LVM や ZFS 論理ボリュームではなく物理ディスクを使用している場合は、バスベースの名前(例: /dev/nvme4n1)ではなく、永続的なブロックデバイス名(/dev/disk/by-id/<disk-by-id>)を使用してディスクを参照してください。これにより、バスベースの名前の変更が DRBD リソースに影響を与える可能性を防ぐことができます。特定のディスクの ID を特定するには、lsblk -o Name,UUID,WWN コマンドを実行してください。
|
他の drbd.conf 設定ファイルと同様に、この設定ファイルもクラスタのすべてのノード(この場合は3つ)に配布する必要があります。非スタックリソースの設定にはない、次のキーワードにご注意ください。
stacked-on-top-ofこのオプションによって、DRBDに含まれるリソースがスタックリソースであることをDRBDに知らせます。これは、通常リソース設定内にある on セクションのうちの1つを置き換えます。stacked-on-top-of は下位レベルのリソースには使用しないでください。
| スタックリソースに Protocol A を使用することは必須ではありません。アプリケーションに応じて任意のDRBDのレプリケーションプロトコルを選択できます。 |

5.20.3. スタックリソースを有効にする
スタックリソースを有効にするには、まず、下位レベルリソースを有効にしてどちらか一方をプライマリに昇格します。
drbdadm up r0 drbdadm primary r0
非スタックリソースと同様に、スタックリソースでは DRBD メタデータを作成する必要があります。これは、以下のコマンドを使用して行います:
# drbdadm create-md --stacked r0-U
この後でバックアップノードのリソースを起動し、3ノードレプリケーションを有効にします。
# drbdadm up --stacked r0-U # drbdadm primary --stacked r0-U
この後でバックアップノードのリソースを起動し、3ノードレプリケーションを有効にします。
# drbdadm create-md r0-U # drbdadm up r0-U
クラスタ管理システムを使えばスタックリソースの管理を自動化できます。
5.21. 永続的なディスクレスノード
ノードはしばしDRBDの中で永続的にディスクレスになるときがあります。以下はディスクをもつ3つのノードと永続的なディスクレスノードの構成例です。
resource kvm-mail {
device /dev/drbd6;
disk /dev/vg/kvm-mail;
meta-disk internal;
on store1 {
address 10.1.10.1:7006;
node-id 0;
}
on store2 {
address 10.1.10.2:7006;
node-id 1;
}
on store3 {
address 10.1.10.3:7006;
node-id 2;
}
on for-later-rebalancing {
address 10.1.10.4:7006;
node-id 3;
}
# DRBD "client"
floating 10.1.11.6:8006 {
disk none;
node-id 4;
}
# rest omitted for brevity
...
}
永続的なディスクレスノードはビットマップスロットが割り当てられません。このようなノードのステータスは、エラーでも予期せぬ状態でもないので緑で表示されます。詳細は クライアントモード を参照ください。
5.22. データ再配置
以下の例では、すべてのデータ領域は3台に冗長化するポリシーを想定しています。したがって最小構成で3台のサーバが必要です。
しかし、データ量が増えてくると、サーバ追加の必要性に迫られます。その際には、また新たに3台のサーバを購入する必要はなく、1つのノードだけを追加をしてデータを 再配置 することができます。
上の図では、3ノードの各々に25TiBのボリュームがある合計75TiBの状態から、4ノードで合計100TiBの状態にしています。
データを再配置する時には、 新しい ノードとDRBDリソースを削除したいノードを選択する必要があります。現在 アクティブ なノードからリソースを削除する場合には注意が必要です。 DRBDが プライマリ のノードからリソースを削除する場合にはサービスを移行するか、そのノードのリソースを DRBDクライアント として稼働させるかにしてください。通常は セカンダリ のノードから選ぶほうが簡単です(それができない場合もあるでしょうが)。
5.22.1. ビットマップスロットの用意
移動するリソースには一時的に未使用の ビットマップスロット 用のスペースが必要です。
<<s-first-time-up,`drbdadm create-md` の時>> にもう一つ割り当てます。または、 `drbdadm` がもう1つスロットを取っておくように設定にプレースホルダを設けてもよいでしょう。
resource r0 {
...
on for-later-rebalancing {
address 10.254.254.254:65533;
node-id 3;
}
}
|
このスロットを実際に利用するには以下が必要です。
今後のバージョンの |
5.22.2. 新しいノードの用意と有効化
まずは新しいノードに( lvcreate 等で)下位のストレージリュームを作成する必要があります。 次に設定ファイルのプレイスホルダーに現在のホスト名、アドレス、ストレージのパスを書き込みます。そしてすべての必要なノードにリソース設定をコピーします。
新しいノードでメタデータを次のようにして(一度だけ)初期化します
# drbdadm create-md <resource> v09 Magic number not found Writing meta data... initialising activity log NOT initializing bitmap New drbd meta data block successfully created.
5.22.3. 初期同期の開始
新しいノードでデータを受け取ります。
そのために以下のようにして既存のノードでネットワークコネクションを定義します。
# drbdadm adjust <resource>
そして新しいノードでDRBDデバイスを開始します。
# drbdadm up <resource>
5.22.4. 接続確認
新しいノードで、次のコマンドを入力して、DRBDリソースの状態を表示してください。
# drbdadm status <resource>
他のすべてのノードが接続されていることを確認してください。
5.22.5. 初期同期後
新しいノードが UpToDate になったらすぐに、設定中の他のノードのうち1つが for-later-rebalancing に変更できるようになり、次のマイグレーション用にキープしておけるようになります。
次の再配置用に小さなビットマップスロットしかない新規ノードに drbdadm create-md をすることにはリスクがあると思う方もいることでしょう。あらかじめIPアドレスとホスト名を用意しておくのが簡単な方法でしょう。
|
再度変更した設定をコピーして、以下のコマンドを
# drbdadm adjust <resource>
全ノードで実行します。
5.23. クォーラム設定
このセクションでは、高可用性クラスターにおいてスプリットブレイン状況やデータの発散を回避するために DRBDクォーラム機能 を設定する方法について説明します。
DRBDリソースのクォーラムを有効にするには、DRBDリソース構成ファイルの options セクション内にある quorum オプションを majority 、 all 、または数値に設定することで設定します。デフォルトでは、DRBDのクォーラムは有効になっておらず、オプションは off に設定されています。
DRBDクォーラムを有効にするDRBDリソース構成の例は次の通りです。
resource quorum-demo {
options {
quorum <majority|all|numerical value>;
[...]
}
[...]
}
quorum オプションを /etc/drbd.d/global_common.conf というグローバルDRBD構成ファイルの common セクション内の options サブセクションで設定することで、クォーラムをグローバルに有効にすることもできます。グローバル構成ファイル内でクォーラムを有効にし、他の関連するオプションを設定すると、特定のDRBDリソース構成ファイル内で同じオプションが設定されていない限り、すべてのDRBDリソースに影響が及びます。その場合、DRBDリソース構成ファイル内で設定されたオプション値が優先されます。
DRBD クォーラムを有効にする例として、次のようなグローバル構成があります。
[...]
common {
options {
quorum <majority|all|numerical value>;
[...]
}
[...]
}
[...]
5.23.1. DRBDのクォーラムを過半数に設定します。
quorum オプションを majority に設定することで、ノードはクラスタ内でのDRBD実行ノードの過半数パーティションのメンバーである場合にのみ複製データセットに書き込むことができます。過半数パーティション内のノード数は、対象のDRBDリソースのクラスタ全体のノード数の半分より大きくなければなりません。3ノードのクラスタでは、そのようなノードは少なくとも1つの他のノードとネットワーク経由で通信できる必要があります。
他のセカンダリノードがクラスタからきれいに退出し、データを古いものとしてマークした場合には、この例外が発生します。古いノードはクォーラム投票に参加しません。この挙動は ラストマン・スタンディング 状況につながる可能性があります。これにより、アップデートされたノードが1つだけ残っていても、クラスタ内でサービスを維持することができます。
5.23.2. DRBDクォーラムを全体に設定します。
quorum オプションを all に設定することで、ノードはクラスタ内のそのデータセットに関連する他のすべてのDRBD実行ノードとネットワーク通信できる場合にのみレプリケートされたデータセットに書き込むことができます。これは最も厳格なクォーラムの実装であり、クラスタ内でデータの発散を避ける最も慎重な(または最も偏執的な)方法です。
majority セクションで言及されたルールの例外は、ノードを優雅に終了させるための all クォーラム実装にも適用されます。つまり、ノードを優雅に終了すると、そのデータは古いものとしてマークされ、古いノードはクォーラム投票に参加しません。
5.23.3. DRBDのクォーラムを数値に設定する
柔軟性を持たせるために、 quorum オプションを数値に設定することもできます。このクォーラムの実装は最も堅実です。なぜなら、管理者として、クラスター全体のノード数についての知識があり、 majority や all のクォーラムヒューリスティックの範囲外かもしれない一部の特殊なケースに適しているからです。ただし、 quorum を数値に設定するには手動の介入と、クラスター内のノード数を増減させる場合にはプロパティの変更が必要です。ほとんどの場合、 quorum オプションを majority に設定することで十分であり、好ましいです。
quorom プロパティを数値に設定する場合は、クラスタ内の合計ノード数の半分よりも大きい数値を選択してください。この数値よりも小さい数値を選択すると、クォーラムの目的が損なわれ、データの食い違いのリスクが増加します。
|
5.23.4. 保証された最低限の冗長化
DRBDリソースやグローバル構成で quorum-minimum-redundancy オプションを使用することにより、指定した最新の状態にあるノード数以上で構成される必要があるクォーラムパーティションを定義します。 quorum-minimum-redundancy オプションは、 quorum オプションと同じ majority 、 all 、または数値の引数を取ります。
ディスクフルなノードだけが最新状態になることができるため、このオプションを使用すると、レプリケーションされたデータに依存するサービスが開始する前に、データ再同期操作が完了するのを待ちたいという意向を表現する方法です。つまり、データの最低冗長性を保証するセキュリティを使用可能なサービスの可用性よりも優先するということです。金融データの冗長性や規制上必要とされるデータの冗長性などが、このオプションを設定すると役立つ場合の例です。
quorum-minimum-redundancy オプションを指定することが、DRBDリソースについて手動で介入が必要となる状況を引き起こす可能性があるコーナーケースが存在するかもしれません。また、クォーラムのための最小データレプリカ冗長性を指定することの潜在的な副作用として、レプリカの冗長性が 1 を超える値の場合、クラスタ内での ラストマン・スタンディング 動作を阻止する可能性があります。これらの理由から、このオプションを使用する必要性は、データの要件がその使用を強制しない限り、ほとんどの場合は不要だと言えます。
|
次の例を考えてみましょう。以下は5ノード・クラスター用の設定例です。
resource quorum-demo {
options {
quorum majority;
quorum-minimum-redundancy 2;
[...]
}
[...]
}
この例では、5ノードのクラスターにおいて、過半数パーティションは3ノードから構成されます。 quorum-minimum-redundancy オプションのため、リソースのプライマリノードがデータセットに書き込むことを許可される前に、その3ノードのうちの2ノードはディスクを保持し、最新の状態である必要があります。
5.23.5. クォーラムを失った時の動作
DRBDリソースのプライマリロールを担当しているノードがクォーラムを失った場合、そのノードはデータセットへの書き込み操作を即座に停止する必要があります。これは、DRBDデバイスへのすべてのI/Oリクエストに対してエラーが返されることを意味します。通常、これは優雅なシャットダウンが不可能であることを意味します。優雅なシャットダウンを行うには、データセットをノード上で期限切れにマークするなど、より多くの変更が必要になります。
次に、I/Oエラーはブロックレベルからファイルシステムへ、そしてファイルシステムからユーザースペースのアプリケーションに伝播します。理想的には、アプリケーションは単純にI/Oエラーが発生した場合に終了します。その後、PacemakerやDRBD Reactorなどのクラスターリソースマネージャーがファイルシステムをアンマウントし、ノードをDRBDリソースのセカンダリロールに降格させることが可能となります。もしもこれが貴方のアプリケーションの振る舞いであるならば、 on-no-quorum リソースオプションを io-error に設定する必要があります。以下は設定例です:
resource quorum-demo {
options {
quorum majority;
on-no-quorum io-error;
[...]
}
}
アプリケーションが最初のI/Oエラーで終了しない場合、DRBDを構成して、クォーラムを失ったDRBDプライマリノード上のリソースのI/Oを凍結することができます。以下は構成の例です。
resource quorum-demo {
options {
quorum majority;
on-no-quorum suspend-io;
[...]
}
[...]
}
この構成では、プライマリノードがクォーラムを失い、データセットへのI/Oを一時停止する場合、 クォーラムを失ったプライマリノードの回復 セクションで説明されている手順に従うことができます。
5.23.6. タイブレーカーとしてのディスクレスノードを使用
クラスタ内のすべてのノードに接続されているディスクレスノードを利用して、クォーラムネゴシエーションプロセスのタイブレークを解消できます。
ノードAがプライマリで、ノードBがセカンダリである、次の2ノードクラスタを考えます。

2つのノード間の接続が失われるとすぐに、2つのノードはクォーラムを失い、クラスタ上のアプリケーションはデータを書き込めなくなります。

もしクラスタにディスクレスとして構成された3番目のノードCを追加すると、DRBDバージョン9.0.18以降で利用可能な クォーラムタイブレーカー 機能を活用できます。

この場合、プライマリノードとセカンダリノードが互いとの接続を失った際、それぞれがディスクレスのタイブレーカーと通信を維持できます。このため、プライマリノードは作業を継続できますが、セカンダリノードはその DRBD リソースを過去の状態に降格させます。リソースが過去の状態にある間、ノードはプライマリの役割に昇格することはできません。

同時に2つの接続が失われる場合は特別なケースであり、次に説明します。

この場合、タイブレーカーノードはプライマリノードとパーティションを形成します。そのため、プライマリはクォーラムを保持し続け、サブノードは古い状態になります。
| ここでは、セカンダリノードの DRBD リソースの状態は “UpToDate” になりますが、それでもクォーラムが不足しているため、プライマリロールに昇格することができません。 |
次に、プライマリノードがタイブレーカーノードへの接続を失う可能性を考えてみましょう。

この場合、プライマリノードは使用不可能となり、「クォーラムが停止」の状態になります。これにより、DRBD上のアプリケーションはI/Oエラーを受信することになります。その後、PacemakerやDRBD ReactorなどのクラスターリソースマネージャーがノードBをプライマリ役割に昇格させ、そのノード上でサービスを維持します。
ディスクレス・タイブレーカー・ノードが「サイドを切り替える」場合に、データの発散を避ける必要があります。 このシナリオを考えてみましょう。

プライマリノードとセカンダリノードの間の接続が失われましたが、アプリケーションはプライマリノードで引き続き実行されます。なぜなら、そのノードはディスクレスのタイブレーカーノードとの過半数パーティションの一部だからです。その後、プライマリノードは突然、ディスクレスノードとの接続を失います。
この場合、どのノードもプライマリロールに昇格できず、クラスターは運用を続けることができません。
| データの発散に対する保護は、常にサービスの可用性を確保するよりも優先されます。 |
次に、別のシナリオを考えてみましょう。

ここでは、アプリケーションはプライマリーノードで実行されており、セカンダリノードは利用できません。その後、タイブレーカーノードはまずプライマリーノードとの接続を失い、その後セカンダリーノードに再接続します。この場合、セカンダリーノードはプライマリーノードになることはできません。
| クォーラムを失ったノードは、ディスクレスなノードに接続してもクォーラムを回復することはできません。この場合、再接続するノードがディスクレスノードに対して自らのデータセットの “up-to-date” を確認する信頼できる方法は存在しません。なぜなら、ディスクレスノードは正確なチェックを行うためのローカルデータセットを持っていません。したがって、この場合、クォーラムを持つノードは存在せず、クラスターは停止します。 |
5.23.7. ラストマン・スタンディング
クラスターからスムーズに離脱するノードは、DRBDクォーラムを決定する際に、故障したノードとは異なる方法でカウントされます。この文脈では、「スムーズに離脱」とは、離脱するノードがそのデータを非最新の状態としてマークし、そのノードが残りのノードに自身のデータが非最新であることを伝えることができたことを意味します。スムーズに離脱することは、 drbdadm down (または drbdadm disconnect )コマンドを実行することと同等です。
すべてのディスクが更新されていないノードのグループでは、そのグループ内のノードはいずれもプライマリの役割に昇格することはできません。[8]
つまり、1 つのノードを除くすべてのノードがクラスターから離脱した場合、そのすべてのノードが正常に離脱している限り、クォーラムを維持できます。ただし、他のノードのいずれかが不当に離脱した場合、残りのノードは、離脱したノードがパーティションを形成し、最新のデータにアクセスできると想定する必要があります。
ラストマンスタンディングの機能は、ソフトウェアのアップグレードやノードにハードウェアを交換または追加するなどのシステムメンテナンスを行う必要がある場合に役立ちます。この場合、メンテナンスする必要があるノードまたはノードは、クラスターから円滑に離れ、プライマリーノードが引き続き実行し、サービスをホストし、複製されたデータセットに書き込むことができます。これにより、ユーザーにアプリケーションやサービスのダウンタイムを発生させることなく、他のノードをサービスする環境が提供されます。
5.24. DRBD の削除
DRBD を削除する場合は、以下のステップに従います。
-
サービスを停止し、DRBD ボリュームのファイルシステムをマウント解除します。クラスタマネージャを使用している場合は、最初にサービスの制御を停止するようにしてください。
-
drbdadm down <res>またはdrbdadm down allで DRBD リソースを停止します。-
DRBDリソースが内部メタデータを使用している場合、バッキングデバイスのすべてのスペースをカバーするようにファイルシステムのサイズを変更することがあります。この手順により、DRBDのメタデータが効果的に削除されます。これは簡単に元に戻すことができないアクションです。ext2やext3、ext4などのファイルシステムには、 「resize2fs <backing_dev>」 コマンドを使用してこれを行うことができます。アンマウントされたファイルシステムのサイズ変更や、特定の条件下でのオンライン拡張もサポートしています。XFSは、
xfs_growfsコマンドを使用してオンラインでのみ拡張できます。
-
-
下位デバイスを直接マウントし、それらの上でサービスを開始します。
-
rmmod drbd_transport_tcpとrmmod drbdで DRBD カーネルモジュールをアンロードします。 -
DRBD ソフトウェアパッケージをアンインストールします。
6. DRBD Proxyの使用
6.1. DRBD Proxyの使用においての検討事項
<<s-drbd-proxy,DRBD Proxy>> プロセスは、DRBDが設定されているマシン上に直接配置するか、個別の専用サーバに配置することができます。DRBD Proxyインスタンスは、複数のノードの複数のDRBDデバイスのプロキシとして機能することができます。
DRBD ProxyはDRBDに完全に透過的です。通常、データパケットの送信数が多いことが予想されるため、アクティビティログは十分に大きくする必要があります。これにより、プライマリノードの障害後に再同期が長くなる可能性があるため、DRBDの csums-alg 設定を有効にすることが推奨されています。
DRBD Proxyのより詳細な情報については DRBD Proxyによる遠距離レプリケーション をご参照ください。
6.2. DRBD Proxyの制御
DRBD Proxyは、適切な契約をお持ちのLINBITのお客様にご利用いただけます。DRBD Proxyの試用をご希望の場合は、LINBITチームにお問い合わせいただき、評価を開始してください。
DRBD ProxyはLINBITリポジトリからインストールできます。これらのリポジトリの設定方法の詳細については、ノードを登録し、パッケージリポジトリを構成するためのLINBITヘルパースクリプトの使用を参照してください。DRBD Proxy バージョン4の場合は、`drbd-proxy-4`リポジトリを有効にします。レガシーなDRBD Proxy バージョン3.2の場合は、`drbd-proxy-3.2`リポジトリを有効にします。
リポジトリの設定が完了したら、パッケージマネージャーを使用して DRBD Proxy をインストールできます。例えば、以下の通りです。
# dnf install drbd-proxy
Or:
# apt install drbd-proxy
DRBD Proxyを有効にするには、以下を実行してください。
# systemctl enable --now drbd-proxy.socket
これにより、systemdはDRBD Proxyコントロールソケットでのリスニングを開始します。drbdadm を使用してDRBD Proxyを構成した場合、または drbd-proxy-ctl が直接使用された場合、対応するsystemdサービスが開始されます。drbd-proxy.service を直接有効にする必要はありません。
DRBD Proxy バージョン 3 には、通常 /etc/init.d に配置される init スクリプトが含まれています。このスクリプトは drbdadm ツールを使用して DRBD Proxy の設定も行うため、起動や停止には必ずこの init スクリプトを使用してください。
|
6.3. ライセンスファイル
LINBITからライセンスを取得すると、DRBD Proxyの実行に必要なライセンスファイルが送付されます。ファイル名は drbd-proxy.license で、これを対象マシンの /etc ディレクトリにコピーする必要があります。
# cp drbd-proxy.license /etc/
DRBD Proxy バージョン 3 では、ライセンスファイルの所有ユーザーおよびグループは drbdpxy である必要があります。
|
6.4. LINSTOR を使用したDRBD Proxy 設定
DRBD Proxyは、LINSTOR ユーザガイドの説明に従って、LINSTORを使用して構成できます。
6.5. リソースファイルを使用した設定
DRBD Proxyはリソースファイルを編集することで設定することもできます。proxy という追加セクションやホストセクション内の proxy on セクションを追加することで構成されます。
DRBDノードで直接実行されるプロキシのDRBD Proxyの設定例を次に示します。
resource r0 {
protocol A;
device /dev/drbd15;
disk /dev/VG/r0;
meta-disk internal;
proxy {
memlimit 512M;
plugin {
zstd level 7;
}
}
on alice {
address 127.0.0.1:7915;
proxy on alice {
inside 127.0.0.1:7815;
outside 192.168.23.1:7715;
}
}
on bob {
address 127.0.0.1:7915;
proxy on bob {
inside 127.0.0.1:7815;
outside 192.168.23.2:7715;
}
}
}inside IPアドレスはDRBDとDRBD Proxyとの通信に使用し、 outside IPアドレスはプロキシ間の通信に使用します。後者はファイヤーウォール設定で許可する必要があります。
6.6. DRBD Proxyの制御
`drbdadm`は、指定されたDRBDリソースのローカルDRBD Proxyプロセスへの接続を設定または削除するための、`proxy-up`および`proxy-down`サブコマンドを提供します。`drbd-proxy`サービスは起動時に、リソースファイルで定義された接続を追加するために`proxy-up`コマンドを使用します。
DRBD Proxyには、`drbd-proxy-ctl`と呼ばれる低レベル設定ツールがあります。
| DRBD Proxy v3では、コマンドは`-c`パラメーターを使用して渡されます。例えば、`drbd-proxy-ctl -c “show hconnections”`のように実行します。 |
使用可能なコマンドを表示するには次のようにします。
# drbd-proxy-ctl --help
以下にコマンドを列挙します。最初のいくつかのコマンドは通常は直接使用することはありません( drbdadm proxy-up や drbdadm proxy-down コマンド経由で使用されます)。それ以降のものは様々なステータスや情報を表示します。
add connection <name> lots of arguments-
通信経路を作成します。これは
drbdadm proxy-upコマンド経由で使用されるものなので、長い構文は省略しています。 del connection <name>-
通信経路を削除します。
set memlimit <name> <memlimit-in-bytes>-
コネクションのメモリ制限を設定します。このコマンドは、通常の単位
k、M、およびGを認識します。このコマンドで可能なのは、メモリ制限の増加のみです。メモリ制限を減らすには、リソースファイル内の値を変更し、drbdadm adjustを使用してください。これにより、コネクションがいったん削除され、より低い制限で再度追加されます。 show-
現在設定されている通信経路を表示します。
show memusage-
各接続のメモリ使用状況を表示します。例えば、次のコマンドはメモリ使用状況を監視します。
# watch -n 1 'drbd-proxy-ctl show memusage'
show [h]subconnections-
現在接続中の各コネクションを種々の情報と共に表示します。
hをつけると、人間が可読のバイト単位のフォーマットで出力します。 show [h]connections-
現在設定されている接続とその状態を表示します。
hを指定すると、バイト数を人間が読みやすい形式で出力します。DRBD Proxy バージョン4を使用する場合、Status列には以下のいずれかの状態が表示されます。-
Connecting: 接続中リモートのDRBD Proxyプロセスと通信できません。
-
ProxyConnected: リモートのDRBD Proxyへの接続が確立されました。DRBD ProxyインスタンスとDRBD間の接続はまだ確立されていません。
-
Connected: DRBDの接続が完全に確立されています。
-
- 統計情報を出力する
-
この機能は、現在アクティブな接続に関する詳細な統計情報を、解析しやすいフォーマットで表示します。モニタリングソリューションへの統合に活用してください!
レガシーなDRBD Proxy v3は、上記のコマンドをUID 0(すなわちrootユーザー)からのみ受け付けますが、このコマンドだけは例外で、どのユーザーでも使用できます(ただし、UNIXの権限設定によって /var/run/drbd-proxy/drbd-proxy-ctl.socketにあるプロキシソケットへのアクセスが許可されている場合に限ります)。権限の設定については、/etc/init.d/drbdproxyの起動スクリプトを参照してください。
6.7. DRBD Proxy Pluginsについて
DRBD Proxy バージョン4で提供されているのは zstd プラグインのみです。zstd(Zstandard)は高い圧縮率を実現するリアルタイム圧縮アルゴリズムです。非常に高速なデコーダーを備え、実行速度とのトレードオフにおいて非常に幅広い圧縮設定が可能です。圧縮率は「レベル」パラメータに依存し、1から
22. レベル20を超えると、DRBD Proxyはより多くのメモリを必要とします。
lz4 および zlib のプラグイン設定は、後方互換性のために適切な zstd 圧縮レベルにエイリアスされています。
お客様の環境に最適な設定については、LINBITチームにお問い合わせください。最適な設定は、CPU(速度、スレッド数)、利用可能なメモリ、入出力の帯域幅、および予想されるI/Oスパイクによって異なります。また、あらかじめ1週間分の`sysstat`データを用意しておくと、構成の決定に役立ちます。
6.7.1. DRBD Proxy バージョン3 のプラグイン
DRBD Proxy バージョン3では、他のソフトウェア圧縮アルゴリズムを利用する追加のプラグインがいくつか提供されています。
lz4 は非常に高速な圧縮アルゴリズムです。 通常データを1/2から1/4に圧縮でき、使用するネットワーク帯域も1/2から3/2程度になります。
zlib プラグインは、圧縮にGZIPアルゴリズムを使用しています。 lz4 よりもCPUを多く使用しますが、圧縮率は1:3から1:5の比率を提供します。
lzma プラグインは liblzma2 ライブラリを使用しています。このプラグインは数百 MiB の辞書を使用できます。これにより、小さな変更でも繰り返しデータの非常に効率的なデルタ圧縮が可能です。lzma は zlib よりもはるかに高い圧縮率を実現しますが、より多くの CPU とメモリを必要とします。仮想マシンが DRBD の上にある実世界のテストでは、1:10 から 1:40 の比率を実現しました。lzma プラグインはライセンスで有効にする必要があります。
6.8. WAN側の帯域幅制限を使用する
代わって、Linuxカーネルのトラフィック制御フレームワークを使ってください。
以下の例で、インターフェース名、ソースのポート、IPアドレスを変更して使ってください。
# tc qdisc add dev eth0 root handle 1: htb default 1
# tc class add dev eth0 parent 1: classid 1:1 htb rate 1gbit
# tc class add dev eth0 parent 1:1 classid 1:10 htb rate 500kbit
# tc filter add dev eth0 parent 1: protocol ip prio 16 u32 \
match ip sport 7000 0xffff \
match ip dst 192.168.47.11 flowid 1:10
# tc filter add dev eth0 parent 1: protocol ip prio 16 u32 \
match ip dport 7000 0xffff \
match ip dst 192.168.47.11 flowid 1:10
この帯域幅制限は以下のコマンドで削除できます。
# tc qdisc del dev eth0 root handle 1
DRBD Proxy バージョン3には実験的な bwlimit オプションがありますが、DRBD 上のアプリケーションで I/O ブロックが発生する可能性があるため、使用しないでください。
|
6.9. トラブルシューティング
DRBD Proxy バージョン 4 のログは systemd ジャーナルによって収集され、journalctl -u drbd-proxy で確認できます。
デバッグモードを有効にすると、DRBD Proxyはより詳細なログを出力するようになります。これは以下のコマンドで実行できます。
# drbd-proxy-ctl set loglevel debug
例えば、DRBD Proxyが接続に失敗した場合、それに応じたメッセージがログに記録されます。その場合は、両方のノードでDRBDが動作していること(StandAloneモードになっていないこと)、およびプロキシサービスが起動していることを確認してください。また、設定内容についても再確認してください。
7. トラブルシューティングとエラーからの回復
この章では、ハードウェアやシステムに障害が発生した場合に必要な手順について説明します。
7.1. DRBDエラーコードに関する情報の取得
DRBDおよびDRBD管理ツールである drbdadm は、POSIXエラーコードを返します。特定のエラーコード番号について詳細な情報が必要な場合は、環境にPerlがインストールされている場合、次のコマンドを使用できます。例えば、エラーコード番号11について情報を取得するには、次のように入力してください:
# perl -e 'print $! = 11, "\n"' Resource temporarily unavailable
7.2. ハードドライブの障害の場合
ハードドライブの障害への対処方法は、DRBDがディスクI/Oエラーを処理する方法( ディスクエラー処理ストラテジー 参照)、また設定されているメタデータの種類( DRBDメタデータ 参照)によって異なります。
|
ほとんどの場合、ここで取り上げる手順はDRBDを直接物理ハードドライブ上で実行している場合にのみ適用されます。次に示す層の上でDRBDを実行している場合には通常は適用されません。
|
7.2.1. 手動でDRBDをハードドライブから切り離す
DRBDが I/Oエラーを伝えるように設定 (非推奨)している場合、まずDRBDリソースを切り離すとよいでしょう。つまり、下位デバイスからの切り離しです。
# drbdadm detach <resource>
drbdadm status または drbdadm dstate コマンドを実行することで、現在の状態を確認することができます。
# drbdadm status <resource>
<resource> role:Primary
volume:0 disk:Diskless
<peer> role:Secondary
volume:0 peer-disk:UpToDate
# drbdadm dstate <resource>
Diskless/UpToDate
ディスク障害がプライマリノードで発生した場合、スイッチオーバーと、この手順を組み合わせることもできます。
7.2.2. I/Oエラー時の自動切り離し
DRBDが I/Oエラー時に自動的に切り離しを行うように設定 (推奨オプション)されている場合、 手動での操作なしで、DRBDはすでにリソースを下位ストレージから自動的に切り離しているはずです。その場合でも drbdadm status コマンドを使用して、リソースが実際にディスクレスモードで実行されているか確認します。
7.2.3. 障害が発生したディスクの交換(内部メタデータを使用している場合)
<<s-internal-meta-data,内部メタデータ>> を使用している場合、新しいハードディスクでDRBDデバイスを再構成するだけで十分です。交換したハードディスクのデバイス名が交換前と異なる場合は、DRBD設定ファイルを適切に変更してください。
新しいメタデータを作成してから、リソースを再接続します。
# drbdadm create-md <resource> v08 Magic number not found Writing meta data... initialising activity log NOT initializing bitmap New drbd meta data block successfully created. # drbdadm attach <resource>
新しいハードディスクの完全同期がただちに自動的に始まります。通常のバックグラウンド同期と同様、同期の進行状況を drbdadm status --verbose で監視することができます。
7.2.4. 障害の発生したディスクの交換(外部メタデータを使用している場合)
<<s-external-meta-data,外部メタデータ>> を使用している場合でも、手順は基本的に同じです。ただし、DRBDだけではハードドライブが交換されたことを認識できないため、追加の手順が必要です。
# drbdadm create-md <resource> v08 Magic number not found Writing meta data... initialising activity log NOT initializing bitmap New drbd meta data block successfully created. # drbdadm attach <resource> # drbdadm invalidate <resource>
drbdadm invalidate は、必ず破棄するデータのある側のノードでを実行してください。 このコマンドはローカルのデータを対向ノードからのデータで上書きさせます。つまり、このコマンドを実行すると破棄する側のノードのデータが失われます。
|
上記の drbdadm invalidate コマンドが同期をトリガーします。この場合でも、同期の進行状況は drbdadm status --verbose で確認できます。
7.3. ノード障害に対処する
DRBDが(実際のハードウェア障害であれ手動による介入であれ)対向ノードがダウンしていることを検出すると、DRBDは自身のコネクションステータスを Connected から WFConnection に変更し、対向ノードが再び現れるのを待ちます。その後、DRBDリソースは disconnected mode(切断モード) で動作します。切断モードでは、リソースおよびリソースに関連付けられたブロックデバイスが完全に利用可能で、必要に応じて昇格したり降格したりします。ただし、ブロックの変更は対向ノードにレプリケートされません。切断中に変更されたブロックについての内部情報は対向ノードごとにDRBDが格納します。
7.3.1. 一時的なセカンダリノードの障害に対処する
セカンダリロールでリソースを持っているノードに一時的に障害が生じた場合(たとえばメモリ交換で直るようなメモリの問題)には、障害が発生したノードを修復してオンラインに戻すだけで十分です。修正したノードを起動すると、ノード間の接続が再確立され、停止中にプライマリノードに加えられた変更内容すべてがセカンダリノードに同期されます。
| この時点で、DRBDの再同期アルゴリズムの性質により、セカンダリノードのリソースの一貫性が一時的に失われます。この短時間の再同期の間は、対向ホストが使用できない場合でも、セカンダリノードをプライマリロールに切り替えることができません。したがって、セカンダリノードの実際のダウンタイムとその後の再同期の間は、クラスタが冗長性を持たない期間になります。 |
DRBD9では各リソースに3ノード以上が接続することができます。そのため、例えば4ノードでは一度フェイルオーバしてもまだ2回フェイルオーバすることができます。
7.3.2. 一時的なプライマリノードの障害に対処する
DRBDからみると、プライマリノードの障害とセカンダリノードの障害はほぼ同じです。生き残ったノードが対向ノードの障害を検出し、切断モードに切り替わります。DRBDは生き残ったノードをプライマリロールに 昇格しません 。これはクラスタ管理システムが管理します。
障害が発生したノードが修復されてクラスタに戻る際に、セカンダリロールになります。すでに述べたように、それ以上の手動による介入は必要ありません。このときもDRBDはリソースのロールを元に戻しません。変更を行うように設定されている場合は、クラス管理システムがこの変更を行います。
プライマリノードに障害が発生すると、DRBDはアクティビティログというメカニズムによってブロックデバイスの整合性を確保します。詳細は アクティビティログ を参照ください。
7.3.3. 永続的なノード障害に対処する
ノードに回復不能な問題が発生した場合やノードが永久的に破損した場合は、次の手順を行う必要があります。
-
障害が発生したハードウェアを同様のパフォーマンスと ディスク容量を持つハードウェアと交換します。
障害が発生したノードを、それよりパフォーマンスが低いものと置き換えることも可能ですが、お勧めはできません。障害が発生したノードを、それよりディスク容量が小さいものと置き換えることはできません。このような場合には、DRBDを置き換えたノードへの接続は拒否されます。[9] -
OSとアプリケーションをインストールします。
-
DRBDをインストールし、生き残ったノードから
/etc/drbd.confと、全ての/etc/drbd.d/を コピーします。
この時点で、デバイスの完全同期を手動で開始する必要はありません。生き残ったプライマリノードへの接続時に、同期が自動的に開始します。
7.4. スプリットブレインからの手動回復
ノード間の接続が可能になると、ノード間で初期ハンドシェイクのプロトコルが交換されます。この時点でDRBDはスプリットブレインが発生したかどうかを判断できます。両方のノードがプライマリロールであるか、もしくは切断中に両方がプライマリロールになったことを検出すると、DRBDは即座にレプリケーション接続を切断します。その場合、システムログにたとえば次のようなメッセージが記録されます。
Split-Brain detected, dropping connection!
スプリットブレインが検出されると、1つのノードは常に StandAlone の状態でリソースを保持します。もう一方のノードもまた StandAlone 状態になる(両方のノードが同時にスプリットブレインを検出した場合)、または WFConnection 状態になります(一方のノードがスプリットブレインを検出する前に対向ノードが切断をした場合)。
DRBDがスプリットブレインから自動的に回復するように設定されていない場合は、この時点で手動で介入して、変更内容を破棄するほうのノードを選択する必要があります(このノードは スプリットブレインの犠牲ノード と呼ばれる)。この介入は次のコマンドで行います。
# drbdadm disconnect <resource> # drbdadm secondary <resource> # drbdadm connect --discard-my-data <resource>
他方のノード(スプリットブレインの生存ノード)のコネクションステータスも StandAlone の場合には、次のコマンド実行します。
# drbdadm disconnect <resource> # drbdadm connect <resource>
ノードがすでに Connecting の状態の場合は自動的に再接続するので、この手順は省略できます。
接続すると、スプリットブレインの犠牲ノードのコネクションステータスがすぐに SyncTarget に変化し、他のノードによって変更内容が上書きされます。
| スプリットブレインの犠牲ノードは、デバイスのフル同期の対象にはなりません。代わりに、ローカル側での変更がロールバックされ、スプリットブレインの生存ノードに対して加えられた変更が犠牲ノードに伝播されます。 |
再同期が完了すると、スプリットブレインが解決したとみなされ、2つのノードが再び完全に一致した冗長レプリケーションストレージシステムとして機能します。
7.5. クォーラムを失ったプライマリノードの回復
| 次の手順は、DRBD のクォーラム喪失時のアクションが I/O 操作を一時停止するように設定されている場合に適用されます。アクションが I/O エラーを生成するように設定されている場合は必要ありません。 |
DRBD 管理ツール drbdadm には、強制セカンダリオプション secondary --force が含まれています。 DRBD クォーラム喪失時のアクションが I/O 操作を一時停止するように構成されている場合、force secondary オプションを使用すると、クォーラムを失ったノードを正常に回復し、他のノードと再統合できます。
要件:
-
DRBD バージョン 9.1.7 以降
-
drbd-utilsバージョン 9.21 以降
クォーラムを失ったプライマリノードを回復させる場合、コマンド drbdadm secondary --force <all|resource_name> を使用して、プライマリノードをセカンダリに降格できます。このコマンドの引数は、単一の DRBD リソース名か、すべての DRBD リソースをセカンダリロールにノードを降格させる all のいずれかです。
クォーラムを失い中断された I/O 操作を伴うプライマリノードでこのコマンドを使用すると、中断されたすべての I/O 要求と新しく送信された I/O 要求が I/O エラーで終了します。その後、通常はファイル システムをアンマウントし、ノードをクラスター内の他のノードに再接続できます。例外は、I/O をまったく行わずにアイドル状態になるだけのファイルシステムオープナーです。このようなプロセスは、アンマウントが成功する前に手動で削除するか、 fuser -k などの外部ツールやクラスター化されたセットアップの OCF ファイル システム リソースエージェントを使用して削除する必要があります。
DRBD 管理ツールの強制セカンダリオプションに加えて、 on-suspended-primary-outdated オプションを DRBD リソース構成ファイルに追加し、キーワード値 force-secondary を設定することもできます。また、リソースロールの競合 (rr-conflict) オプションを DRBD リソース構成ファイルの net セクションに追加し retry-connect に設定することも必要です。これにより、DRBD は、中断された I/O 操作でクォーラムを失ったプライマリ ノードを自動的に回復できます。これらのオプションを設定すると、そのようなノードがより新しいデータセットを持つクラスターパーティションに接続すると、DRBD はクォーラムを失い、I/O 操作を中断したプライマリノードを自動的に降格させます。リソース構成ファイルの handlers セクションなどの追加構成や、クラスターマネージャー内の追加構成も、完全に自動化された復旧セットアップを完了するために必要になる場合があります。
このシナリオをカバーする DRBD リソース構成ファイルの options セクション内の設定は、次のようになります。
resource <resource_name> {
net {
rr-conflict retry-connect;
[...]
}
options {
quorum majority; # or explicit value
on-no-quorum suspend-io;
on-no-data-accessible suspend-io;
on-suspended-primary-outdated force-secondary;
[...]
}
[...]
}
DRBDとアプリケーションの組み合わせ
8. DRBD Reactor
DRBD Reactor は、DRBDイベントを監視し、それらに対応するデーモンです。DRBD Reactor は、内部で systemd を使用して DRBD イベントに反応します。DRBD Reactor は systemd ユニットを生成および使用して、クラスター内のノードでサービスを開始または停止できます。これには、ファイルシステムのマウント、データベースサービスの開始、Open Cluster Framework (OCF) リソースエージェントの実行などが含まれます。
DRBD Reactorは、DRBDのリソースやメトリクスの監視から、フェイルオーバクラスターの構築、さらには通常なら複雑なクラスターリソースマネージャー(CRM)を使用して設定する必要がある高可用性サービスの提供まで、多岐にわたる用途に対応しています。
8.1. DRBD Reactorのインストール
DRBD Reactorは、https://github.com/LINBIT/drbd-reactor[DRBD Reactorソースコードリポジトリ]にあるソースファイルからインストールできます。詳細および前提条件については、そちらの指示を参照してください。
また、LINBITのお客様は、LINBITの`drbd-9`パッケージリポジトリで提供されている公式サポートのビルド済みパッケージから、DRBD Reactorをインストールすることも可能です。
DRBD Reactorのパッケージは、最新の2つのLTS Ubuntuリリース向けに、LINBIT PPAでも提供されています。
| LINBIT PPAは、ホームラボ、テスト、またはその他の本番環境以外での使用には優れた選択肢となりますが、LINBITはこのパブリックレポジトリ内のパッケージに対して、いかなる保証、サポート、またはSLAも提供しません。本番環境やエンタープライズ環境へのデプロイメントには、公式のLINBIT顧客用レポジトリの使用を推奨します。 |
インストール後、 drbd-reactor --version コマンドを使用して、DRBD Reactor のバージョン番号を確認できます。
8.2. DRBD Reactor のコンポーネント
DRBD Reactorはさまざまな用途があるため、コアコンポーネントとプラグインコンポーネントに分割されました。
8.2.1. DRBD Reactor コア
DRBD Reactorの中核コンポーネントは、DRBDイベントを収集し、整形して、それらをDRBD Reactorプラグインに送信する役割を担っています。
コアは新しい設定や追加の更新された設定で再読み込みできます。必要ないプラグインインスタンスを停止し、新しいプラグインスレッドを開始することができ、DRBDイベントを失わずに行えます。そして最後に、コアはプラグインが初期状態および完全なDRBDの状態を受け取ることを確認しなければなりません。
8.2.2. DRBD Reactor プラグイン
プラグインは、DRBD Reactorの機能を提供し、異なる用途に対応するために異なるプラグインが存在します。プラグインは、コアコンポーネントからメッセージを受信し、メッセージの内容に基づいてDRBDリソースに対してプラグインの種類と構成に従って動作します。
プラグインは複数回インスタンス化することができ、クラスター内には各プラグインタイプのインスタンスを多数持たせることが可能です。例えば、高可用性クラスターでは、DRBDリソースごとに1つずつ、多数のプロモータープラグインのインスタンスが存在する場合があります。
8.2.3. Promoter プラグイン
promoterプラグインは、DRBD Reactorの機能の中でも間違いなく最も重要で便利な機能です。他のより複雑なクラスターリソースマネージャー(CRM)を使用するよりも簡単に、高可用性サービスを運用するフェイルオーバクラスターを作成できます。すぐに使い始めたい場合は、このセクションを読み終えた後、Promoter プラグインの設定 までスキップしてください。その後、演習例として DRBD Reactorのpromoterで高可用性ファイルシステムをマウントする セクションの手順を試すことができます。
プロモータープラグインはDRBDリソースのイベントを監視し、systemdユニットを実行します。このプラグインにより、DRBD Reactorはクラスタにフェイルオーバ機能を提供して高可用性展開を作成することができます。DRBD Reactorおよびそのプロモータープラグインは、軽量さと構成の簡素さが利点となる多くのシナリオで、Pacemakerなど他のCRMの代替として使用できます。
例えば、プロモータープラグインを使用して、孤立したプライマリノードの完全自動回復を設定することができます。さらに、Corosyncなどの別個の通信レイヤーは必要ありません。なぜなら、DRBDとDRBDリアクター(CRMとして使用される)は常にノードのクォーラム状態について合意するからです。
PacemakerなどのCRMと比較してPromoterプラグインの欠点は、配置に独立した順序制約を作成することができないという点です。例えば、ウェブサービスとデータベースが異なるノードで実行されている場合、Pacemakerはウェブサービスがデータベースの後に起動するよう制約を設定できますが、DRBD ReactorとそのPromoterプラグインではできません。
Promoter プラグインの仕組み
promoterプラグインの主な機能は、DRBDデバイスが昇格可能な場合に、そのデバイスを_Primary_に昇格させ、ユーザー定義の一連のサービスを開始することです。これには、例えば次のような一連のサービスが含まれます。
-
DRBD デバイスを昇格する。
-
デバイスをマウントポイントにマウントする。
-
マウントポイントにあるデータベースを使用するデータベースを起動します。
リソースがクォーラムを失うと、DRBD Reactorはこれらのサービスを停止し、クォーラムが残っている別のノード(またはクォーラムを失ったノードがクォーラムを回復したとき)がサービスを開始できるようにします。
これらの例のような systemd サービスに加えて、promoter プラグインは OCF リソースエージェント をサポートしています。例えば、ノード上に仮想 IP アドレスを作成できる IPaddr2 リソースエージェントを開始するように promoter プラグインを構成できます。これにより、クラスター内のどのノードでサービスが実行されていても、一貫した IP アドレスを通じてサービスにアクセスできるようになります。また、promoter プラグインは、リソースの demote に失敗した場合にノードを再起動するなどの障害アクションもサポートしており、別のノードでリソースを promote できるようにします。
`drbd-reactor.promoter`のマニュアルページでは、プロモータープラグインがノード上でのサービスの実行を開始またはブロックするために背後で使用しているメカニズムとロジックについて、詳細に説明しています。
8.2.4. ユーザーモードヘルパー(UMH)プラグイン
このプラグインおよびその固有のドメイン固有言語(DSL)を使用すると、定義したイベントが発生した場合にスクリプトを実行することができます。例えば、DRBDリソースが接続を失ったときにSlackメッセージを送信するスクリプトを実行できます。
この機能は以前から、DRBDにおいて「カーネル空間」での「ユーザー定義ヘルパースクリプト」によって存在していました。しかし、UMHプラグインを含むDRBD Reactorは「ユーザースペース」で実行することができます。これにより、より簡単にコンテナの展開が可能となり、コンテナディストリビューション内で見られる「読み取り専用」ホストファイルシステムとの組み合わせも容易になります。
UMHプラグインを使用することで、ユーザー定義のヘルパースクリプトを使用することよりも以前にはできなかった利点が得られます。今や、DRBDリソースで可能なすべてのイベントに対して独自のルールを定義できます。カーネルでイベントハンドラが存在するわずかなイベントに限定されることはもはやありません。
UMHプラグインスクリプトには、2つのタイプがあります。
-
ユーザー定義フィルター。これは、あるイベントが発生するとスクリプトが起動する「ワンショット」UMHスクリプトです。
-
ヘルパーの置き換えと呼ばれるカーネル。このタイプのスクリプトは現在開発中です。これらは、カーネルとの通信を必要とするUMHスクリプトです。イベントがスクリプトをトリガーしますが、スクリプト内のアクションは、カーネルのアクションの失敗または成功に基づいて、スクリプトが次のアクションを取ることができるように、カーネルがスクリプトに通信を返すことを必要とします。このようなスクリプトの例としては、
before-resync-targetアクティベート スクリプトがあります。
8.2.5. Prometheusモニタリングプラグイン
このプラグインは、さまざまなDRBDメトリクス(例:同期されていないバイト、リソースの役割(たとえば、プライマリ)、および接続状態(たとえば、接続済み)を公開する、 Prometheus 互換のエンドポイントを提供します。この情報は、Prometheusエンドポイントをサポートするすべての監視ソリューションで使用できます。すべてのメトリクスと例としてのGrafanaダッシュボードは、 DRBD ソースコード GitHubリポジトリで提供されています。
8.2.6. SNMPモニタリングのためのAgentXプラグイン
このプラグインは、SNMPのためのAgentXサブエージェントとして機能し、さまざまなDRBDメトリクスを公開します。たとえば、SNMPを介してDRBDリソースを監視するために使用されます。AgentXは、SNMPデーモンとAgentXプラグインのようなサブエージェントの間で使用できる標準化されたプロトコルです。
このプラグインがSNMPデーモンに公開するDRBDメトリクスは、https://github.com/LINBIT/drbd-reactor/blob/master/doc/agentx.md#metrics[DRBD Reactorソースコードリポジトリ]に記載されています。
8.3. DRBD Reactor の構成
DRBD Reactorを実行するには、事前に設定を行う必要があります。グローバル設定は、メインのTOML設定ファイルである /etc/drbd-reactor.toml で行います。このファイルは、有効なTOML形式(https://toml.io)である必要があります。プラグインの設定はTOML形式のスニペットファイルで行い、それらのファイルはデフォルトのディレクトリ /etc/drbd-reactor.d、またはメインの設定ファイルで指定した別のディレクトリに配置してください。
この設定ファイルの例には、解説を目的としてプラグインの設定例も含まれています。ただし、実際のデプロイ時には、プラグインの設定には必ずスニペットファイルを使用してください。
8.3.1. DRBD Reactorのコアの設定
DRBD Reactorコアコンポーネントの設定ファイルは、グローバル設定とログレベル設定で構成されています。
グローバル設定には、スニペットディレクトリの指定、統計更新のポーリング間隔の指定、およびログファイルのパスの指定が含まれます。また、設定ファイル内でログレベルを trace、debug、info、warn、error、off のいずれかに設定することも可能です。デフォルトのログレベルは「info」です。
これらの設定のシンタックスについては、 drbd-reactor.toml のマニュアルページを参照してください。
8.3.2. DRBD Reactorプラグインの設定
DRBD Reactorプラグインの設定は、TOML形式のスニペットファイルを編集することで行います。DRBD Reactorデーモンのリロード時、新しい設定にも引き続き存在する起動済みのプラグインは、停止することなく実行を継続します。
8.3.3. Promoter プラグインの設定
通常、DRBD Reactorとプロモータープラグインが監視および管理する各DRBDリソースにつき1つのスニペットファイルがあるでしょう。
以下はPromoter プラグインの設定スニペットの例です。
[[promoter]] [promoter.resources.my_drbd_resource] (1) dependencies-as = "Requires" (2) target-as = "Requires" (3) start = ["path-to-my-file-system-mount.mount", "foo.service"] (4) on-drbd-demote-failure = "reboot" (5) secondary-force = true (6) preferred-nodes = ["nodeA", "nodeB"] (7) preferred-nodes-policy = always (8)
| 1 | “my_drbd_resource”は、DRBD Reactorとプロモータープラグインが監視して管理すべきDRBDリソースの名前を指定しています。 |
| 2 | サービス間依存関係を生成するための systemd 依存関係の種類を指定します。 |
| 3 | 最終的なターゲットユニットでサービスの依存関係を生成するための systemd の依存関係のタイプを指定します。 |
| 4 | start は、監視されているDRBDリソースが昇格可能になったときに何を開始するかを指定します。この例では、昇格プラグインはファイルシステムのマウントユニットとサービスユニットを開始します。 |
| 5 | DRBDリソースが降格に失敗した場合に取るべきアクションを指定します (クォーラム損失イベント後など)。この場合、降格に失敗したノードに対して、そのノードの「セルフフェンス」を作動させ、別のノードを昇格させるようなアクションを実行する必要があります。アクションは、reboot, reboot-force, reboot-immediate, poweroff, poweroff-force, poweroff-immediate, exit, exit-force のいずれかになります。 |
| 6 | ノードがクォーラムを失うと、DRBD Reactorはそのノードをセカンダリロールに降格させようとします。リソースがクォーラムを失ったときにI/O操作を中断するように設定されている場合、この設定は、drbdadm のforce secondary機能を使ってノードをセカンダリロールに降格させるかどうかを指定します。詳細については、DRBDユーザーズガイドの クォーラムを失ったプライマリノードの回復 セクションを参照してください。この設定が指定されていない場合は、”true “がデフォルトのオプションです。ここでは説明のために指定されています。 |
| 7 | 設定された場合、可能であれば指定された順序で、優先ノードでリソースが開始される。 |
| 8 | DRBD Reactor v1.9.0 以降、優先ノードポリシーとして always(指定がない場合のデフォルト)または start-only を設定できるようになりました。start-only 優先ノードポリシーを設定することで、promoter プラグインで構成されたサービスは、すでに優先度の低いノードで実行されている場合、より優先度の高いノードにフェイルバックしなくなります。常に特定のノードでサービスを実行しようとすることよりも、サービスの切断を最小限に抑えることを優先する場合、この「自動スイッチバック」動作を回避することが役立つ可能性があります。 |
Promoterプラグインの設定や背景に関する詳細については、`drbd-reactor.promoter`のマニュアルページを参照してください。
Promoter 開始リストでの複数行にわたるサービス文字列の指定
フォーマットや可読性の向上のため、プロモータープラグインのスニペットファイルにあるサービス開始リスト内の長いサービス文字列を、複数行に分割して記述することができます。これには、TOMLの複数行基本文字列の構文を使用します。以下の例では、サービス開始リストの1番目と3番目のサービス文字列を複数行に分割する方法を示しています。TOMLの複数行基本文字列において、行末にバックスラッシュ(\)を置くことで、文字列内に改行文字が挿入されないように記述できます。
[...] start = [ """ ocf:heartbeat:Filesystem fs_mysql device=/dev/drbd1001 \ directory=/var/lib/mysql fstype=ext4 run_fsck=no""", "mariadb.service", """ocf:heartbeat:IPaddr2 db_virtip ip=192.168.222.65 \ cidr_netmask=24 iflabel=virtualip""" ] [...]
| この技術を使用して、他のプラグインスニペットファイル内の長い文字列を分割することもできます。 |
リソースフリーズの設定
DRBD Reactor バージョン 0.9.0 からは、Promoter プラグインを設定して、DRBD Reactor が制御しているリソース を、現在アクティブなノードが独立権を失った時に停止させるのではなく、「フリーズ」できるようになりました。ノードが再び独立権を回復しアクティブになった場合、DRBD Reactor はリソースを再開させる代わりに「解凍」することができ ます。それにより、リソースを再起動する必要がなくなります。
ほとんどの場合、デフォルトの停止と開始の動作が優先されますが、フリーズと再開の構成は、起動に時間がかかるリソース (たとえば、大規模なデータベースなどのサービスを含むリソース) に役立つ場合があります。そのようなクラスターで Primary ノードがクォーラムを失い、残りのノードがクォーラムでパーティションを形成できない場合、リソースのフリーズが役立つ可能性があります。ネットワークの問題. フリーズしたリソースを持つ以前の Primary ノードがピアノードに再接続すると、ノードは再び Primary になり、DRBD Reactor はリソースを再開します. この動作の結果、リソースは数秒で再び利用可能になる可能性があります。リソースは停止状態から開始する必要がなく、フリーズ状態から再開するだけで済みました。
要件:
リソースのために Promoter プラグインの凍結機能を設定する前に、次のものが必要です:
-
cgroup v2 を使用し、統合された cgroup を実装するシステム。これは、システムに「/sys/fs/cgroup/cgroup.controllers」が存在することで確認できます。これが存在せず、カーネルがサポートしている場合は、カーネル コマンド ライン引数
systemd.unified_cgroup_hierarchy=1を追加して、この機能を有効にできるはずです。これは、RHEL 8、Ubuntu 20.04、およびそれ以前のバージョンにのみ関連するはずです。 -
リソース用に構成された次の DRBD オプション:
-
on-no-quorumをsuspend-ioにセット; -
on-no-data-accessibleをsuspend-ioにセット; -
on-suspended-primaryをforce-secondaryにセット; -
rr-conflict(netoption) をretry-connectにセット;
-
-
フリーズ(一時停止)とスロー(再開)に対応可能なリソース。
systemctl freeze <systemd_unit>およびsystemctl thaw <systemd_unit>コマンドを使用することで、リソース(およびそのリソースに依存するすべてのアプリケーション)がフリーズとスローにどのように反応するかをテストできます。ここでは、promoterプラグイン設定のサービス起動リストに対応するsystemdユニットを指定します。これらのコマンドを使用して、依存関係にあるサービスがフリーズおよびスローされた後にアプリケーションがどのように動作するかを確認できます。リソースとアプリケーションがフリーズに耐えられるかどうかわからない場合は、デフォルトの停止と開始の動作を維持する方が安全です。
リソースの凍結を設定するには、DRBD リアクター リソースのプロモーター プラグイン スニペット ファイルに次の行を追加してください。
on-quorum-loss = "freeze"
Promoter プラグインで OCF リソースエージェントを利用する
Promoter プラグインを設定して、サービスの start リストで OCF リソース エージェントを使用することもできます。
LINBIT の顧客または評価アカウントをお持ちの場合は、LINBIT の drbd-9 パッケージ リポジトリで利用可能な resource-agents パッケージをインストールして、”Filesystem” OCF リソース エージェントを含むリソース エージェントスクリプトをインストールできます。
|
OCF リソースエージェントを start リスト内のサービスとして指定するためのシンタックスは ocf:$vendor:$agent instance-id [key=value key=value …] となります。ここで、instance-id はユーザー定義で、key=value のペアは、指定された場合、作成される systemd ユニットファイルに環境変数として渡されます。例えば
[[promoter]] [...] start = ["ocf:heartbeat:IPaddr2 ip_mysql ip=10.43.7.223 cidr_netmask=16"] [...]
Promoterプラグインは、 /usr/lib/ocf/resource.d/ ディレクトリ内のOCFリソースエージェントを想定しています。
|
systemdマウントユニットとOCF Filesystemリソースエージェントの使い分け
DRBD ReactorとそのPromoterプラグインを利用するほとんどのシナリオでは、おそらくファイルシステムのマウントが含まれるでしょう。もし、Promoterの起動リストにファイルシステムのマウント以外のサービスやアプリケーションが含まれる場合は、systemdのマウントユニットを使用してファイルシステムのマウントを処理すべきです。
ただし、ファイルシステムのマウントポイントが最終目標である場合、つまり、それがあなたの Promoter プラグインのサービス開始リストの最後になる場合は、systemd のファイルシステムマウントユニットを使用しないでください。代わりに、OCF Filesystem リソースエージェントを使用してファイルシステムのマウントとアンマウントを処理してください。
この場合、OCFリソースエージェントを使用することが好ましいです。リソースエージェントは、マウントポイントを保持している可能性のあるプロセスに対して kill アクションやその他のさまざまなシグナルを使ってノードのダウングレードを行うことができます。例えば、systemdが知らないファイルシステム内のファイルに対してアプリケーションを実行しているユーザーがいるかもしれません。その場合、systemdはファイルシステムをアンマウントできず、Promoterプラグインはノードをダウングレードできません。
詳細は、 DRBD Reactor GitHub ドキュメント にあります。
8.3.4. ユーザーモードヘルパー(UMH)プラグインの設定
このプラグインの構成は以下の通りです:
-
ルールタイプ
-
実行するコマンドまたはスクリプト
-
ユーザー定義環境変数(オプション)
-
DRBDリソース名、イベントタイプ、または状態変化に基づくフィルタリング
ルールを定義できるDRBDの種類は4つあります。 resource, device, peerdevice, or connection.
それぞれのルールタイプに対して、sh -c を使って実行するコマンドやスクリプト、および任意のユーザ定義環境変数を設定することができます。ユーザ定義の環境変数は、一般的に設定されているものに加えて、次のようなものがあります。
-
HOME
/ -
TERM
Linux -
PATH
/sbin:/usr/sbin:/bin:/usr/bin
UMHルールの種類をDRBDリソース名またはイベントタイプ(存在、作成、破棄、変更)でフィルタリングすることも可能です。
最後に、プラグインのアクションを DRBD の状態変化に基づいてフィルタリングできます。フィルタは、プラグインに報告される過去の状態と新しい(現在の)DRBDの状態の両方に基づいている必要があります。なぜなら、プラグインが変更に反応するようにしたいからです。このような場合、古い状態と新しい状態を両方フィルタリングすることで、プラグインが無作為にトリガーされるのを防ぐことができます。たとえば、新しい(現在の)DRBDの役割だけをフィルタリング対象として指定した場合、新しい役割が古いDRBDの役割と同じ場合でもプラグインがトリガーされる可能性があります。
こちらは、resource ルールのための UMH プラグインの設定スニペットの例です:
[[umh]]
[[umh.resource]]
command = "slack.sh $DRBD_RES_NAME on $(uname -n) from $DRBD_OLD_ROLE to $DRBD_NEW_ROLE"
event-type = "Change"
resource-name = "my-resource"
old.role = { operator = "NotEquals", value = "Primary" }
new.role = "Primary"
この例のUMHプラグインの設定は、resource-name 値が my-resource で指定されたDRBDリソースから受け取った変更イベントメッセージに基づいています。
リソースの以前のロールがPrimaryではなく、現在の新しいロールがPrimaryである場合、後に続く引数を伴って`slack.sh`という名前のスクリプトが実行されます。フルパスが指定されていないため、このスクリプトはホストマシン(コンテナで実行している場合はそのコンテナ)の一般的な`PATH`環境変数(/sbin:/usr/sbin:/bin:/usr/bin)が通った場所に存在する必要があります。このスクリプトは、リソースのロール変更を通知するためにSlackチャンネルへメッセージを送信するものと推測されます。コマンド文字列内で指定された変数は、プラグイン設定の他の場所で指定された値に基づいて置換されます。例えば、resource-name`で指定された値は、コマンド実行時に$DRBD_RES_NAME`に置換されます。
上記の設定例では、指定された演算子 “NotEquals” を使用して、old.role の値 “Primary” が真であるかどうかを評価しています。演算子を指定しない場合は、設定例の new.role = "Primary" フィルタのように、デフォルトの演算子は “Equals” となります。
|
UMHプラグインの設定では、さらに多くのルール、フィールド、フィルタの種類、および変数を指定できます。詳細、解説、例、注意事項については、DRBD Reactorソースコードリポジトリ内のhttps://github.com/LINBIT/drbd-reactor/blob/master/doc/umh.md[UMHドキュメントページ]を参照してください。
8.3.5. Prometheus プラグインの設定
このプラグインは、DRBDの接続状態、DRBDデバイスのクォーラム(定足数)の有無、未同期のバイト数、TCP送信バッファの輻輳の兆候など、DRBDの監視メトリクスを提供するPrometheus互換のHTTPエンドポイントを提供します。メトリクスの完全なリストや詳細については、`drbd-reactor.prometheus`のマニュアルページを参照してください。
8.3.6. SNMP 監視のための AgentX プラグインの設定
AgentXプラグインの設定には、公開されるDRBDメトリクスを定義するSNMP管理情報ベース(MIB)のインストール、SNMPデーモンの設定、AgentXプラグイン用のDRBDリアクター設定スニペットファイルの編集が含まれます。
| すべての DRBD Reactor ノードで次のセットアップ手順を完了する必要があります。 |
前提条件
このプラグインを設定して、さまざまな DRBD のメトリクスを SNMP デーモンに公開する前に、もしまだインストールされていない場合は、以下のパッケージをインストールする必要があります。
RPMベースのシステム向け:
dnf -y install net-snmp net-snmp-utils
DEBベースのシステム向け:
apt -y install snmp snmpd
LINBITのMIBに対してSNMPコマンドを使用する際にMIBが見つからないエラーが発生した場合、不足しているMIBをダウンロードする必要があります。これを手動で行うか、snmp-mibs-downloader DEBパッケージをインストールして行うことができます。
|
LINBIT DRBD Management Information Baseのインストール
AgentXプラグインを使用するには、LINBIT社のDRBD MIBを /usr/share/snmp/mibs にダウンロードしてください。
curl -L https://github.com/LINBIT/drbd-reactor/raw/master/example/LINBIT-DRBD-MIB.mib \ -o /usr/share/snmp/mibs/LINBIT-DRBD-MIB.mib
SNMP デーモンの設定
SNMPサービスのデーモンを設定するには、その設定ファイル(/etc/snmp/snmpd.conf)に以下の行を追加してください。
# add LINBIT ID to the system view and enable agentx view systemview included .1.3.6.1.4.1.23302 master agentx agentXSocket tcp:127.0.0.1:705
使用するビュー名が SNMP 構成ファイルで適切に設定されているビュー名と一致しているかを確認してください。上記の例では、RHEL 8 システムで使用されているビュー名が systemview であることが示されています。Ubuntu の場合、ビュー名は異なる可能性があり、例えば Ubuntu 22.04 では systemonly となります。
|
次に、サービスを有効にして開始します(または既に有効かつ実行中の場合はサービスを再起動します)。
systemctl enable --now snmpd.service
AgentXプラグインの構成スニペットファイルの編集
AgentXプラグインは、DRBD Reactorスニペットファイルでの最小限の構成のみを必要とします。次のコマンドを入力して、構成スニペットファイルを編集してください。
drbd-reactorctl edit -t agentx agentx
その後、以下の行を追加してください。
[[agentx]] address = "localhost:705" cache-max = 60 # seconds agent-timeout = 60 # seconds snmpd waits for an answer peer-states = true # include peer connection and disk states
|
systemctl reload drbd-reactor.service |
AgentX プラグインの動作確認
AgentXプラグインの動作を確認する前に、次のコマンドを入力して、SNMPサービスが標準の、プリインストールされたMIBを公開しているかを最初に確認してください。
snmpwalk -Os -c public -v 2c localhost iso.3.6.1.2.1.1.1
コマンドの出力は以下のようになります。
sysDescr.0 = STRING: Linux linstor-1 5.14.0-284.30.1.el9_2.x86_64 #1 SMP PREEMPT_DYNAMIC Fri Aug 25 09:13:12 EDT 2023 x86_64
次に、drbd-reactorctl status コマンドの出力に AgentX プラグインが表示されているか確認してください。
/etc/drbd-reactor.d/agentx.toml: AgentX: connecting to main agent at localhost:705 [...]
次に、以下のコマンドを入力して LINBIT MIB テーブルの構造を表示してください。
snmptranslate -Tp -IR -mALL linbit
最後に、snmptable コマンドを使用して、現在のDRBDセットアップおよびリソースに保持されている値のテーブルを表示できます。以下は例として、LINBIT MIB内の`enterprises.linbit.1.2` (enterprises.linbit.drbdData.drbdTable) オブジェクト識別子(OID)でDRBDリソースの値を表示するコマンドを示しています。
snmptable -m ALL -v 2c -c public localhost enterprises.linbit.1.2 | less -S
AgentXプラグインをLINSTORと共に使用する
DRBD ReactorとそのAgentXプラグインを使用してLINSTORが作成したDRBDリソースを操作している場合は、これらのDRBDリソースが1ではなく1000のマイナーナンバーから開始することに注意してください。したがって、特定のノードで最初にLINSTORが作成したリソースのDRBDリソース名を取得するためには、次のコマンドを入力してください。
snmpget -m ALL -v 2c -c public localhost .1.3.6.1.4.1.23302.1.2.1.2.1000
コマンドの出力は以下のようになります。
LINBIT-DRBD-MIB::ResourceName.1000 = STRING: linstor_db
8.4. DRBD Reactor CLIユーティリティの使用法
DRBDリアクターCLIユーティリティである drbd-reactorctl を使用して、DRBDリアクターデーモンとそのプラグインを制御することができます。
| このユーティリティは、プラグインの断片にのみ適用されます。メインの構成ファイル内にある既存のプラグインの設定(推奨されずサポートされない)は、スニペットディレクトリ内のスニペットファイルに移動する必要があります。 |
drbd-reactorctl ユーティリティを使うと、次のことができます。
-
drbd-reactorctl statusコマンドを使用して、DRBD Reactorデーモンと有効になっているプラグインの状態を取得してください。 -
既存のプラグイン設定を編集するか、新しいプラグイン設定を作成するには、
drbd-reactorctl edit -t <plugin_type> <plugin_file>コマンドを使用します。 -
drbd-reactorctl cat <plugin_file>コマンドを使用して、指定されたプラグインの TOML 構成を表示します。 -
drbd-reactorctl enable|disable <プラグインファイル>コマンドを使用して、プラグインを有効または無効にできます。 -
drbd-reactorctl evict <プラグインファイル>コマンドを使用して、ノードからPromoterプラグインリソースを削除します。 -
指定されたプラグイン(またはプラグインが指定されていない場合は DRBD リアクターデーモン)を
drbd-reactorctl restart <plugin_file>コマンドを使用して再起動します。既存のプラグインを削除してデーモンを再起動するには、drbd-reactorctl rm <plugin_file>コマンドを使用します。 -
`drbd-reactorctl rm`コマンドを使用して、指定したDRBD Reactorプラグインを削除し、DRBD Reactorデーモンをリロードします。
-
drbd-reactorctl ls [--disabled]コマンドを使用して、アクティブ化されたプラグインをリストアップするか、オプションで無効化されたプラグインをリストアップします。 -
`drbd-reactorctl start-until`コマンドを使用して、promoterプラグインの開始リストに含まれるサービスの一部を起動します。
上記のアクションのいくつかをより細かく制御するために、追加のオプションが用意されています。 drbd-reactorctl の man ページに詳細とシンタックス情報があります。
8.4.1. DRBD Reactorプラグインの設定
drbd-reactorctl status コマンドを使用すると、ノードで有効になっている DRBD Reactor プラグインのステータスを表示できます。プラグインスニペットファイルの名前(拡張子 .toml の有無は問いません)を指定することで、そのステータスのみを表示できます。また、複数のプラグインスニペットファイルを指定して、それぞれのステータスを表示することも可能です。プラグインスニペットファイル名を指定しなかった場合、ノード上のすべての有効なプラグインのステータスが表示されます。
`drbd-reactorctl status`コマンドによる以下の出力例は、あるノード上で有効化されている2つのプラグイン(promoterプラグインとPrometheusプラグイン)の状態を示しています。
/etc/drbd-reactor.d/nfs.toml: Promoter: Currently active on this node ● [email protected] ● ├─ [email protected] ● ├─ ocf.rs@portblock_nfs.service ● ├─ ocf.rs@fs_cluster_private_nfs.service ● ├─ ocf.rs@fs_1_nfs.service ● ├─ ocf.rs@fs_2_nfs.service ● ├─ ocf.rs@nfsserver_nfs.service ● ├─ ocf.rs@export_drbd_nfs_vol1_nfs.service ● ├─ ocf.rs@export_drbd_nfs_vol2_nfs.service ● ├─ ocf.rs@virtual_ip_nfs.service ● └─ ocf.rs@portunblock_nfs.service /etc/drbd-reactor.d/prom.toml: Prometheus: listening on :9942
この出力では、緑色の塗りつぶされた円は、promoterプラグインによって設定されたサービスユニットがそのノードで実行中であることを示します。白抜きの円は、サービスは設定されているものの、そのノードでは実行されていないことを示しています。これは、別のノードで同じ drbd-reactorctl status コマンドを実行した際の以下の出力例に示す通りです。
/etc/drbd-reactor.d/nfs.toml: Promoter: Currently active on node 'node-0' ○ [email protected] ○ ├─ [email protected] ○ ├─ ocf.rs@portblock_nfs.service ○ ├─ ocf.rs@fs_cluster_private_nfs.service ○ ├─ ocf.rs@fs_1_nfs.service ○ ├─ ocf.rs@fs_2_nfs.service ○ ├─ ocf.rs@nfsserver_nfs.service ○ ├─ ocf.rs@export_drbd_nfs_vol1_nfs.service ○ ├─ ocf.rs@export_drbd_nfs_vol2_nfs.service ○ ├─ ocf.rs@virtual_ip_nfs.service ○ └─ ocf.rs@portunblock_nfs.service /etc/drbd-reactor.d/prom.toml: Prometheus: listening on :9942
drbd-reactorctl status におけるプロモータープラグインのサービスユニット状態のインジケーターは以下の通りです:
-
アクティブ: 太字の緑色の塗りつぶされた円 (●)
-
リロード:太字の緑色の更新矢印 (↻)
-
非アクティブ:白抜きの円(○)
-
失敗:太字の赤いバツ印(×)
-
起動中:太字の塗りつぶされた円(●)
-
無効化中:太い塗りつぶされた円 (●)
-
メンテナンス: 白抜きの円 (○)
8.4.2. Pacemaker CRM シェルコマンドに代わる DRBD Reactor クライアントコマンド
次の表は、一般的なCRMタスクとそれに対応するPacemaker CRMシェル、および同等のDRBD Reactorクライアントコマンドを示したものです。
| CRM task | Pacemaker CRM shell command | DRBD Reactor client command |
|---|---|---|
Get status |
|
|
Migrate away |
|
|
Unmigrate |
|
Unnecessary |
crm resource unmigrate に相当するDRBDリアクタークライアントコマンドは不要です。なぜなら、DRBDリアクターのPromoterプラグインはDRBDリソースを即座に排除しますが、後で状況が生じた場合にはそのリソースを元のノードにバックフェイルさせることを妨げません。それに対して、CRMシェルの migrate コマンドは、クラスタ情報ベース(CIB)に永続的な制約を挿入し、コマンドを実行したノード上でリソースが実行されないようにします。CRMシェルの unmigrate コマンドは、制約を削除し、リソースがコマンドを実行したノードにバックフェイルすることを可能にする手動介入です。 unmigrate コマンドを忘れると、次回のHAイベント中にリソースをホストするためにノードが必要になった時に、深刻な影響が生じる可能性があります。
特定のノードへのフェイルバックを防止する必要がある場合は、DRBD Reactor クライアントの evict --keep-masked コマンドを使用して、そのノードを退避させることができます。これにより、ノードが再起動してフラグが削除されるまで、フェイルバックが防止されます。再起動を待たずにフラグを削除したい場合は、drbd-reactorctl evict --unmask コマンドを使用します。このコマンドは、CRM シェルの unmigrate コマンドと同じです。
|
8.5. DRBD Reactorのpromoterで高可用性ファイルシステムをマウントする
この例では、DRBD ReactorとPromoterプラグインを使用して、クラスタ内で高可用性のファイルシステムマウントを作成します。
前提条件:
-
すべてのクラスタノードで
/mnt/testディレクトリが作成されている。 -
すべてのノードで DRBD デバイスによって構成される ha-mount という名前の DRBD 構成済みリソース。以下の設定例では
/dev/drbd1000を使用しています。 -
Cluster Labの`resource-agents`ソースコードリポジトリで公開されているCluster Labs OCF Filesystemリソースエージェントは、`/usr/lib/ocf/resource.d/heartbeat`ディレクトリに配置されている必要があります。
LINBIT の顧客または評価アカウントをお持ちの場合は、LINBIT の drbd-9パッケージ リポジトリで利用可能なresource-agentsパッケージをインストールして、”Filesystem” OCF リソース エージェントを含むリソース エージェントスクリプトをインストールできます。
DRBD リソースである ha-mount は、DRBD リソース構成ファイルで次の設定を行う必要があります。
resource ha-mount {
options {
auto-promote no;
quorum majority;
on-no-quorum suspend-io;
on-no-data-accessible suspend-io;
[...]
}
[...]
}
まず、いずれかのノードを ha-mount リソースの Primary にします。
drbdadm primary ha-mount
次に、DRBD で構成されたデバイスにファイルシステムを作成します。この例では ext4 ファイルシステムを使用します。
mkfs.ext4 /dev/drbd1000
追加の構成作業後、DRBD ReactorとPromoterプラグインが昇格ノードの制御を担当するため、ノードを Secondary に設定してください。
drbdadm secondary ha-mount
すべてのノードで DRBD で構成されたデバイスをマウントできるよう、systemd ユニットファイルを作成します。
cat << EOF > /etc/systemd/system/mnt-test.mount [Unit] Description=Mount /dev/drbd1000 to /mnt/test [Mount] What=/dev/drbd1000 Where=/mnt/test Type=ext4 EOF
systemd のユニットファイル名は Where= ディレクティブで指定されたマウントロケーションの値と、systemd のエスケープロジックで一致しなければなりません。上の例では、mnt-test.mount が Where=/mnt/test で指定されたマウント位置にマッチしています。コマンド systemd-escape -p --suffix=mount /my/mount/point を使って、マウントポイントを systemd のユニットファイル名に変換することができます。
|
次に、前の手順と同じノード上に、DRBD Reactor Promoter プラグインの設定ファイルを作成してください。
cat << EOF > /etc/drbd-reactor.d/ha-mount.toml [[promoter]] [promoter.resources.ha-mount] start = [ """ocf:heartbeat:Filesystem fs_test device=/dev/drbd1000 \ directory=/mnt/test fstype=ext4 run_fsck=no""" ] on-drbd-demote-failure = "reboot" EOF
この promoter プラグインの構成では、HA マウントポイントにあるファイルシステムの OCF リソース エージェントを指定するサービスの開始リストを使用しています。この特定のリソース エージェントを使用することで、systemd がマウントポイントを保持し、アンマウントを妨げる可能性のある特定のユーザーやプロセスについて把握していないときに状況を回避できます。例えば、start = ["mnt-test.mount"] のようにマウントポイントのために systemd マウントユニットを指定した場合、OCF ファイルシステムリソースエージェントを使用する代わりにこのような状況が発生する可能性があります。
|
構成を適用するには、すべてのノードで DRBD Reactor サービスを有効にして開始します。DRBD Reactor サービスがすでに実行されている場合は、代わりにリロードしてください。
systemctl enable drbd-reactor.service --now
次に、どのクラスタノードが ha-mount リソースの Primary ロールにあり、構成デバイスがマウントされているかを確認します。
drbd-reactorctl status ha-mount
DRBD Reactor CLI ユーティリティを使用して ha-mount 構成を無効にし、 primary ノードで簡単なフェイルオーバをテストします。
drbd-reactorctl disable --now ha-mount
DRBD Reactor のステータスコマンドを再度実行して、別のノードが Primary の役割になり、ファイルシステムがマウントされていることを確認します。
フェイルオーバをテストした後、先ほど無効にしたノードで設定を有効にすることができます。
drbd-reactorctl enable ha-mount
次のステップとして、『LINSTORユーザガイド』の「高可用LINSTORクラスタの作成」に関するセクション( https://linbit.com/drbd-user-guide/linstor-guide-1_0-en/#s-linstor_ha )を参照してください。そこでは、LINSTORコントローラサービスをクラスタ内で高可用にするために、DRBD Reactorを使用して管理する手順が説明されています。
8.6. DRBD ReactorのPrometheusプラグインの設定
DRBD ReactorのPrometheusモニタリングプラグインは、DRBDリソース向けのPrometheus互換エンドポイントとして機能し、さまざまなDRBDメトリクスを公開します。利用可能なメトリクスの一覧は、プロジェクトのGitHubリポジトリ内のドキュメントフォルダ( https://github.com/LINBIT/drbd-reactor/blob/master/doc/prometheus.md )にあります。
前提条件:
-
Prometheus がインストール、サービスが有効で動作している。
-
Grafana がインストール、サービスが有効で動作している。
Prometheusプラグインを有効にするには、監視しているすべてのDRBD Reactorノードに簡単な構成ファイルスニペットを作成してください。
cat << EOF > /etc/drbd-reactor.d/prometheus.toml [[prometheus]] enums = true address = "0.0.0.0:9942" EOF
監視しているすべてのノードで DRBD Reactor サービスを再ロードします。
systemctl reload drbd-reactor.service
Prometheus 設定ファイルの scrape_configs セクションに、以下の DRBD Reactor 監視エンドポイントを追加します。以下の targets 行の node-x を、DRBD Reactor 監視エンドポイントノードのホスト名または IP アドレスに置き換えます。ホスト名はPrometheus 監視ノードから解決可能である必要があります。
- job_name: drbd_reactor_endpoint
static_configs:
- targets: ['node-0:9942']
labels:
instance: 'node-0'
- targets: ['node-1:9942']
labels:
instance: 'node-1'
- targets: ['node-2:9942']
labels:
instance: 'node-2'
[...]
次に、Prometheus サービスが既に有効で実行中であると仮定して、 sudo systemctl reload prometheus.service と入力して、Prometheus サービスをリロードします。
次に、Web ブラウザで Grafana サーバーの URL を開きます。Grafanaサーバーサービスが Prometheus モニタリングサービスと同じノードで稼働している場合、URL は次のようになります。 http://<node_IP_address_or_hostname>:3000 となります。
その後、Grafana サーバーの Web UI にログインし、Prometheus データソースを追加し、Prometheus データソースを使用する Grafana ダッシュボードを追加またはインポートすることが可能です。ダッシュボード例は、 Grafana Labs dashboards marketplace で公開されています。また、ダッシュボードの例は、ダウンロード可能な JSON ファイルとして こちら, DRBD Reactor GitHub プロジェクトサイトで入手可能です。
9. DRBDをPacemakerクラスターに統合する
PacemakerクラスタスタックとDRBDの組み合わせは、もっとも多いDRBDの使いみちです。そしてまた、Pacemakerはさまざまな使用シナリオでDRBDを非常に強力なものにするアプリケーションの1つです。
DRBD は Pacemaker クラスタでさまざまな方法で使用できます。
-
DRBDをSANのようにバックグラウンドのサービスとして使用する、または
-
DRBD は DRBD OCF リソースエージェントを介して Pacemaker によって完全に管理されます。
それぞれの長所と短所は後で考察します。
| フェンシングを構成するか、またはクォーラムを有効にすることをお勧めします(ただし、両方ではありません。外部フェンシングハンドラーの結果は、DRBD 内部クォーラムと競合し相互作用する可能性があります)。クラスタ間の接続が途切れてノードが互いを見失うと、両ノードでサービスが開始し(フェイルオーバ)、通信が復帰したタイミングで スプリットブレイン が発生する事になります。 |
9.1. Pacemaker の概要
PacemakerはLinuxプラットフォーム向けの高度で機能豊富なクラスタリソースマネージャで、さまざまな用途で使われています。マニュアルも豊富に用意されています。この章を理解するために、以下のドキュメントを読むことを強くお勧めします。
-
Clusters From Scratch:高可用性クラスタ構築ステップバイステップガイド
-
CRM CLI (command line interface) tool, a manual for the CRM shell, a simple and intuitive command line interface bundled with Pacemaker;
-
Pacemaker Configuration Explained, a reference document explaining the concept and design behind Pacemaker.
9.2. PacemakerクラスターでDRBDをバックグラウンドサービスとして使用する
自律的なDRBDストレージはローカルストレージのように扱えます。Pacemakerクラスタへの組み込みは、DRBDのマウントポイントを指定することで行えます。
初めに、DRBDの 自動プロモーション 機能を使用しますので、DRBDは必要な時に自分自身を プライマリ に設定します。この動作はすべてのリソースで同じなので common セクションで設定しておくとよいでしょう。
common {
options {
auto-promote yes;
...
}
}後はファイルシステム経由で使ってストレージにアクセスするだけです。
自動プロモーション を使ったDRBDを下位デバイスにするMySQLサービスのPacemaker設定crm configure
crm(live)configure# primitive fs_mysql ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/mysql/0" \
directory="/var/lib/mysql" fstype="ext3"
crm(live)configure# primitive ip_mysql ocf:heartbeat:IPaddr2 \
params ip="10.9.42.1" nic="eth0"
crm(live)configure# primitive mysqld lsb:mysqld
crm(live)configure# group mysql fs_mysql ip_mysql mysqld
crm(live)configure# commit
crm(live)configure# exit
bye
基本的には、必要なのはDRBDリソースがマウントされるマウントポイント(この例では /var/lib/mysql )です。
Pacemaker管理下ではクラスタ内で1インスタンスのみがマウント出来ます。
システム起動などの順序の制約に関する追加情報は DRBD のプロモーションスコアを CIB にインポートする も参照ください。
9.3. DRBDを下位デバイスにするマスターとスレーブのあるサービスのクラスタ設定
このセクションではPacemakerクラスタでDRBDを下位デバイスにするサービスを使用する方法を説明します。
| DRBDのOCFリソースエージェントを採用している場合には、DRBDの起動、停止、昇格、降格はOCFリソースエージェント のみ で行う事を推奨します。DRBDの自動起動は無効にしてください。 |
chkconfig drbd off
OCFリソースエージェントの ocf:linbit:drbd はマスター/スレーブ管理が可能であり、Pacemakerから複数ノードでのDRBDリソースの起動やモニター、必要な場合には降格を行うことができます。ただし、 drbd リソースエージェントはPacemakerのシャットダウン時、またはノードをスタンバイモードにする時には、管理する全DRBDリソースを切断してデタッチを行う事を理解しておく必要があります。
linbit のDRBD付属のOCFリソースエージェントは /usr/lib/ocf/resource.d/linbit/drbd にインストールされます。heartbeat のOCFリソースパッケージに付属するレガシーなリソースエージェントは /usr/lib/ocf/resource.d/heartbeat/drbd にインストールされます。レガシーなOCFリソースエージェントは非推奨なので使用しないでください。
|
drbd のOCFリソースエージェントを使用したPacemakerのCRMクラスタで、MySQLデータベースにDRBDの下位デバイス設定を有効にするためには、両方の必要なリソースエージェントを作成して、 先行してDRBDリソースが昇格したノードでだけサービスが起動するようにPacemakerの制約を設定しなければなりません。以下に示すように、crm シェルで設定することができます。
マスター/スレーブ リソースを使ったDRBDを下位デバイスにするMySQLサービスのPacemaker設定crm configure
crm(live)configure# primitive drbd_mysql ocf:linbit:drbd \
params drbd_resource="mysql" \
op monitor interval="29s" role="Master" \
op monitor interval="31s" role="Slave"
crm(live)configure# ms ms_drbd_mysql drbd_mysql \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
crm(live)configure# primitive fs_mysql ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/mysql/0" \
directory="/var/lib/mysql" fstype="ext3"
crm(live)configure# primitive ip_mysql ocf:heartbeat:IPaddr2 \
params ip="10.9.42.1" nic="eth0"
crm(live)configure# primitive mysqld lsb:mysqld
crm(live)configure# group mysql fs_mysql ip_mysql mysqld
crm(live)configure# colocation mysql_on_drbd \
inf: mysql ms_drbd_mysql:Master
crm(live)configure# order mysql_after_drbd \
inf: ms_drbd_mysql:promote mysql:start
crm(live)configure# commit
crm(live)configure# exit
bye
これで設定が有効になります。そしてPacemakerがDRBDリソースを昇格するノードを選び、そのノードでDRBDを下位デバイスにするリソースを起動します。
Master role を配置するための location 制約に関する追加情報は DRBD のプロモーションスコアを CIB にインポートする も参照ください。
9.4. Pacemakerクラスタでリソースレベルのフェンシングを使用する
ここでは、DRBDのレプリケーションリンクが遮断された場合に、Pacemakerが drbd マスター/スレーブリソースを昇格させないようにするために必要な手順の概要を説明します。これにより、Pacemakerが古いデータでサービスを開始し、プロセスでの不要な「タイムワープ」の原因になることが回避できます。
DRBD用のリソースレベルのフェンシングを有効にするには、リソース設定で次の行を追加する必要があります。
resource <resource> {
net {
fencing resource-only;
...
}
}同時に、使用するクラスタインフラストラクチャによっては handlers セクションも変更しなければなりません。
Corosync を使用したクラスタは CIB (Cluster Information Base)を使ったリソースレベルフェンシング で説明されている機能を使うことができます。
最低でも2つの独立したクラスタ通信チャネルを設定しなければ、この機能は正しく動作しません。Corosync クラスタでは最低 2 つの冗長リング、それぞれ knet のいくつかのパスを corosync.conf に記載しなければなりません。
|
9.4.1. CIB (Cluster Information Base)を使ったリソースレベルフェンシング
Pacemaker用のリソースレベルフェンシングを有効にするには、 drbd.conf の2つのオプション設定をする必要があります。
resource <resource> {
net {
fencing resource-only;
...
}
handlers {
fence-peer "/usr/lib/drbd/crm-fence-peer.9.sh";
unfence-peer "/usr/lib/drbd/crm-unfence-peer.9.sh";
# Note: we used to abuse the after-resync-target handler to do the
# unfence, but since 2016 have a dedicated unfence-peer handler.
# Using the after-resync-target handler is wrong in some corner cases.
...
}
...
}DRBDレプリケーションリンクが切断された場合には crm-fence-peer.sh スクリプトがクラスタ管理システムに連絡し、このDRBDリソースに関連付けられたPacemakerのマスター/スレーブリソースが決定され、現在アクティブなノード以外のすべてのノードでマスター/スレーブリソースが昇格されることがないようにします。逆に、接続が再確立してDRBDが同期プロセスが完了すると、この制約は解除され、クラスタ管理システムは再び任意のノードのリソースを自由に昇格させることができます。
9.5. PacemakerクラスタでスタックDRBDリソースを使用する
| Stacking is deprecated in DRBD version 9.x, as more nodes can be implemented on a single level. See ネットワークコネクションの定義 for details. |
スタックリソースを用いるとマルチノードクラスタの多重冗長性やオフサイトのディザスタリカバリ機能を実現するためにDRBDを利用できます。本セクションではそのような構成におけるDRBDおよびPacemakerの設定方法について説明します。
9.5.1. オフサイトディザスタリカバリ機能をPacemakerクラスタに追加する
この構成シナリオでは、1つのサイトの2ノードの高可用性クラスタと、多くは別のサイトに設置する独立した1つのノードについて説明します。第3のノードは、ディザスタリカバリノードとして機能するスタンドアロンサーバです。次の図で概念を説明します。

この例では alice と bob が2ノードのPacemakerクラスタを構成し、 charlie はPacemakerで管理されないオフサイトのノードです。
このような構成を作成するには、 スタックされた3ノード構成の作成 の説明に従って、まずDRBDリソースを設定と初期化を行います。そして、次のCRM構成でPacemakerを設定します。
primitive p_drbd_r0 ocf:linbit:drbd \
params drbd_resource="r0"
primitive p_drbd_r0-U ocf:linbit:drbd \
params drbd_resource="r0-U"
primitive p_ip_stacked ocf:heartbeat:IPaddr2 \
params ip="192.168.42.1" nic="eth0"
ms ms_drbd_r0 p_drbd_r0 \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true" globally-unique="false"
ms ms_drbd_r0-U p_drbd_r0-U \
meta master-max="1" clone-max="1" \
clone-node-max="1" master-node-max="1" \
notify="true" globally-unique="false"
colocation c_drbd_r0-U_on_drbd_r0 \
inf: ms_drbd_r0-U ms_drbd_r0:Master
colocation c_drbd_r0-U_on_ip \
inf: ms_drbd_r0-U p_ip_stacked
colocation c_ip_on_r0_master \
inf: p_ip_stacked ms_drbd_r0:Master
order o_ip_before_r0-U \
inf: p_ip_stacked ms_drbd_r0-U:start
order o_drbd_r0_before_r0-U \
inf: ms_drbd_r0:promote ms_drbd_r0-U:startこの構成を /tmp/crm.txt という一時ファイルに保存し、次のコマンドで現在のクラスタにインポートします。
crm configure < /tmp/crm.txt
この設定により、次の操作が正しい順序で alice と bob クラスタで行われます。
-
PacemakerはDRBDリソース
r0を両クラスタノードで開始し、1つのノードをマスター(DRBD Primary)ロールに昇格させます。 -
PacemakerはIPアドレス192.168.42.1の、第3ノードへのレプリケーションに使用するスタックリソースを開始します。これは、
r0DRBDリソースのマスターロールに昇格したノードで行われます。 -
r0がプライマリになっていて、かつ、r0-U のレプリケーション用IPアドレスを持つノードで、Pacemakerはオフサイトノードに接続およびレプリケートを行うr0-UDRBDリソースを開始します。 -
最後に、Pacemakerが
r0-Uリソースもプライマリロールに昇格させるため、ディザスタリカバリノードとのレプリケーションが始まります。
このように、このPacemaker構成では、クラスタノード間だけではなく第3のオフサイトノードでも完全なデータ冗長性が確保されます。
| このタイプの設定には通常、 DRBD Proxy と合わせて使用するのが一般的です。 |
9.5.2. スタックリソースを使って、Pacemakerクラスタの4ノード冗長化を実現する
この構成では、全部で3つのDRBDリソース(2つの非スタック、1つのスタック)を使って、4ノードのストレージ冗長化を実現します。4ノードクラスタの目的と意義は、3ノードまで障害が発生しても、可用なサービスを提供し続けることが可能であることです。
次の例で概念を説明します。

この例では、 alice と bob ならびに charlie と daisy が2セットの2ノードPacemakerクラスタを構成しています。alice と bob は left という名前のクラスタを構成し、互いにDRBDリソースを使ってデータをレプリケートします。一方 charlie と daisy も同様に、 right という名前の別のDRBDリソースでレプリケートします。3番目に、DRBDリソースをスタックし、2つのクラスタを接続します。
| Pacemakerバージョン1.0.5のPacemakerクラスタの制限により、CIBバリデーションを有効にしたままで4ノードクラスタをつくることはできません。CIBバリデーションは汎用的に使うのには向かない特殊な高度な処理です。これは、今後のPacemakerのリリースで解決されることが予想されます。 |
このような構成を作成するには、 スタックされた3ノード構成の作成 の説明に従って、まずDRBDリソースを設定して初期化します(ただし、ローカルがクラスタになるだけでなく、リモート側にもクラスタになる点が異なります)。そして、次のCRM構成でPacemakerを設定し、 left クラスタを開始します。
primitive p_drbd_left ocf:linbit:drbd \
params drbd_resource="left"
primitive p_drbd_stacked ocf:linbit:drbd \
params drbd_resource="stacked"
primitive p_ip_stacked_left ocf:heartbeat:IPaddr2 \
params ip="10.9.9.100" nic="eth0"
ms ms_drbd_left p_drbd_left \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
ms ms_drbd_stacked p_drbd_stacked \
meta master-max="1" clone-max="1" \
clone-node-max="1" master-node-max="1" \
notify="true" target-role="Master"
colocation c_ip_on_left_master \
inf: p_ip_stacked_left ms_drbd_left:Master
colocation c_drbd_stacked_on_ip_left \
inf: ms_drbd_stacked p_ip_stacked_left
order o_ip_before_stacked_left \
inf: p_ip_stacked_left ms_drbd_stacked:start
order o_drbd_left_before_stacked_left \
inf: ms_drbd_left:promote ms_drbd_stacked:startこの構成を /tmp/crm.txt という一時ファイルに保存し、次のコマンドで現在のクラスタにインポートします。
crm configure < /tmp/crm.txt
CIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
aliceとbobをレプリケートするリソースleftを起動し、いずれかのノードをマスターに昇格します。 -
IPアドレス10.9.9.100 (
aliceまたはbob、いずれかのリソースleftのマスターロールを担っている方)を起動します。 -
IPアドレスを設定したのと同じノード上で、DRBDリソース
stackedが起動します。 -
target-role=”Master”が指定されているため、スタックリソースがプライマリになります。
さて、以下の設定を作り、クラスタ right に進みましょう。
primitive p_drbd_right ocf:linbit:drbd \
params drbd_resource="right"
primitive p_drbd_stacked ocf:linbit:drbd \
params drbd_resource="stacked"
primitive p_ip_stacked_right ocf:heartbeat:IPaddr2 \
params ip="10.9.10.101" nic="eth0"
ms ms_drbd_right p_drbd_right \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
ms ms_drbd_stacked p_drbd_stacked \
meta master-max="1" clone-max="1" \
clone-node-max="1" master-node-max="1" \
notify="true" target-role="Slave"
colocation c_drbd_stacked_on_ip_right \
inf: ms_drbd_stacked p_ip_stacked_right
colocation c_ip_on_right_master \
inf: p_ip_stacked_right ms_drbd_right:Master
order o_ip_before_stacked_right \
inf: p_ip_stacked_right ms_drbd_stacked:start
order o_drbd_right_before_stacked_right \
inf: ms_drbd_right:promote ms_drbd_stacked:startCIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
charlieとdaisy間をレプリケートするDRBDリソースrightを起動し、これらのノードのいずれかをマスターにします。 -
IPアドレス10.9.10.101を開始します(
charlieまたはdaisyのいずれかのリソースrightのマスターロールを担っている方)を起動します)。 -
IPアドレスを設定したのと同じノード上で、DRBDリソース
stackedが起動します。 -
target-role="Slave"が指定されているため、スタックリソースはセカンダリのままになります。
9.6. 2セットのSANベースPacemakerクラスタ間をDRBDでレプリケート
これは、拠点が離れた構成に用いるやや高度な設定です。2つのクラスタが関与しますが、それぞれのクラスタは別々のSANストレージにアクセスします。サイト間のIPネットワークを使って2つのSANストレージのデータを同期させるためにDRBDを使います。
次の図で概念を説明します。

このような構成の場合、DRBDの通信にかかわるホストをあらかじめ明示的に指定しておくことは不可能です。つまり、動的接続構成の場合、DRBDは特定の物理マシンではなく 仮想IPアドレス で通信先を決めます。
| このタイプの設定は通常、 DRBD Proxy や、または トラック輸送のレプリケーション と組み合わせます。 |
このタイプの設定は共有ストレージを扱うので、STONITHを構築してテストすることが、正常動作の確認のためには必要不可欠です。ただし、STONITHは本書の範囲を超えるので、以下の設定例は省略しています。
9.6.1. DRBDリソース構成
動的接続するDRBDリソースを有効にするには、次のように drbd.conf を設定します。
resource <resource> {
...
device /dev/drbd0;
disk /dev/vg0/lv0;
meta-disk internal;
floating 10.9.9.100:7788;
floating 10.9.10.101:7788;
}floating キーワードは、通常リソース設定の on <host> セクションの代わりに指定します。このモードでは、DRBDはホスト名ではなく、IPアドレスやTCPポートで相互接続を認識します。動的接続を適切に運用するには、物理IPアドレスではなく仮想IPアドレスを指定してください(これはとても重要です)。上の例のように、離れた地点ではそれぞれ別々のIPネットワークに属するのが一般的です。したがって、動的接続を正しく運用するにはDRBDの設定だけではなく、ルータやファイアウォールの適切な設定も重要です。
9.6.2. Pacemakerリソース構成
DRBD動的接続の設定には、少なくともPacemaker設定が必要です(2つの各Pacemakerクラスタに係わる)。
-
仮想クラスタIPアドレス
-
マスター/スレーブDRBDリソース(DRBD OCFリソースエージェントを使用)
-
リソースを適切なノードで正しい順序に起動するための各種制約
レプリケーション用アドレスに 10.9.9.100 を使う動的接続構成と、 mysql というリソースを構築するには、次のように crm コマンドでPacemakerを設定します。
crm configure
crm(live)configure# primitive p_ip_float_left ocf:heartbeat:IPaddr2 \
params ip=10.9.9.100
crm(live)configure# primitive p_drbd_mysql ocf:linbit:drbd \
params drbd_resource=mysql
crm(live)configure# ms ms_drbd_mysql drbd_mysql \
meta master-max="1" master-node-max="1" \
clone-max="1" clone-node-max="1" \
notify="true" target-role="Master"
crm(live)configure# order drbd_after_left \
inf: p_ip_float_left ms_drbd_mysql
crm(live)configure# colocation drbd_on_left \
inf: ms_drbd_mysql p_ip_float_left
crm(live)configure# commit
bye
CIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
IPアドレス10.9.9.100を起動する(
aliceまたはbobのいずれか) -
IPアドレスの設定にもとづいてDRBDリソースを起動します。
-
DRBDリソースをプライマリにします。
次に、もう一方のクラスタで、これとマッチングする設定を作成します。 その Pacemakerのインスタンスを次のコマンドで設定します。
crm configure
crm(live)configure# primitive p_ip_float_right ocf:heartbeat:IPaddr2 \
params ip=10.9.10.101
crm(live)configure# primitive drbd_mysql ocf:linbit:drbd \
params drbd_resource=mysql
crm(live)configure# ms ms_drbd_mysql drbd_mysql \
meta master-max="1" master-node-max="1" \
clone-max="1" clone-node-max="1" \
notify="true" target-role="Slave"
crm(live)configure# order drbd_after_right \
inf: p_ip_float_right ms_drbd_mysql
crm(live)configure# colocation drbd_on_right
inf: ms_drbd_mysql p_ip_float_right
crm(live)configure# commit
bye
CIBに上記の設定を投入すると、Pacemakerは以下のアクションを実行します。
-
IPアドレス10.9.10.101を起動する(charlie または daisy のいずれか)。
-
IPアドレスの設定にもとづいてDRBDリソースを起動します。
-
target-role=”Slave” が指定されているため、DRBDリソースは、セカンダリのままになります。
9.6.3. サイトのフェイルオーバ
拠点が離れた構成では、サービス自体をある拠点から他の拠点に切り替える必要が生じるかもしれません。これは、計画された移行か、または悲惨な出来事の結果でしょう。計画にもとづく移行の場合、一般的な手順は次のようになります。
-
サービス移行元のクラスタに接続し、影響を受けるDRBDリソースの
target-role属性をマスターからスレーブに変更します。DRBDがプライマリであることに依存したリソースは自動的に停止し、その後DRBDはセカンダリに降格します。 -
サービス移行先のクラスタに接続し、DRBDリソースの
target-role属性をSlaveからMasterに変更します。DRBDリソースは昇格し、DRBDリソースのプライマリ側に依存した他のPacemakerリソースを起動します。 そしてリモート拠点への同期が更新されます。 -
フェイルバックをするには、手順を逆にするだけです。
アクティブな拠点で壊滅的な災害が起きると、その拠点はオフラインになり、以降その拠点からバックアップ側にレプリケートできなくなる可能性があります。このような場合には
-
リモートサイトが機能しているならそのクラスタに接続し、DRBDリソースの
target-role属性をスレーブからマスターに変更します。DRBDリソースは昇格し、DRBDリソースがプライマリになることに依存する他のPacemakerリソースも起動します。 -
元の拠点が回復または再構成されると、DRBDリソースに再度接続できるようになります。その後、逆の手順でフェイルバックします。
9.7. DRBD のプロモーションスコアを CIB にインポートする
このセクションで説明するものはすべて drbd-attr OCF リソースエージェントに依存します。drbd-utils バージョン 9.15.0 以降で使用できます。Debian/Ubuntu システムでは、これは drbd-utils パッケージの一部です。 RPM ベースの Linux ディストリビューションでは drbd-pacemaker パッケージをインストールする必要があります。
|
すべての DRBD リソースは、それが構成されている各ノードでプロモーションスコアを公開します。これは 0 または正の数値です。この値は、このノードでリソースをマスターに昇格させることがどれほど望ましいかを示します。 UpToDate ディスクと 2 つの UpToDate レプリカを持つノードは UpToDate ディスクと 1 つの UpToDate レプリカを持つノードよりもスコアが高くなります。
たとえば DRBD デバイスに下位デバイスが接続される前、または、クォーラムが有効になっている場合は、クォーラムが取得される前はプロモーションスコアは 0 です。値 0 は、プロモーションリクエストが失敗することを意味し、ここで実行してはならないことを pacemaker に指示します。
drbd-attr OCF リソースエージェントは、これらのプロモーションスコアを Pacemaker クラスターのノード属性にインポートします。次のようにして構成します。
primitive drbd-attr ocf:linbit:drbd-attr
clone drbd-attr-clone drbd-attrこれらは一時的な属性です(再起動時に定義される)。つまり、ノードの再起動後、または pacemaker のローカル再起動後、これらの属性はそのノードで drbd-attr のインスタンスが開始されるまで存在しません。
生成された属性は crm_mon -A-1 で確認できます。
これらの属性は、DRBD デバイスに依存するサービスの制約で使用できます。また ocf:linbit:drbd リソースエージェントで DRBD を管理する場合は、その DRBD インスタンスの Master ロールでも使用できます。
以下は、 PacemakerクラスターでDRBDをバックグラウンドサービスとして使用する のサンプルリソースのロケーション制約の例です。
location lo_fs_mysql fs_mysql \
rule -inf: not_defined drbd-promotion-score-mysql \
rule drbd-promotion-score-mysql: defined drbd-promotion-score-mysqlこれは、属性が定義されていない限り、fs_mysql ファイルシステムをここにマウントできないことを意味します。属性が定義されると、その値がロケーション制約のスコアになります。
これは、DRBD がローカルの下位デバイスを失ったときに Pacemaker にサービスを移行させるためにも使用できます。下位ブロックデバイスに障害が発生するとプロモーションスコアが低下するため、下位デバイスが機能している他のノードはより高いプロモーションスコアになります。
属性は、リソースエージェントの監視操作とは関係なく、随時更新されます。デフォルトでは、5秒の減衰遅延があります。
リソースエージェントには、以下のオプションのパラメータもあります。詳細は ocf_linbit_drbd-attr(7) を参照ください。
-
dampening_delay -
attr_name_prefix -
record_event_details
10. DRBD で LVM を使用
この章では、LVM2 で使用する DRBD の管理について説明します。特に、この章では次の方法について説明します。
-
DRBDの下位デバイスとして論理ボリュームを使用する
-
LVM の物理ボリュームとしてDRBDデバイスを使用する
-
上記の2つを組み合わせ、 DRBDを使用して階層構造のLVMを実装する
上記の用語についてよく知らない場合は、 LVM の概要 を参照してください。また、ここで説明する内容にとどまらず、LVMについてさらに詳しく理解することをお勧めします。
10.1. LVM の概要
LVM2は、Linuxデバイスマッパフレームワークでの論理ボリューム管理を実用化したものです。元々のLVMとは、名前以外は実際は何の共通点もありません。以前の実装(現在LVM1と呼ぶもの)は時代遅れとみなされているため、ここでは取り上げません。
LVMを使用する際には、次に示す基本的なコンセプトを理解することが重要です。
PV (Physical Volume: 物理ボリューム)はLVMのみが管理配下とするブロックデバイスです。ハードディスク全体または個々のパーティションがPVになります。ハードディスクにパーティションを1つだけ作成して、これをすべてLinux LVMで使用するのが一般的です。
| パーティションタイプ”Linux LVM” (シグネチャは 0x8E)を使用して、LVMが独占的に使用するパーティションを識別できます。ただし、これは必須ではありません。PVの初期化時にデバイスに書き込まれるシグネチャによってLVMがPVを認識します。 |
VG (Volume Group: ボリュームグループ)はLVMの基本的な管理単位です。VGは1つまたは複数のPVで構成されます。各VGは一意の名前を持ちます。実行時にPVを追加したり、PVを拡張して、VGを大きくすることができます。
実行時にVG内にLV (Logical Volume: 論理ボリューム)を作成することにより、カーネルの他の部分がこれらを通常のブロックデバイスとして使用できます。このように、LVはファイルシステムの格納をはじめ、ブロックデバイスと同様のさまざまな用途に使用できます。オンライン時にLVのサイズを変更したり、1つのPVから別のPVに移動したりすることができます(PVが同じVGに含まれる場合)。
スナップショットはLVの一時的なポイントインタイムコピーです。スナップショットはLVの一時的なポイントインタイムコピーです。元のLV(コピー元ボリューム)のサイズが数百GBの場合でも、スナップショットは一瞬で作成できます。通常、スナップショットは元のLVと比べてかなり小さい領域しか必要としません。

10.2. DRBDの下位デバイスとして論理ボリュームを使用する
Linuxでは、既存の論理ボリュームは単なるブロックデバイスであるため、これをDRBDの下位デバイスとして使用できます。この方法でLVを使用する場合は、通常通りにLVを作成してDRBD用に初期化するだけです。
|
DRBD を LVM と一緒に使用する場合、LVM グローバル設定ファイル (RHEL では global_filter = [ "r|^/dev/drbd|" ] この設定は、LVMにDRBDデバイスをスキャンやオープンの試行から拒否するよう指示します。このフィルタを設定しない場合、CPU負荷の増加やLVM操作の停滞が発生する可能性があります。 |
次の例では、LVM対応システムの両方のノードに foo というボリュームグループがすでに存在します。このボリュームグループの論理ボリュームを使用して、 r0 というDRBDリソースを作成します。
まず、次のコマンドで論理ボリュームを作成します。
# lvcreate --name bar --size 10G foo Logical volume "bar" created
このコマンドはDRBDクラスタの両方のノードで実行する必要があります。これで、両ノードに /dev/foo/bar というブロックデバイスが作成されます。
次に、新しく作成したボリュームをリソース設定に加えます。
resource r0 {
...
on alice {
device /dev/drbd0;
disk /dev/foo/bar;
...
}
on bob {
device /dev/drbd0;
disk /dev/foo/bar;
...
}
}これで リソースを起動 できます。手順はLVM対応以外のブロックデバイスと同様です。
10.3. DRBD同期中の自動LVMスナップショットの使用
DRBDが同期をしている間、 SyncTarget の状態は同期が完了するまでは Inconsistent (不整合)の状態です。この状況では SyncSource で(修復できない)障害があった場合に困った状況になります。正常なデータを持つノードが死に、誤った情報を持つノードが残ってしまいます。
LVM論理ボリュームをDRBDに渡す際には、同期の開始時に自動スナップショットを作成し、またこれを完了後に自動削除する方法によって、この問題を軽減することができます
再同期中に自動でスナップショットをするには、リソース設定に以下の行を追加します。
resource r0 {
handlers {
before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh";
after-resync-target "/usr/lib/drbd/unsnapshot-resync-target-lvm.sh";
}
}
2つのスクリプトはDRBDが呼び出した ハンドラ に自動で渡す $DRBD_RESOURCE$ 環境変数を解析します。snapshot-resync-target-lvm.sh スクリプトは、同期の開始前に、リソースが含んでいるボリュームのLVMスナップショットを作成します。そのスクリプトが失敗した場合、同期は 開始 されません。
同期が完了すると、 unsnapshot-resync-target-lvm.sh スクリプトが必要のなくなったスナップショットを削除します。スナップショットの削除に失敗した場合、スナップショットは残り続けます。
| できる限り不要なスナップショットは確認するようにしてください。スナップショットが満杯だと、スナップショット自身と元のボリュームの障害の原因になります。 |
SyncSource に修復できない障害が起きて、最新のスナップショットに復帰したいときには、いつでも lvconvert -M コマンドで行えます。
10.4. DRBDリソースを物理ボリュームとして構成する
DRBDリソースを物理ボリュームとして使用するためには、DRBDデバイスにPVのシグネチャを作成する必要があります。リソースが現在プライマリロールになっているノードで、 次のいずれかのコマンドを実行します。
# pvcreate /dev/drbdX
または
# pvcreate /dev/drbd/by-res/<resource>/0
| この例ではボリュームリソースが1つの場合を前提にしています。 |
次に、LVMがPVシグネチャをスキャンするデバイスのリストにこのデバイスを加えます。このためには、通常は /etc/lvm/lvm.conf という名前のLVM設定ファイルを編集する必要があります。 devices セクションで filter というキーワードを含む行を見つけて編集します。 すべて のPVをDRBDデバイスに格納する場合には、次ように filter オプションを編集します。
filter = [ "a|drbd.*|", "r|.*|" ]このフィルタ表現がDRBDデバイスで見つかったPVシグネチャを受け入れ、それ以外のすべてを拒否(無視)します。
デフォルトではLVMは /dev にあるすべてのブロックデバイスのPVシグネチャをスキャンします。これは filter = [ "a|.*|" ] に相当します。
|
LVMのPVでスタックリソースを使用する場合は、より明示的にフィルタ構成を指定する必要があります。対応する下位レベルリソースや下位デバイスでPVシグネチャを無視している場合、LVMはスタックリソースでPVシグネチャを検出する必要があります。次の例では、下位レベルDRBDリソースは0から9のデバイスを使用し、スタックリソースは10以上のデバイスを使用しています。
filter = [ "a|drbd1[0-9]|", "r|.*|" ]このフィルタ表現は、 /dev/drbd10 から /dev/drbd19 までのDRBDのデバイスで見つかったPVシグニチャを受け入れ、それ以外のすべてを拒否(無視)します。
lvm.conf ファイルを変更したら vgscan コマンドを実行します。LVMは構成キャッシュを破棄し、デバイスを再スキャンしてPVシグネチャを見つけます。
システム構成に合わせて、別の filter 構成を使用することもできます。重要なのは、次の2つです。
-
PVとして使用するデバイスに、DRBDのデバイスを許容する
-
対応する下位レベルデバイスを拒否(除外)して、 LVMが重複したPVシグネチャを見つけることを回避する。
さらに、次の設定で、LVMのキャッシュを無効にする必要があります。
write_cache_state = 0LVMのキャッシュを無効にした後、 /etc/lvm/cache/.cache を削除して、古いキャッシュを削除してください。
対向ノードでも、上記の手順を繰り返します。
システムのルートファイルシステムがLVM上にある場合、bootの際にボリュームグループはイニシャルRAMディスク(initrd)から起動します。この時、LVMツールはinitrdイメージに含まれる lvm.conf ファイルを検査します。そのため、 lvm.conf に変更を加えたら、ディストリビューションに応じてユーティリティ(mkinitrd、update-initramfs など)で確実にinitrdをアップデートしなければなりません。
|
新しいPVを設定したら、ボリュームグループに追加するか、 新しいボリュームグループを作成します。このとき、DRBDリソースがプライマリロールになっている必要があります。
# vgcreate <name> /dev/drbdX
| 同じボリュームグループ内にDRBD物理ボリュームとDRBD以外の物理ボリュームを混在させることができますが、これはお勧めできません。また、混在させても実際には意味がないでしょう。 |
VGを作成したら、 lvcreate コマンドを使用して、(DRBD以外を使用するボリュームグループと同様に)ここから論理ボリュームを作成します。
10.5. 新しいDRBDボリュームを既存のボリュームグループへ追加する
新しいDRBDでバックアップした物理ボリュームを、ボリュームグループへ追加したいといった事があるでしょう。その場合には、新しいボリュームは既存のリソース設定に追加しなければなりません。そうすることでVG内の全PVにわたってレプリケーションストリームと書き込み順序の忠実性が確保されます。
| LVMボリュームグループを Pacemakerによる高可用性LVM で説明しているようにPacemakerで管理している場合には、DRBD設定の変更前にクラスタメンテナンスモードになっている事が 必要 です。 |
追加ボリュームを加えるには、リソース設定を次のように拡張します。
resource r0 {
volume 0 {
device /dev/drbd1;
disk /dev/disk/by-id/nvme-eui.daac3bd0da3b9b2b;
meta-disk internal;
}
volume 1 {
device /dev/drbd2;
disk /dev/disk/by-id/nvme-eui.9ecf6fb61f451198;
meta-disk internal;
}
on alice {
address 10.1.1.31:7789;
}
on bob {
address 10.1.1.32:7789;
}
}
| DRBDボリュームのバッキングにLVMやZFSの論理ボリュームを使用しない場合は、この設定例に示すように、DRBDリソース設定で永続的なブロックデバイス名(`/dev/disk/by-id/`内にあるブロックデバイス名)を使用してください。これにより、バスに基づいた名前の変更がDRBDリソースに影響を及ぼす可能性を防ぐことができます。特定のディスクのIDを確認するには、`lsblk -o Name,UUID,WWN`コマンドを実行してください。 |
DRBD設定が全ノード間で同じである事を確認し、次のコマンドを発行します。
# drbdadm adjust r0
これによって、リソース r0 の新規ボリューム 1 を有効にするため、暗黙的に drbdsetup new-minor r0 1 が呼び出されます。新規ボリュームがレプリケーションストリームに追加されると、イニシャライズやボリュームグループへの追加ができるようになります。
# pvcreate /dev/drbd/by-res/<resource>/1 # vgextend <name> /dev/drbd/by-res/<resource>/1
で新規PVの /dev/drbd/by-res/<resource>/1 が <name> VGへ追加され、VG全体にわたって書き込みの忠実性を保護します。
10.6. Pacemakerによる高可用性LVM
対向ノード間でのボリュームグループの転送と、対応する有効な論理ボリュームの作成のプロセスは自動化することができます。Pacemakerの LVM リソースエージェントはまさにこのために作られています。
既存のPacemaker管理下にあるDRBDの下位デバイスのボリュームグループをレプリケートするために、 crm シェルで次のコマンドを実行してみましょう。
primitive p_drbd_r0 ocf:linbit:drbd \
params drbd_resource="r0" \
op monitor interval="29s" role="Master" \
op monitor interval="31s" role="Slave"
ms ms_drbd_r0 p_drbd_r0 \
meta master-max="1" master-node-max="1" \
clone-max="2" clone-node-max="1" \
notify="true"
primitive p_lvm_r0 ocf:heartbeat:LVM \
params volgrpname="r0"
colocation c_lvm_on_drbd inf: p_lvm_r0 ms_drbd_r0:Master
order o_drbd_before_lvm inf: ms_drbd_r0:promote p_lvm_r0:start
commit
この設定を反映させると、現在のDRBDリソースのプライマリ(マスター)ロールがどちらであっても、Pacemakerは自動的に r0 ボリュームグループを有効にします。
10.7. クラスタリソースマネージャーなしで DRBD と LVM を使用する
DRBDの典型的な高可用性のユースケースは、クラスタリソースマネージャ(CRM)を使用して、DRBD複製ストレージボリュームなどのリソースの昇格と降格を処理することです。ただし、CRMなしでDRBDを使用することも可能です。
あなたが常に特定のノードにDRBDリソースの昇格をさせたいということを知っており、ピアノードはリカバリー目的でレプリケーションされるだけであり、優先権を取ることはないと知っている状況で、このような作業を行いたいと思うかもしれません。
この場合、DRBDリソースの昇格を処理し、バックエンドのLVM論理ボリュームが最初にアクティブ化されることを確認するために、いくつかのsystemdユニットファイルを使用できます。また、DRBDリソースをバックエンドデバイスとして使用している可能性のあるファイルシステムマウントを依存関係として持つように、DRBDリソース用のsystemdユニットファイルを作成する必要があります。
これを設定するためには、仮想的な DRBD リソースである webdata とファイルシステムのマウントポイントである /var/lib/www を考えると、以下のコマンドを入力するかもしれません:
# systemctl enable [email protected] # systemctl enable [email protected] # echo "/dev/drbdX /var/lib/www xfs defaults,nofail,[email protected] 0 0" \ >> /etc/fstab
この例では、drbdX の X は webdata リソースのためのあなたのDRBDバッキングデバイスのボリューム番号です。
drbd-wait-promotable@<DRBD-resource-name>.service は、DRBDがピアに接続し、正常なデータにアクセスできるようになるのを待ってから、ノード上でリソースを昇格させるために使用されるsystemdユニットファイルです。
11. DRBDでGFSを使用する
本章では共有グローバルファイルシステム(GFS)のブロックデバイスをDRBDリソースとするために必要な手順を説明します。GFS、GFS2の両方に対応しています。
DRBD上でGFSを使用するためには、 デュアルプライマリモードでDRBDを設定する必要があります。
| DRBD 9 は デュアルプライマリモード で 2 つのノードをサポートします。Primary 状態で 3 つ以上のノードを使用しようとする試みはサポートされておらず、データの損失につながる可能性があります。 |
|
全クラスタファイルシステムには fencingが 必要 です。DRBDリソース経由だけでなくSTONITHもです。問題のあるノードは 必ず killされる必要があります。 次のような設定がよいでしょう。 net {
fencing resource-and-stonith;
}
handlers {
# Make sure the other node is confirmed
# dead after this!
fence-peer "/usr/lib/drbd/crm-fence-peer.9.sh";
unfence-peer "/usr/lib/drbd/crm-unfence-peer.9.sh";
}
|
ノードが切断されたプライマリになると resource-and-stonith ネットワークフェンシング設定は次のようになります。
-
すべてのノードの I/O 操作をフリーズする。
-
ノードの fence-peer ハンドラを呼び出す。
fence-peer ハンドラが対向ノードに到達できない場合 (代替ネットワークなど)、fence-peer ハンドラは切断されたプライマリノードを STONITH する必要があります。状況が解決され次第、I/O 操作が再開されます。
11.1. GFS の概要
Red Hat Global File System (GFS)は、同時アクセス共有ストレージファイルシステムのRed Hatによる実装です。同様のファイルシステムのように、GFSでも複数のノードが読み取り/書き込みモードで、安全に同時に同じストレージデバイスにアクセスすることが可能です。これには、クラスタメンバからの同時アクセスを管理するDLM (Distributed Lock Manager)が使用されています。
本来、GFSは従来型の共有ストレージデバイスを管理するために設計されたものですが、デュアルプライマリモードでDRBDをGFS用のレプリケートされたストレージデバイスとして問題なく使用することができます。アプリケーションについては、読み書きの待ち時間が短縮されるというメリットがあります。 これは、GFSが一般的に実行されるSANデバイスとは異なり、DRBDが通常はローカルストレージに対して読み書きを行うためです。また、DRBDは各GFSファイルシステムに物理コピーを追加して、冗長性を確保します。
GFSはクラスタ対応版のLVMで、クラスタ化論理ボリュームマネージャ (CLVM)を使用します。このような対応関係が、GFSのデータストレージとしてDRBDを使用することと、 従来のLVMの物理ボリュームとしてDRBDを使用する こととの間に存在します。
GFSファイルシステムは通常はRedHat独自のクラスタ管理フレームワークの Red Hat Cluster と密接に結合されています。この章ではDRBDをGFSとともに使用する方法を Red Hat Clusterの観点から説明します。
GFS、Pacemaker、Red Hat ClusterはRed Hat Enterprise Linux (RHEL)と、CentOSなどの派生ディストリビューションで入手できます。同じソースからビルドされたパッケージがDebian GNU/Linuxでも入手できます。この章の説明は、Red Hat Enterprise LinuxシステムでGFSを実行することを前提にしています。
11.2. GFS用のDRBDリソースの作成
GFSは共有クラスタファイルシステムで、すべてのクラスタノードからストレージに対して同時に読み取り/書き込みアクセスが行われることを前提としています。したがって、GFSファイルシステムを格納するために使用するDRBDリソースは デュアルプライマリモード で設定する必要があります。また、 スプリットブレインからの自動回復のための機能 を利用することをおすすめします。そのためには、以下の設定をリソース設定ファイルに加えてください。
resource <resource> {
net {
allow-two-primaries yes;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
[...]
}
[...]
}|
|
これらのオプションを 新規に設定したリソース に追加したら、 通常通りにリソースを初期化 できます。リソースの allow-two-primaries オプションが yes に設定されているので、両ノードの リソースをプライマリにする ことができます。
11.3. DRBDリソースを認識するようにLVMを設定する
GFSでは、ブロックデバイスを利用するためにクラスタ対応版のLVMであるCLVMを使用しています。DRBDでCLVMを使用するために、LVMの設定を確認してください。
-
クラスタでのロックを行いますので、
/etc/lvm/lvm.confで以下のオプション設定をしてください。locking_type = 3 -
DRBDベースの物理ボリュームを認識させるためにDRBDデバイスをスキャンします。 これは、従来の(非クラスタの)LVMのように適用されます。 詳細は DRBDリソースを物理ボリュームとして構成する を参照してください。
11.4. GFS対応のためのクラスタ設定
新規DRBDリソースを作成し、 初期クラスタ設定を完了 したら、両ノードで以下のサービスを有効にして起動する必要があります。
-
cman(同時にccsdとfencedを起動します) -
clvmd.
11.5. GFSファイルシステムの作成
デュアルプライマリのDRBDリソースでGFSファイルシステムを作成するために、まず LVMの論理ボリューム として初期化する必要があります。
従来のクラスタ非対応のLVM設定とは異なり、CLVMはクラスタ対応のため以下の手順は必ず1ノードでのみ実行してください。
# pvcreate /dev/drbd/by-res/<resource>/0 Physical volume "/dev/drbd<num>" successfully created # vgcreate <vg-name> /dev/drbd/by-res/<resource>/0 Volume group "<vg-name>" successfully created # lvcreate --size <size> --name <lv-name> <vg-name> Logical volume "<lv-name>" created
| この例ではボリュームリソースが1つの場合を前提にしています。 |
CLVMは即座に変更を対向ノードに伝えます。lvs (または lvdisplay )を対向ノードで実行すれば、新規作成の論理ボリュームが表示されます。
ファイルシステムの作成を行います。
# mkfs -t gfs -p lock_dlm -j 2 /dev/<vg-name>/<lv-name>
GFS2ファイルシステムの場合は以下になります。
# mkfs -t gfs2 -p lock_dlm -j 2 -t <cluster>:<name> /dev/<vg-name>/<lv-name>
コマンド中の -j オプションは、GFSで保持するジャーナルの数を指定します。これは同時にGFSクラスタ内で同時に プライマリ になるノード数と同じである必要があります。DRBD9までは同時に2つより多い プライマリ ノードをサポートしていないので、ここで設定するのは常に2です。
-t オプションはGFS2ファイルシステムでのみ使用できます。ロックテーブル名を定義します。ここでは <cluster>:<name> の形式を使用し、 <cluster> は /etc/cluster/cluster.conf で定義したクラスタ名と一致する必要があります。そのため、そのクラスタメンバーのみがファイルシステムを使用することができます。一方で <name> はクラスタ内で一意の任意のファイルシステム名を使用できます。
11.6. GFSファイルシステムを使用する
ファイルシステムを作成したら、 /etc/fstab に追加することができます。
/dev/<vg-name>/<lv-name> <mountpoint> gfs defaults 0 0GFS2の場合にはファイルシステムタイプを変更します。
/dev/<vg-name>/<lv-name> <mountpoint> gfs2 defaults 0 0この変更は必ずクラスタの両ノードで行ってください。
設定が終わったら gfs サービスを(両ノードで)開始することで、新規ファイルシステムをマウントすることができます。
# service gfs start
以降、Pacemaker サービスと gfs サービスの前に DRBD がシステムの起動時に自動的に開始するように構成されていれば、従来の共有ストレージのようにGFSファイルシステムを使用することができます。
12. DRBDとOCFS2の使用
この章では、共有Oracle Cluster File Systemバージョン2 (OCFS2)を格納するブロックデバイスとしてDRBDリソースを設定する方法を説明します。
|
全クラスタファイルシステムには fencingが 必要 です。DRBDリソース経由だけでなくSTONITHもです。問題のあるノードは 必ず killされる必要があります。 次のような設定がよいでしょう。 net {
fencing resource-and-stonith;
}
handlers {
# Make sure the other node is confirmed
# dead after this!
outdate-peer "/sbin/kill-other-node.sh";
}
揮発性キャッシュは一切存在してはなりません! |
12.1. OCFS2 の概要
Oracle Cluster File Systemバージョン2 (OCFS2)は、Oracle Corporationが開発した同時アクセス共有ストレージファイルシステムです。前バージョンのOCFSはOracleデータベースペイロード専用に設計されていましたが、OCFS2はほとんどのPOSIXセマンティクスを実装する汎用ファイルシステムです。OCFS2の最も一般的なユースケースは、もちろんOracle Real Application Cluster (RAC)ですが、OCFS2は負荷分散NFSクラスタなどでも使用できます。
本来、OCFS2は従来の共有ストレージデバイス用に設計されたものですが、 dual-Primary DRBD でも問題なく使用できます。OCFS2が通常実行されるSANデバイスとは異なり、DRBDはローカルストレージに対して読み書きを行うため、ファイルシステムからデータを読み取るアプリケーションの読み取り待ち時間が短縮できるというメリットがあります。さらに、DRBDの場合は、単一のファイルシステムイメージを単に共有するのではなく、各ファイルシステムイメージにさらにコピーを追加するため、OCFS2に冗長性が加わります。
他の共有クラスターファイルシステム、例えばGFS など同様に、OCFS2は、データ破損のリスクを冒すことなく、複数のノードが同じストレージデバイスに対して読み取り/書き込みモードで同時にアクセスすることを可能にします。これは、クラスターノードからの同時アクセスを管理する分散ロックマネージャー(DLM)を使用することで実現されています。DLM自体は、システム上に存在する実際のOCFS2ファイルシステムとは別の仮想ファイルシステム(ocfs2_dlmfs)を使用します。
OCFS2は組み込みクラスタ通信層を使用して、クラスタメンバシップおよびファイルシステムのマウントとマウント解除操作を管理したり、これらのタスクを Pacemaker クラスタインフラストラクチャに委ねることができます。
OCFS2は、SUSE Linux Enterprise Server (OCFS2が主にサポートされる共有クラスタファイルシステム)、CentOS、Debian GNU/LinuxおよびUbuntu Server Editionで利用できます。また、OracleはRed Hat Enterprise Linux (RHEL)用のパッケージも提供しています。この章の説明は、SUSE Linux Enterprise ServerシステムでOCFS2を実行することを前提にしています。
12.2. OCFS2用のDRBDリソースの作成
OCFS2は共有クラスタファイルシステムで、すべてのクラスタノードからストレージに対して同時に読み取り/書き込みアクセスが行われることを前提としています。したがって、OCFS2ファイルシステムを格納するために使用するDRBDリソースは、 デュアルプライマリモード で設定する必要があります。また、スプリットブレインからの自動回復のための機能 を利用することをおすすめします。そのためには、以下の設定をリソース設定ファイルに加えてください。
resource <resource> {
net {
# allow-two-primaries yes;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
...
}
...
}|
回復ポリシーを設定することは、事実上、自動データロス設定を行うことです。十分にご理解のうえご使用ください。 |
最初の構成の際に allow-two-primaries オプションを yes にするのはお勧めできません。これは、最初のリソース同期が完了してから有効にしてください。
これらのオプションを 新規に設定したリソース に追加したら、 通常通りにリソースを初期化 できます。リソースの allow-two-primaries オプションを yes にすると、両方のノードのリソースをプライマリロールに 昇格 することができます。
12.3. OCFS2ファイルシステムの作成
OCFS対応の mkfs コマンドを使って、OCFS2ファイルシステムを作成します。
# mkfs -t ocfs2 -N 2 -L ocfs2_drbd0 /dev/drbd0 mkfs.ocfs2 1.4.0 Filesystem label=ocfs2_drbd0 Block size=1024 (bits=10) Cluster size=4096 (bits=12) Volume size=205586432 (50192 clusters) (200768 blocks) 7 cluster groups (tail covers 4112 clusters, rest cover 7680 clusters) Journal size=4194304 Initial number of node slots: 2 Creating bitmaps: done Initializing superblock: done Writing system files: done Writing superblock: done Writing backup superblock: 0 block(s) Formatting Journals: done Writing lost+found: done mkfs.ocfs2 successful
2ノードスロットOCFS2ファイルシステムが /dev/drbd0 に作成され、ファイルシステムのラベルが ocfs2_drbd0 に設定されます。mkfs の呼び出し時に、その他のオプションを指定することもできます。詳細は mkfs.ocfs2 システムマニュアルページを参照ください。
12.4. PacemakerによるOCFS2の管理
12.4.1. PacemakerにデュアルプライマリDRBDリソースを追加する
既存の デュアルプライマリDRBDリソース は、次の crm 設定でPacemakerリソース管理に追加することができます。
primitive p_drbd_ocfs2 ocf:linbit:drbd \
params drbd_resource="ocfs2"
ms ms_drbd_ocfs2 p_drbd_ocfs2 \
meta master-max=2 clone-max=2 notify=true
メタ変数 master-max=2 に注意してください。これはPacemakerのマスター/スレーブのデュアルマスターモードを有効にします。その場合、 allow-two-primaries も yes にDRBD設定で設定されている必要があります。設定していない場合にはリソースの検証中に設定エラーが発生します。
|
12.4.2. OCFS2をPacemakerで管理するには
OCFS2とロックマネージャ(DLM)の分散カーネルを管理するために、Pacemakerは、3つの異なるリソースエージェントを使用します。
-
ocf:pacemaker:controld— PacemakerのDLMに対してのインタフェース -
ocf:ocfs2:o2cb— PacemakerのOCFS2クラスタ管理へのインタフェース -
ocf:heartbeat:Filesystem— Pacemakerのクローンとして構成したときにクラスタファイルシステムをサポートする 汎用ファイルシステム管理リソース
次の crm 設定のように リソースグループのクローン を作成することによって、OCFS2の管理に必要なPacemakerリソースをすべてのノードで起動できます。
primitive p_controld ocf:pacemaker:controld
primitive p_o2cb ocf:ocfs2:o2cb
group g_ocfs2mgmt p_controld p_o2cb
clone cl_ocfs2mgmt g_ocfs2mgmt meta interleave=trueこの構成がコミットされると、Pacemakerは、クラスタ内のすべてのノードで controld と o2cb のリソースタイプのインスタンスを起動します。
12.4.3. PacemakerにOCFS2ファイルシステムを追加する
PacemakerはOCF2ファイルシステムにアクセスするのに、従来の ocf:heartbeat:Filesystem リソースエージェントを使います。これはクローンモードであっても同様です。Pacemakerの管理下にOCFS2ファイルシステムを配置するには、次の crm 設定を使用します。
primitive p_fs_ocfs2 ocf:heartbeat:Filesystem \
params device="/dev/drbd/by-res/ocfs2/0" directory="/srv/ocfs2" \
fstype="ocfs2" options="rw,noatime"
clone cl_fs_ocfs2 p_fs_ocfs2| この例ではボリュームリソースが1つの場合を前提にしています。 |
12.5. Pacemakerを使わないOCFS2管理
| OCFS2 DLMをサポートしない旧バージョンのPacemakerしか使えない場合、この節が参考になります。この節は以前の方式を使っている方の参照のためにだけ残してあります。新規インストールの場合には Pacemaker 方式を使ってください。 |
12.5.1. OCFS2をサポートするようにクラスタを設定する
設定ファイルの作成
OCFS2は主要な設定ファイルとして /etc/ocfs2/cluster.conf を使用します。
OCFS2クラスタを作成する際には、必ず、両方のホストを設定ファイルに追加してください。クラスタの相互接続通信には、通常はデフォルトポート(7777)が適切です。他のポート番号を選択する場合は、DRBD (および他の設定済みTCP/IP)が使用する既存のポートと衝突しないポートを選択する必要があります。
cluster.conf ファイルを直接編集したくない場合は、 ocfs2console というグラフィカルな構成ユーティリティを使用することもできます。通常はこちらのほうが便利です。いずれの場合も /etc/ocfs2/cluster.conf ファイルの内容はおおよそ次のようになります。
node:
ip_port = 7777
ip_address = 10.1.1.31
number = 0
name = alice
cluster = ocfs2
node:
ip_port = 7777
ip_address = 10.1.1.32
number = 1
name = bob
cluster = ocfs2
cluster:
node_count = 2
name = ocfs2クラスタ構成を設定したら、scp を使用して構成をクラスタの両方のノードに配布します。
SUSE Linux Enterprise Systems での O2CB ドライバの設定
SLESでは、 o2cb の起動スクリプトの configure オプションを利用することができます。
# /etc/init.d/o2cb configure
Configuring the O2CB driver.
This will configure the on-boot properties of the O2CB driver.
The following questions will determine whether the driver is loaded on
boot. The current values will be shown in brackets ('[]'). Hitting
<ENTER> without typing an answer will keep that current value. Ctrl-C
will abort.
Load O2CB driver on boot (y/n) [y]:
Cluster to start on boot (Enter "none" to clear) [ocfs2]:
Specify heartbeat dead threshold (>=7) [31]:
Specify network idle timeout in ms (>=5000) [30000]:
Specify network keepalive delay in ms (>=1000) [2000]:
Specify network reconnect delay in ms (>=2000) [2000]:
Use user-space driven heartbeat? (y/n) [n]:
Writing O2CB configuration: OK
Loading module "configfs": OK
Mounting configfs filesystem at /sys/kernel/config: OK
Loading module "ocfs2_nodemanager": OK
Loading module "ocfs2_dlm": OK
Loading module "ocfs2_dlmfs": OK
Mounting ocfs2_dlmfs filesystem at /dlm: OK
Starting O2CB cluster ocfs2: OK
Debian GNU/LinuxシステムにおけるO2CBドライバの設定
Debian GNU/Linuxシステム Debianの場合は、 /etc/init.d/o2cb の configure オプションは使用できません。代わりに、 ocfs2-tools パッケージを再設定してドライバを有効にします。
# dpkg-reconfigure -p medium -f readline ocfs2-tools Configuring ocfs2-tools Would you like to start an OCFS2 cluster (O2CB) at boot time? yes Name of the cluster to start at boot time: ocfs2 The O2CB heartbeat threshold sets up the maximum time in seconds that a node awaits for an I/O operation. After it, the node "fences" itself, and you will probably see a crash. It is calculated as the result of: (threshold - 1) x 2. Its default value is 31 (60 seconds). Raise it if you have slow disks and/or crashes with kernel messages like: o2hb_write_timeout: 164 ERROR: heartbeat write timeout to device XXXX after NNNN milliseconds O2CB Heartbeat threshold: `31` Loading filesystem "configfs": OK Mounting configfs filesystem at /sys/kernel/config: OK Loading stack plugin "o2cb": OK Loading filesystem "ocfs2_dlmfs": OK Mounting ocfs2_dlmfs filesystem at /dlm: OK Setting cluster stack "o2cb": OK Starting O2CB cluster ocfs2: OK
DRBDパフォーマンスの最適化
13. ブロックデバイスのパフォーマンス測定
13.1. スループットの測定
DRBDを使用することによるシステムのI/Oスループットへの影響を測定する際には、スループットの 絶対値 はほとんど意味がありません。必要なのは、DRBDがI/Oパフォーマンスに及ぼす 相対的 な影響です。したがって、I/Oスループットを測定する際には、必ずDRBDがある場合とない場合の両方を測定する必要があります。
| ここで説明するテストは過激なものです。データが上書きされるため、DRBDデバイスの同期が失われます。そのためこのテストは、テストが完了したら破棄できるスクラッチボリュームで行ってください。 |
I/Oスループットを見積もるには、比較的大きなデータチャンクをブロックデバイスに書き込み、システムが書き込み操作を完了するまでの時間を測定します。これは一般的なユーティリティである dd を使用して簡単に測定できます。比較的新しいバージョンにはスループット見積もり機能が組み込まれています。
簡単な dd ベースのスループットベンチマークは、たとえば次のようになります。ここでは、test という名前のスクラッチリソースが現在接続されており、両方のノードでセカンダリロールになっています。
# TEST_RESOURCE=test
# TEST_DEVICE=$(drbdadm sh-dev $TEST_RESOURCE | head -1)
# TEST_LL_DEVICE=$(drbdadm sh-ll-dev $TEST_RESOURCE | head -1)
# drbdadm primary $TEST_RESOURCE
# for i in $(seq 5); do
dd if=/dev/zero of=$TEST_DEVICE bs=1M count=512 oflag=direct
done
# drbdadm down $TEST_RESOURCE
# for i in $(seq 5); do
dd if=/dev/zero of=$TEST_LL_DEVICE bs=1M count=512 oflag=direct
doneこのテストでは、512MのデータチャンクをDRBDデバイスに書き込み、次に比較のために下位デバイスに書き込みます。両方のテストをそれぞれ5回繰り返し、統計平均を求めます。この結果は dd が生成したスループット測定値です。
新規に有効にしたDRBDデバイスの場合は、最初の dd 実行ではパフォーマンスがかなり低くなりますが、これは正常な状態です。アクティビティログがいわゆる「コールド」な状態のためで、問題はありません。
|
パフォーマンスの参考値については DRBDのスループット最適化 をご参照ください。
13.2. レイテンシの測定
レイテンシ測定はスループット測定とはまったく異なります。I/Oレイテンシテストでは非常に小さいデータチャンク(理想的にはシステムが処理可能な最も小さいデータチャンク)を書き込み、書き込みが完了するまでの時間を測定します。通常はこれを何度か繰り返して、通常の統計変動を相殺します。
スループットの測定と同様に、I/O待ち時間の測定にも一般的な dd ユーティリティを使用できますが、異なる設定とまったく異なった測定を行います。
以下は簡単な dd ベースの待ち時間のマイクロベンチマークです。ここでは、 test という名前のスクラッチリソースが現在接続されており、両方のノードでセカンダリロールになっています。
# TEST_RESOURCE=test
# TEST_DEVICE=$(drbdadm sh-dev $TEST_RESOURCE | head -1)
# TEST_LL_DEVICE=$(drbdadm sh-ll-dev $TEST_RESOURCE | head -1)
# drbdadm primary $TEST_RESOURCE
# dd if=/dev/zero of=$TEST_DEVICE bs=4k count=1000 oflag=direct
# drbdadm down $TEST_RESOURCE
# dd if=/dev/zero of=$TEST_LL_DEVICE bs=4k count=1000 oflag=directこのテストでは、4kiBのデータチャンクをDRBDデバイスに1,000回書き込み、次に比較のために下位デバイスにも1000回書き込みます。4096バイトはLinuxシステム(s390以外のすべてのアーキテクチャ)が扱うことができる最小のブロックサイズです。
dd が生成するスループット測定はこのテストではまったく意味がなく、ここで重要なのは、1,000回の書き込みが完了するまでにかかった時間です。この時間を1,000で割ると、1つのセクタへの書き込みの平均待ち時間を求めることができます。
| これは、シングルスレッドで厳密に1つずつ書き込みをしますので、最悪のケースではあります。つまり、I/O-depthが1の場合などです。 レイテンシ vs. IOPs をご参照ください。 |
参考情報として DRBDレイテンシの最適化 もご参照ください。
14. DRBDのスループット最適化
この章では、DRBDのスループットの最適化について説明します。スループットを最適化するためのハードウェアに関する検討事項と、チューニングを行う際の詳細な推奨事項について取り上げます。
14.1. ハードウェアの検討事項
DRBDのスループットは、配下のI/Oサブシステム(ディスク、コントローラおよび対応するキャッシュ)の帯域幅とレプリケーションネットワークの帯域幅の両方の影響を受けます。
I/Oサブシステムのスループットは主に並行して書き込み可能なストレージユニットの数と種類(ハードディスク、SSD、その他のフラッシュストレージ{FusionIOなど}…)によって決まります。比較的新しいSCSIまたはSASディスクの場合、一般に1つのディスクに約40MB/sでストリーミング書き込みを行うことができます。SSDなら300MiB/s、最新のフラッシュストレージ(NVMe)なら1GiB/sほどになります。ストライピング構成で配備する場合は、I/Oサブシステムにより書き込みがディスク間に並列化されます。 この場合、スループットは、1つのディスクのスループットに構成内に存在するストライプの数を掛けたものになります。RAID-0またはRAID-1`0構成で、 3つのストライプがある場合は同じ40MB/sのディスクのスループットが120MB/sになり、5つのストライプがある場合は200MB/sになります。SSDとNVMeまたはNVMeのみで構成すれば容易に1GiB/s超になるでしょう。
バッテリーバックアップされたバッファメモリを持つRAIDコントローラでは少量の書き込みの速度は、それらがバッファリングされることによって大幅に加速されます。非常に短い測定テストでは1GiBを示すかもしれません。持続的な書き込みではバッファがフルになるので速度は低下します。
| ハードウェアのディスクミラーリング (RAID-1) は、一般にスループットにはほとんど影響ありません。ディスクのパリティ付きストライピング (RAID-5) はスループットに影響し、通常はストライピングに比べてスループットが低下します。ソフトウェアRAIDのRAID-5やRAID-6であればさらに低下します。 |
Network throughput is usually determined by the amount of traffic present on the network, and on the throughput of any routing/switching infrastructure present. These concerns are, however, largely irrelevant in DRBD replication links which are normally dedicated, back-to-back network connections. Therefore, network throughput may be improved either by switching to a higher-throughput hardware (such as 10 Gigabit Ethernet, or 56 Gbit InfiniBand), or by using link aggregation over several network links, as one may do using the Linux bonding network driver.
14.2. DRBDのスループット最適化
DRBDに関連するスループットオーバヘッドを見積もる際には、 必ず次の制限を考慮してください。
-
DRBDのスループットは下位I/Oサブシステムのスループットにより制限される。
-
DRBDのスループットは使用可能なネットワーク帯域幅により制限される。
DRBDが使用できる理論上の 最大 スループットは上記の 小さい方 によって決まります。この最大スループットはDRBD自体のスループットオーバヘッドが加わることにより低下しますが、 これは3%未満だと考えられます。
-
たとえば、600MB/sのスループットが可能なI/Oサブシステムを持つ2つのクラスタノードが、 ギガビットイーサネットリンクで接続されているとします 。ギガビットイーサネットのスループットは 110MB/s程度だと考えられるため、 この構成ではネットワーク接続がボトルネックになります。 DRBDの最大スループットは110MB/s程度でしょう。
-
一方、I/Oサブシステムの持続した書き込みスループットが80MB/s程度の場合は、これがボトルネックとなり、DRBDの最大スループットはわずか77MB/sになります。
14.3. チューニングの推奨事項
DRBDには、システムのスループットに影響する可能性があるいくつかの構成オプションがあります。ここでは、スループットを向上させるための調整について、いくつかの推奨事項を取り上げます。ただし、スループットは主としてハードウェアに依存するため、ここで取り上げるオプションを調整しても、効果はシステムによって大きく異なります。パフォーマンスチューニングについて、必ず効く「特効薬」は存在しません。
14.3.1. max-buffers と max-epoch-size の設定
これらのオプションはセカンダリノードの書き込みパフォーマンスに影響します。max-buffers はディスクにデータを書き込むためにDRBDが割り当てるバッファの最大数で、 max-epoch-size は、2つの書き込みバリア間で許容される書き込み要求の最大数です。パフォーマンスを上げるためには max-buffers は max-epoch-size 以上でなければなりません。 デフォルト値は両方とも2048です。比較的高パフォーマンスのハードウェアRAIDコントローラの場合、この値を8000程度に設定すれば十分です。
resource <resource> {
net {
max-buffers 8000;
max-epoch-size 8000;
...
}
...
}14.3.2. TCP送信バッファサイズの調整
The TCP send buffer is a memory buffer for outgoing TCP traffic. By default, DRBD uses TCP send buffer auto-tuning (sndbuf-size set to 0), which dynamically selects an appropriate buffer size.
If you want to set a fixed buffer size instead, you can do so explicitly. For high-throughput networks (such as dedicated Gigabit Ethernet or load-balanced bonded connections), a size of 2MiB or more might help. Send buffer sizes of more than 16MiB are generally not recommended (and are also unlikely to produce any throughput improvement).
resource <resource> {
net {
sndbuf-size 2M;
...
}
...
}sysctl 設定の net.ipv4.tcp_rmen と net.ipv4.tcp_wmem は挙動に影響します。これらの設定を確認してください。またこれらを 131072 1048576 16777216 (最小128kiB、デフォルト1MiB、最大16MiB)にするとよいかもしれません。
net.ipv4.tcp_mem はまったく異なるものですので、変更しないでください。間違った値を指定すると、容易にマシンがout-of-memoryになってしまいます。
|
14.4. 冗長性を高め読み込み性能を向上させる
drbd.conf マニュアルページの read-balancing で説明の通り、データのコピーを追加することで読み込み性能を上げることができます。
概算: FusionIO カード利用の1ノードでの読み込み要求が fio では100kIOPsでしたが、 read-balancing を利用したた場合にはパフォーマンスが180kIOPsとなり、80%の性能向上が見られました!
読み込みのワークロードが多い環境の場合(ランダムリードが多い巨大なデータベースなど)では、read-balancing を有効にする意義があります。さらに読み込みIOスループットが欲しい場合にはコピーを増やすとよいでしょう。
15. DRBDレイテンシの最適化
この章では、DRBDのレイテンシの最適化について説明します。レイテンシを最小にするためのハードウェアに関する検討事項と、チューニングを行う際の詳細な推奨事項について取り上げます。
15.1. ハードウェアの検討事項
DRBDのレイテンシは、配下のI/Oサブシステム(ディスク、コントローラおよび対応するキャッシュ)のレイテンシとレプリケーションネットワークのレイテンシの両方の影響を受けます。
HDDなど 回転するメディア の場合、I/Oサブシステムのレイテンシには、主としてディスクの回転速度が影響します。したがって、高速回転のディスクを使用すればI/Oサブシステムのレイテンシが短縮します。
SSDなど 回転しないメディア の場合は、フラッシュストレージのコントローラが重要な要素です。次に重要なのは未使用容量です。DRBDの Trim/Discardのサポート を使用すると、コントローラーにどのブロックがリサイクル可能かについて必要な情報を渡すことができます。そのため書き込み要求があった時に、事前に使用可能になっているブロックを すぐ に使用する事ができ、書き込めるスペースが空くまで待つ必要がありません。[10]
同様に、BBWC (Battery-Backed Write Cache)を使用すると、書き込み完了までの時間が短くなり、書き込みのレイテンシを短縮できます。手頃な価格のストレージサブシステムの多くは何らかのバッテリバックアップキャッシュを備えており、管理者がキャッシュのどの部分を読み書き操作に使用するか設定できます。ディスク読み取りキャッシュを完全に無効にし、すべてのキャッシュメモリをディスク書き込みキャッシュとして使用する方法をお勧めします。
ネットワークレイテンシは、基本的にはホスト間の round-trip time (RTT)RTT (Packet Round-Trip Time)です。 これ以外にもいくつかの要因がありますが、そのほとんどは、DRBDレプリケーションリンクとして推奨する、DRBD専用回線接続の場合は問題になりません。イーサネットリンクには常に一定のレイテンシが発生しますが、ギガビットイーサネットでは通常、100〜200マイクロ秒程度のパケット往復時間です。
ネットワークレイテンシをこれより短くするには、レイテンシが短いネットワークプロトコルを利用する以外ありません。たとえば、Dolphin SuperSocketsのDolphin Express、10GBeの直結などを介してDRBDを実行します。これらの場合にはおよそ50マイクロ秒程になります。InfiniBandを利用するとさらにレイテンシが小さくなります。
15.2. DRBDレイテンシの最適化
スループットに関して、DRBDに関連するレイテンシオーバヘッドを見積もる際には、必ず次の制限を考慮してください。
-
DRBDのレイテンシは下位I/Oサブシステムのレイテンシにより制限される。
-
DRBDのレイテンシは使用可能なネットワークレイテンシにより制限される。
DRBDの理論上の 最小 待ち時間は、上記2つの 合計 です。[11]。さらにわずかなオーバヘッドが追加されますが、これは1%未満だと予測されます。
-
たとえば、ローカルディスクサブシステムの書き込みレイテンシが3msで、 ネットワークリンクのレイテンシが0.2msだとします予測されるDRBDの レイテンシは3.2msで、 ローカルディスクに書き込むだけのときと比べて約7%レイテンシが増加することになります。
| CPUのキャッシュミス、コンテキストスイッチなど、他にも待ち時間に影響する要因があります。 |
15.3. レイテンシ vs. IOPs
IOPs は “I/O operations per second” の略です。
一般的にマーケティングでは数字が小さくなったとは書かないものです。プレスリリースでは “レイテンシが10マイクロ秒小さくなって、50マイクロ秒から40秒になりました!” とは書かずに、 “パフォーマンスが25%向上し、20000から25000IPOsになりました!” と書きます。”大きいものは良い” のような事を言うためIOPsは作られました。
言い方を換えれば、IOPsとレイテンシは相互的なものです。 レイテンシの測定 で書いた方法は、純粋にシーケンシャルのシングルスレッドのIOロードのIOPsごとのレイテンシです。一方で、よくある他のドキュメントでは、見栄えのいい数字を出すために多重並行処理でのIOPsを使用している[12]という事を覚えておいてください。こういったトリックを使うのなら、どんなIOPsにでもできます。
そのため、シリアルのシングルスレッドでのレイテンシを敬遠しないでください。 もっとIOPsが欲しい場合には fio を threads=8 で iodepth=16 にするなどの設定をしてください。しかし、そうした数字はデータベースに多数のクライアントからのコネクションが同時にあった場合など以外には、意味がないという事を覚えておいてください。
15.4. チューニングの推奨事項
15.4.1. CPUマスクの設定
DRBDは、そのカーネルスレッドに明示的なCPUマスクを設定することができます。デフォルトでは、DRBDは各リソースに対して1つのCPUを選択します。このリソースのすべてのスレッドはこのCPUで実行されます。このポリシーは、CPUコアよりも多くのDRBDリソースがある場合に、最大の集約パフォーマンスを目指す際に一般的に最適です。代わりに、合計CPU使用量のコストで個々のリソースのパフォーマンスを最大化したい場合は、CPUマスクパラメータを使用して、DRBDスレッドが複数のCPUを使用することを許可できます。
さらに、詳細な調整が必要な場合は、アプリケーションスレッドの配置を対応するDRBDスレッドと調整することができます。アプリケーションの挙動や最適化目標に応じて、同じCPUを使用するか、またはスレッドを独立したCPUに分離するか、つまり、アプリケーションが使用しているCPUと同じCPUをDRBDが使用しないように制限することが有益である場合があります。
DRBDリソース構成で設定するCPUマスク値は、16進数の値です(あるいは、33番目以降のCPUコアを含むマスクを指定するために、カンマで区切られた16進数値の文字列)。最大で908個のCPUコアを含むマスクを指定することができます。
CPU マスクの最下位ビットは最初の CPU を表し、2 番目に重要なビットは 2 番目の CPU を表し、最大 908 個の CPU コアまで順に続きます。 マスクのバイナリ表現でセットされたビット(1)は、DRBD が対応する CPU を使用できることを意味します。 クリアされたビット(0)は、DRBD が対応する CPU を使用できないことを意味します。
たとえば、0x1のCPU マスク(バイナリで 00000001)は、DRBD が最初の CPU のみを使用することを意味します。0xCのマスク(バイナリで 00001100)は、DRBD が3番目と4番目の CPU を使用できることを意味します。
バイナリマスク値を、DRBDリソース構成ファイルに必要な16進値(または16進値の文字列)に変換するには、 bc ユーティリティがインストールされている必要があります。例えば、バイナリ数値00001100の16進値を取得し、CPUマスク値の文字列に必要なフォーマットを適用するには、以下のコマンドを入力します。
$ binmask=00001100
$ echo "obase=16;ibase=2;$binmask" | BC_LINE_LENGTH=0 bc | \
sed ':a;s/\([^,]\)\([^,]\{8\}\)\($\|,\)/\1,\2\3/;p;ta;s/,0\+/,/g' | tail -n 1
上記の sed コマンドは、 binmask 変数内のバイナリ数値から変換された16進数を、cpu-mask 文字列を解析する関数が期待する文字列形式に変換します。
|
これらのコマンドの出力は C になります。その後、この値をリソース構成ファイルで次のように使用して、DRBDを第三および第四のCPUコアのみを使用するように制限することができます:
resource <resource> {
options {
cpu-mask C;
...
}
...
}32個を超えるCPUを表すマスクを指定する必要がある場合は、32ビットの16進数値のリスト(コンマで区切られています)を使用する必要があります[13].]。最大で908 CPUコアまでサポートしており、文字列内で8桁の16進数(32ビット)ごとにコンマでグループを分ける必要があります。
複雑な作り話の例を挙げると、もしDRBDを908番目、35番目、34番目、5番目、2番目、1番目のCPUのみを使用するように制限したい場合は、CPUマスクを以下のように設定します:
$ binmask=10000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000011000000000000000000000000000010011
$ echo "obase=16;ibase=2;$binmask" | BC_LINE_LENGTH=0 bc | \
sed ':a;s/\([^,]\)\([^,]\{8\}\)\($\|,\)/\1,\2\3/;p;ta;s/,0\+/,/g' | tail -n 1
このコマンドの出力は次の通りです。
$ 800,,,,,,,,,,,,,,,,,,,,,,,,,,,6,13
その後、リソース構成でCPUマスクパラメータを次のように設定します:
cpu-mask 800,,,,,,,,,,,,,,,,,,,,,,,,,,,6,13
|
DRBDとこれを使用するアプリケーションとのCPU競合を最小限に抑えるためには、もちろん、DRBDが使用していないCPUだけをアプリケーションが使用するように設定する必要があります。 一部のアプリケーションは、DRBD自体と同様に、構成ファイルへのエントリを介してこれを実現する場合があります。他のアプリケーションでは、アプリケーションの初期化スクリプトで |
|
複数のDRBDスレッドに同一のL2/L3キャッシュを使わせることは意味があります。 しかし、CPUの番号付けは物理的なパーティションと一致する必要はありません。トポロジの概要を知るためには、X11用の |
15.4.2. ネットワークMTUの変更
レプリケーションネットワークの最大転送ユニット(MTU)サイズをデフォルトの1500バイトよりも大きくすることにはメリットがあります。いわゆる “ジャンボフレームを使用する” ことです。
MTUは、次のコマンドを使用して変更できます。
# ifconfig <interface> mtu <size>
または
# ip link set <interface> mtu <size>
<interface> にはDRBDのレプリケーションに使用するネットワークインタフェース名を指定します。<size> の一般的な値は9000 (バイト)です。
15.4.3. deadline I/Oスケジューラを有効にする
高性能なライトバックに対応したハードウェアRAIDコントローラを使う場合、CFQの代わりに単純な deadline をI/Oスケジューラに指定する方がDRBDのレイテンシを小さくできることがあります。通常はCFQがデフォルトで有効になっています。
I/Oスケジューラ構成に変更を加える場合は、/sys にマウントされる sysfs 仮想ファイルシステムを使用できます。スケジューラ構成は /sys/block/<device> に置かれています。<device>はDRBDが使用する下位デバイスです。
deadline スケジューラを有効にするには、次のコマンドを使用します。
# echo deadline > /sys/block/<device>/queue/scheduler
次の値も設定することにより、さらに待ち時間を短縮できます。
-
フロントマージを無効にします。
# echo 0 > /sys/block/<device>/queue/iosched/front_merges
-
読み取りI/O deadlineを150ミリ秒にします(デフォルトは500ms)。
# echo 150 > /sys/block/<device>/queue/iosched/read_expire
-
書き込みI/Oデッドラインを1500ミリ秒にします(デフォルトは3000ms)。
# echo 1500 > /sys/block/<device>/queue/iosched/write_expire
上記の値の変更により待ち時間が大幅に改善した場合は、システム起動時に自動的に設定されるようにしておくと便利です。Debianおよび Ubuntuシステムの場合は、 sysfsutils パッケージと /etc/sysfs.conf 設定ファイルでこの設定を行うことができます。
グローバルI/Oスケジューラを選択するには、カーネルコマンドラインを使用して elevator オプションを渡します。そのためには、ブートローダ構成(GRUBブートローダを使用する場合通常は /etc/default/grub に格納)を編集し、カーネルブートオプションのリストに elevator=deadline を追加します。
さらに詳しく知る
16. DRBDの内部
この章ではDRBDの内部アルゴリズムと内部構造について、 いくつか の背景情報を取り上げます。 これは、DRBDの背景について関心のあるユーザーが対象です。DRBD開発者が参考にできるほど深い内容には踏み込んでいません。開発者の方は 資料 に記載の文章やDRBDのソースコードを参照してください。
16.1. DRBDメタデータ
DRBDはレプリケートするデータに関するさまざまな情報を専用の領域に格納しています。メタデータには次のようなものがあります。
-
DRBDデバイスのサイズ
-
世代識別子(GI、詳細は 世代識別子 を参照)
-
アクティビティログ(AL、詳細は アクティビティログ )を参照
-
クイック同期ビットマップ(詳細は クイック同期ビットマップ を参照)
このメタデータは 内部 または 外部 に格納されます。格納する場所はリソースごとに設定できます。
16.1.1. 内部メタデータ
内部メタデータを使用するようにリソースを設定すると、DRBDはメタデータを実際の本稼働データと同じ下位レベルの物理デバイスに格納します。デバイスの 末尾 の領域がメタデータを格納するための領域として確保されます。
メタデータは実際のデータと密接にリンクされているため、ハードディスクに障害が発生しても、管理者は特に何かする必要はありません。メタデータは実際のデータとともに失われ、ともに復元されます。
RAIDセットではなく、下位レベルデバイスが唯一の物理ハードディスクの場合は、内部メタデータが原因で書き込みスループットが低下することがあります。アプリケーションによる書き込み要求の実行により、DRBDのメタデータの更新が引き起こされる場合があります。メタデータがハードディスクの同じ磁気ディスクに格納されている場合は、書き込み処理によって、ハードディスクの書き込み/読み取りヘッドが2回余分に動作することになります。
|
すでにデータが書き込まれているディスク領域を下位デバイスに指定してDRBDでレプリケートする場合で、内部メタデータを使うには、DRBDのメタデータに必要な領域を 必ず 確保してください。 そうでない場合、DRBDリソースの作成時に、新しく作成されるメタデータによって下位レベルデバイスの末尾のデータが上書きされ、既存のファイルが破損します。 |
以下のいずれかの方法でこれを避けることができます。
-
下位レベルデバイスを拡張します。これには、LVMなどの論理 ボリューム管理機能を使用します。 ただし、対応するボリュームグループに有効な空き領域が必要です。 ハードウェアストレージソリューションを使用することもできます。
-
下位レベルデバイスの既存のファイルシステムを縮小します。ファイルシステムによっては 実行できない場合があります。
-
上記2つが不可能な場合は、 代わりに 外部メタデータ を使用します。
下位レベルデバイスをどの程度拡張するか、またはファイルシステムをどの程度縮小するかについては、 メタデータサイズの見積り を参照してください。
16.1.2. 外部メタデータ
外部メタデータは、本稼働データを格納するものとは異なる個別の専用ブロックデバイスに格納します。
一部の書き込み処理では、外部メタデータを使用することにより、待ち時間をいくらか短縮できます。
メタデータが実際の本稼働データに密接にリンクされません。つまり、ハードウェア障害により本稼働データだけが破損したか、DRBDメタデータは破損しなかった場合、手動による介入が必要です。生き残ったノードから切り替えるディスクに、手動でデータの完全同期を行う必要があります。
次の項目の すべて に該当する場合には、外部メタデータ使用する以外の選択肢はありません。
-
DRBDでレプリケートしたい領域に すでにデータが格納されており、
-
この既存デバイスを拡張することができず、
-
デバイスの既存のファイルシステムが縮小をサポートしていない。
デバイスのメタデータを格納する専用ブロックデバイスが必要とするサイズにについては、 メタデータサイズの見積り を参照してください。
| 外部メータデータは少なくとも1MBのデバイスサイズを必要とします。 |
16.1.3. メタデータサイズの見積り
次の式を使用して、DRBDのメタデータに必要な領域を正確に計算できます。

Cs is the data device size in sectors, and N is the maximum number of peer bitmap slots configured in the metadata (bm-max-peers).
These formulas assume the default bitmap granularity of 4 KiB per bit. If you use a different bm-bytes-per-bit setting, the bitmap portion of the metadata scales inversely with the granularity.
|
デバイスサイズは(バイト単位で) blockdev --getsize64 <device> を実行して取得できます。MBに変換するときは1048576で割ってください(= 220または10242)
|
実際には、次の計算で得られる大まかな見積りで十分です。この式では、単位はセクタではなくメガバイトである点に注意してください。

16.2. 世代識別子
DRBD世代識別子(GI)は、DRBDリソースのメタデータに含まれる情報であり、複製されたデータの「世代」、いわゆる「データ世代」を識別するためのものです。GIは、例えば、あるノードのリソースデータが別のノードよりも古いことを判断するために使用されます。
この基本的な用途以外にも、DRBDは内部的に以下の目的でGIを使用します。
-
2つのノードが実際に同じクラスタのメンバか確認する (2つのノードが誤って接続されたものではないこと確認する)。
-
完全な再同期が必要か、 部分的な再同期で十分か判断する。
-
バックグラウンド同期の方向を確認する (必要な場合)。
-
スプリットブレインの認識
16.2.1. データ世代
リソースが Connected 接続状態にあり、クラスター内のノードのディスク状態が UpToDate である場合は常に、それらのノード上の現在のデータ世代は同一です。
DRBDは次のような場合に、新しい データ世代 の開始としてマークを付けます。
-
初期デバイスの完全同期、
-
ピアから切断されたプライマリノード
-
切断したリソースがプライマリロールに切り替わる。
primary --force が使用される場合を除き、DRBDはリソースへの次回のデータ書き込み時に新しい世代の開始をマークします。これは、イベントが発生してからしばらく経過した後になる可能性があります。
UUIDの実装では、最下位ビットを使用してノードの役割(プライマリまたはセカンダリ)をエンコードします。そのため、クラスター内のノード間で最下位ビットが異なることがあっても、それらのノードは依然として同じデータ世代を持つと見なすことができます。
16.2.2. 世代識別子
DRBDでは、現在と履歴のデータ世代についての情報がローカルリソースメタデータに格納されます。
これは、ローカルノードからみた最新のデータ世代の世代識別子です。リソースが Connected になり完全に同期されると、両ノードのカレントUUIDが同一になります。
リモードホストごとに変更を追跡しているオンディスクのビットマップの世代のUUIDです。オンディスク同期ビットマップ自体と同様に、リモートホストと切断されてい場合のみ意味を持ちます。
These are the identifiers of preceding data generations, maintained as a rolling history. New entries are pushed to the front, and older entries are shifted out when the buffer is full.
16.2.3. 世代識別子の変化
DRBD 9におけるGIの更新タイミングは、DRBD 8とは異なります。ノードが新しいGIを生成し、世代識別子(generation identifiers)を更新するのは、以下の条件において*最初のデータ書き込み時(またはI/O完了時)*です。
-
ノードが Primary ロールにあり、以前に確立されたレプリケーションリンクが失われた、すなわちセカンダリピアノードに接続できない状態です。
-
ノードは Secondary ロールにあり、 Primary に昇格されましたが、1つ以上のピアと通信できません。
また、デュアルプライマリモードのクラスターでは、もう一方のプライマリノードとの接続が失われた場合、プライマリノードは新しいGIを生成しません。
DRBD 9におけるGIの更新方法は、ノードが Primary になった後に書き込みを行わなかった場合のデータの不整合(スプリットブレイン)を防ぐことができるため、DRBD 8から改善されています。
次の図は、プライマリノード上のリソースにおけるジェネレーション識別子の変更前後の例を示しています。

-
新規データ世代の開始時に変化するGIタプル
-
プライマリノードは新しいUUIDを作成します。これが、そのプライマリノードの新たな現在のUUIDとなります。
-
「直前の」現在のUUIDは、切断されているピアに対してのみ、新しいビットマップUUIDになります。先述の通り、ビットマップUUIDは、クイックシンク・ビットマップが変更を追跡している対象のデータ世代を指します。
16.2.4. 世代識別子とDRBDの状態
ノード間の接続が確立すると、2つのノードは現在入手可能な世代識別子を交換し、それに従って処理を続行します。結果は次のようにいくつか考えられます。
ローカルノードと対向ノードの両方でカレントUUIDが空の状態です。新規に構成され、初回フル同期が完了していない場合は、通常この状態です。同期が開始していないため、手動で開始する必要があります。
対向ノードのカレントUUIDが空で、自身は空でない場合です。これは、ローカルノードを同期元とした初期フル同期が進行中であることを表します。ローカルノードのDRBDはディスク上の同期ビットマップのすべてのビットを1にして、ディスク全体が非同期だと マークします。その後ローカルノードを同期元とした同期が始まります。逆の場合(ローカルのカレントUUIDが空で、対向ノードが空でない場合)は、DRBDは同様のステップをとります。ただし、ローカルノードが同期先になります。
ローカルのカレントUUIDと対向ノードのカレントUUIDが空でなく、同じ値を持っている状態です。両ノードがともにセカンダリで、通信切断中にどのノードもプライマリにならなかったことを表します。この状態では同期は必要ありません。
ローカルノードのビットマップUUIDが対向ノードのカレントUUIDと一致し、対向ノードのビットマップUUIDが空の状態です。これは、ローカルノードがプライマリで動作している間にセカンダリノードが停止して再起動したときに生じる正常な状態です。これは、リモートノードは決してプライマリにならず、ずっと同じデータ世代にもとづいて動作していたことを意味します。この場合、ローカルノードを同期元とする通常のバックグラウンド再同期が開始します。逆に、ローカルノード 自身の ビットマップUUIDが空で、 対向ノードの ビットマップがローカルノードのカレントUUIDと一致する状態の場合は、これはローカルノードの再起動に伴う正常な状態です。そして、ローカルノードを同期先とする通常のバックグラウンド再同期が開始します。
ローカルノードのカレントUUIDが対向ノードの履歴UUIDのうちの1つと一致する状態です。これは過去のある時点では同じデータを持っていたが、現在は対向ノードが最新のデータを持ち、しかし対向ノードのビットマップUUIDが古くなって使用できない状態です。通常の部分同期では不十分なため、ローカルノードを同期元とするフル同期が開始します。DRBDはデバイス全体を非同期状態とし、ローカルノードを同期先とするバックグラウンドでのフル再同期を始めます。逆の場合(ローカルノードの履歴UUIDのうち1つが対向ノードのカレントUUIDと一致する)、DRBDは同様のステップを行いますが、ローカルノードが同期元となります。
ローカルノードのカレントUUIDが対向ノードのカレントUUIDと異なるが、ビットマップUUIDは一致する状態はスプリットブレインです。ただし、データ世代は同じ親を持っています。この場合、設定されていればDRBDがスプリットブレイン自動回復ストラテジが実行されます。設定されていない場合、DRBDはノード間の通信を切断し、手動でスプリットブレインが解決されるまで待機します。
ローカルノードのカレントUUIDが対向ノードのカレントUUIDと異なり、ビットマップUUIDも 一致しない 状態です。これもスプリットブレインで、しかも過去に同一のデータ状態であったという保証もありません。したがって、自動回復ストラテジが構成されていても役に立ちません。DRBDはノード間通信を切断し、手動でスプリットブレインが解決されるまで待機します。
最後は、DRBDが2つのノードのGIタプルの中に一致するものを1つも検出できない場合です。この場合DRBDは、”Unrelate data”という警告をログに書き込んでコネクションを切断します。これは、相互にまったく関連のない2つのクラスタノードが誤って接続された場合に備えるDRBDの機能です。
16.3. アクティビティログ
16.3.1. 目的
書き込み操作中に、DRBDは書き込み操作をローカルの下位ブロックデバイスに転送するだけでなく、ネットワークを介して送信します。実用的な目的で、この2つの操作は同時に実行されます。タイミングがランダムな場合は、書込み操作が完了しても、ネットワークを介した転送がまだ始まっていないといった状況が発生する可能性があります。その逆の場合もあります。
この状況で、アクティブなノードに障害が発生してフェイルオーバが始まると、このデータブロックのノード間の同期は失われます。障害が発生したノードにはクラッシュ前にデータブロックが書き込まれていますが、レプリケーションはまだ完了していません。そのため、ノードが回復しても、このブロックは回復後の同期のデータセット中から取り除かれる必要があります。さもなくば、クラッシュしたノードは生き残ったノードに対して「先書き」状態となり、レプリケーションストレージの「オール・オア・ナッシング」の原則に違反してしまいます。これはDRBDだけでなく、実際、すべてのレプリケーションストレージの構成で問題になります。バージョン0.6以前のDRBDを含む他の多くのストレージソリューションでは、アクティブなノードに障害が発生した場合、回復後にそのノードを改めてフル同期する必要があります。
バージョン0.7以降のDRBDは、これとは異なるアプローチを採用しています。 アクティビティログ (AL)は、メタデータ領域にに格納され、「最近」書き込まれたブロックを追跡します。この領域は ホットエクステント と呼ばれます。
アクティブモードだったノードに一時的な障害が発生し、同期が行われる場合は、デバイス全体ではなくALでハイライトされたホットエクステントだけが同期されます。(それに加えて現在アクティブな対向ノードのビットマップのマークされたブロックも)これによって、アクティブなノードがクラッシュしたときの同期時間を大幅に短縮できます。
16.3.2. アクティブエクステント
アクティビティログの設定可能なパラメータに、アクティブエクステントの数があります。アクティブエクステントは4MiB単位でプライマリのクラッシュ後に再送されるデータ量に追加されます。このパラメータは、次の対立する2つの状況の折衷案としてご理解ください。
大量のアクティビティログを記録すれば書き込みスループットが向上します。新しいエクステントがアクティブになるたびに、古いエクステントが非アクティブにリセットされます。この移行には、メタデータ領域への書き込み操作が必要です。アクティブエクステントの数が多い場合は、古いアクティブエクステントはめったにスワップアウトされないため、メタデータの書き込み操作が減少し、その結果パフォーマンスが向上します。
アクティビティログが小さい場合は、アクティブなノードが障害から回復した後の同期時間が短くなります。
16.3.3. アクティビティログの適切なサイズの選択
エクステントの数は所定の同期速度における適切な同期時間にもとづいて定義します。アクティブエクステントの数は次のようにして算出できます。

R はMiB/秒単位の同期速度、tsync 秒単位のターゲットの同期時間です。E は求めるアクティブエクステントの数です。
スループット速度が200MiByte/秒のI/Oサブシステムがあり、同期速度(R)が60MiByte/sに設定されているとします。ターゲットの同期時間( tsync ) は4分または240秒を維持する必要があります。

また、最後に付け加えると、DRBD9ではデータを他のセカンダリノードへ同期させるので、セカンダリノードでもALを維持する必要があります。
16.4. クイック同期ビットマップ
クイック同期ビットマップはDRBDが各対向ノードがリソースごとに使用する内部データ構造で、同期ブロック(両方のノードで同一)または非同期ブロックを追跡します。ビットマップはノード間通信が切断しているときのみ使われます。
In the quick-sync bitmap, one bit represents a chunk of on-disk data. By default, each bit covers 4 KiB, but since DRBD 9.3, this is configurable up to 1 MiB per bit. If the bit is cleared, it means that the corresponding block is still in sync with the peer node. That implies that the block has not been written to since the time of disconnection. Conversely, if the bit is set, it means that the block has been modified and needs to be re-synchronized whenever the connection becomes available again.
スタンドアロンノードでディスクにデータが書き込まれると、クイック同期ビットマップへの書き込みも始まります。ディスクへの同期的なI/Oは負荷が大きいため、実際にはメモリ上のビットマップのビットがセットされます。 アクティビティログ が期限切れになってブロックがコールドになると、メモリ上のビットマップがディスクに書き込まれます。同様に、生き残ったスタンドアロンのノードでリソースが手動でシャットダウンされると、DRBDは すべての ビットマップをディスクにフラッシュします。
リモートノードが回復するか接続が再確立すると、DRBDは両方のノードのビットマップ情報を照合して、再同期が必要な すべてのデータ領域 を決定します。同時にDRBDは 世代識別子 を調べ、同期の 方向 を決定します。
同期元ノードが同期対象ブロックを対向ノードに送信し、同期先が変更を確認すると、ビットマップの同期ビットがクリアされます。その後再開すると、中断した箇所から同期を続行します。 — 中断中にブロックが変更された場合、もちろんそのブロックが再同期データセットに追加されます。
drbdadm pause-sync と drbdadm resume-sync コマンドを使用して、再同期を手動で一時停止したり再開することもできます。ただしこれは慎重に行ってください。再同期を中断すると、セカンダリノードのディスクが必要以上に長く Inconsistent 状態になります。
|
16.5. peer fencingインタフェース
DRBD has an interface defined for fencing[14] the peer node in case of the replication link being interrupted. The fence-peer should mark the disk(s) on the peer node as Outdated, or shut down the peer node. It has to fulfill these tasks under the assumption that the replication network is down.
fencingヘルパーは次のすべてを満たす場合にのみ呼び出されます。
-
リソース(または
common)のhandlersセクションでfence-peerハンドラが定義されており -
fencingオプションで、resource-onlyまたはresource-and-stonithが設定されており、 -
ノードはプライマリであり、レプリケーションリンクが中断される時間が長すぎて、DRBD[15]がネットワーク障害を検知します。
-
ノードはプライマリにプロモートする必要があり、対向ノードに接続されておらず、対向ノードのディスクはまだ Outdated としてマークされていない
fence-peer ハンドラとして指定されたプログラムかスクリプトが呼び出されると、 DRBD_RESOURCE と DRBD_PEER 環境変数が利用できるようになります。これらの環境変数には、それぞれ、影響を受けるDRBDリソース名と対向ホストのホスト名が含まれています。
peer fencingヘルパープログラム(またはスクリプト)は、次のいずれかの終了コードを返します。
| 終了コード | 意味 |
|---|---|
3 |
対向ノードのディスク状態はすでに Inconsistent でした。 |
4 |
対向ノードのディスク状態が正常に Outdated に設定されました(あるいは最初から Outdated でした)。 |
5 |
対向ノードへの接続に失敗しました。ノードに到達できません。 |
6 |
対象のリソースがプライマリロールであったため、対向ノードの outdated 設定が拒否されました。 |
7 |
対向ノードは正常にクラスターからフェンシングされました。対象のリソースに対して |
16.6. クライアントモード
バージョン 9.0.13 以降、DRBD はクライアントモードをサポートします。 DRBD クライアントは、永続的にディスクレスノードです。下位ブロックデバイスにキーワード none ( disk キーワード) を使用して構成します。 drbdsetup status の出力に Diskless ディスクのステータスが緑色で表示されます(通常 Diskless のディスク状態は赤で表示されます)。
内部的には、意図的なディスクレスノードのすべての対向ノードは peer-device-option --bitmap=no で構成されています。つまり、意図的なディスクレスでは、対向ノードのメタデータにビットマップスロットを割り当てないということです。意図的なディスクレスノードでは、デバイスは drbdsetup のサブコマンド new-minor で作成されている間、オプション --diskless=yes でマークされます。
これらのフラグは events2 ステータスコマンドで表示できます。
-
deviceはclient:フィールドを持つかもしれません。yesで表示された場合、ローカルデバイスは永続的にディスクレスであるとマークされています。 -
peer-deviceはpeer-clientフィールドを持つかもしれません。yesで表示された場合、その対向ノードへの変更追跡ビットマップはありません。
関連するコマンドと影響
-
ビットマップスロットが割り当てられるため、メタデータでビットマップスロットが使用可能な場合にのみ
drbdsetup peer-device-options --bitmap=yes …を実行できます。 -
コマンド
drbdsetup peer-device-options --bitmap=no …は、対向ノードがディスクレスの場合にのみ可能であり、ビットマップスロットの割り当てを解除しません。 -
drbdsetup forget-peer …は、特定の対向ノードに割り当てられたビットマップスロットを解放するために使用されます。 -
1つ(または両方)が対向ノードが永続的にディスクレスであると予想する場合に、2つの対向ノードに接続すると失敗します。
17. 詳細情報の入手
17.1. 商用DRBDのサポート
DRBDの商用サポート、コンサルティング、トレーニングサービスは、プロジェクトのスポンサ企業LINBIT社が提供しています。日本では LINBIT 社との提携にもとづいてサイオステクノロジー株式会社が各種サポートを提供しています。
17.2. Community forum
LINBIT maintains a community forum for asking questions, sharing knowledge, getting software release announcements, and learning about how others might be using DRBD and other LINBIT software. You can join or browse the LINBIT Community Forum at: https://forums.linbit.com.
17.3. Official X account
LINBIT maintains an official X (formerly Twitter) account.
If you post about DRBD, please include the #drbd hashtag.
17.4. 資料
DRBDの開発者により作成されたDRBD一般やDRBDの特定の機能についての文書が公開されています。その一部を次に示します。
-
Philipp Reisner. DRBD 9 – What’s New, 2012.
-
Lars Ellenberg. DRBD v8.0.x and beyond, 2007.
-
Philipp Reisner. DRBD v8 – Replicated Storage with Shared Disk Semantics, 2007.
-
Philipp Reisner. Rapid resynchronization for replicated storage, 2006.
17.5. その他の資料
-
現在お読みのユーザーガイドに加えて、LINBITは the LINBIT website を通じて利用可能な、ハウツーガイドやビデオチュートリアル、説明記事などのさらなるドキュメントを提供しています。
-
LINBITはDRBD向けの公式トレーニングコースを提供しています。 DRBD Basics
-
Wikipediaには DRBDの記事 があります。
-
ClusterLabs website には、高可用性クラスターでのDRBDの使用に関する役立つ情報が掲載されています。
付録
付録 A: 最近の変更
この付録は以前のバージョンから DRBD 9.x にアップグレードするユーザー向けです。DRBDの設定と挙動についての重要な変更点を説明します。
A.1. DRBD 9.3 changelog
You can find an itemized list of updates, fixes, and changes to the DRBD 9.3 branch at the project’s open source codebase repository: https://github.com/LINBIT/drbd/blob/master/ChangeLog
いくつかのハイライトは次の通りです:
-
Resync without replication (default). The resync operation begins with application write mirroring disabled and performs multiple passes to clear bitmap bits. Mirroring is enabled when resync is nearly complete, reducing I/O load and resync time.
-
Support for configurable bitmap granularity between 4 KiB and 1 MiB per bit, including exchanging bitmaps with peers that use a different bitmap block size.
-
Use compound pages to optimize large I/O performance.
A.2. DRBD 9.2 changelog
You can find an itemized list of updates, fixes, and changes to the DRBD 9.2 branch at the project’s open source codebase repository: https://github.com/LINBIT/drbd/blob/drbd-9.2/ChangeLog
いくつかのハイライトは次の通りです:
-
RDMA transport の追加
-
アプリケーションの I/O が連続している場合でも、再同期を続行できるようにした。
-
“bottom half” コンテキストで制御ソケットパケットを直接処理します。これにより、待ち時間が短縮され、パフォーマンスが向上します。
-
再同期時により多くの破棄を実行します。破棄の粒度の倍数で再同期します。
-
ネットワーク名前空間をサポートして、コンテナーや Kubernetes などのオーケストレーターとの統合を改善します。
A.3. DRBD 9.1 changelog
DRBD 9.1 ブランチのアップデート、修正、変更の項目別リストは、プロジェクトのオープンソースコードベースリポジトリで見つけることができます。以下のリンクからご確認いただけます:https://github.com/LINBIT/drbd/blob/drbd-9.1/ChangeLog
いくつかのハイライトは次の通りです:
-
送信パスでのロック競合を減らします。これにより、複数の対向ノードまたは高い I/O 深度を持つワークロードのパフォーマンスが向上します。
-
クォーラムの損失による中断された I/O を含むさまざまなシナリオのサポートを改善します。
A.4. DRBD 8.4 からの変更点
DRBD 8.4 から DRBD 9.x に移行する場合、いくつかの注目すべき変更点について、以下のサブセクションで詳しく説明します。
A.4.1. コネクション
DRBD 9では、データを2つ以上のノード間でレプリケーションできます。
そのためDRBDボリュームのスタック利用はもはや(可能ではありますが)推奨しません。 また、DRBDをネットワークブロックデバイス(DRBD client)として利用する事が可能になりました。
関連する変更項目
-
メタデータサイズの変更(対向ノードごとに1ビットマップ)
-
/proc/drbdでは最小限の情報のみを表示。drbdadm status参照 -
再同期の同期元/先が 複数の対向ノード に。
A.4.2. 自動プロモーション 機能
DRBD 9は、必要に応じて自動で プライマリ / セカンダリ の ロール切り替え を設定できます。
この機能は、 become-primary-on の設定ならびにHeartbeat v1の drbddisk スクリプトを無用にするものです。
詳細は リソースの自動プロモーション を参照してください。
付録 B: DRBDを8.4から9.xにアップグレードする
このセクションでは、DRBDをバージョン8.4.xから9.xにアップグレードするプロセスについて詳しく説明します。バージョン9内でのアップグレードや特定のDRBD 9.xバージョンにアップグレードする際の特別な考慮事項については、このガイドの 「DRBDのアップグレード」D 章を参照してください。
B.1. 互換性
DRBD 9.a.bのリリースは一般的にDRBD 8.c.dとプロトコル互換性があります。特に、DRBD 9.a.bのすべてのリリースが、DRBD 8.c.dと互換性があることが示されていますが、DRBD 9.1.0から9.1.7までのリリースは互換性がありません。
B.2. 一般的な概要
8.4 から 9.x へのアップグレード手順の概要は以下の通りです。
-
LINBIT のパッケージを使用している場合、 新しいリポジトリ を設定してください。
-
現在の状況が 問題ないこと を確認してください。
-
クラスターマネージャーを 一時停止 してください。
-
新しいバージョン 新しいバージョンをインストールするためにパッケージをアップグレードしてください。
-
もしあなたが2つ以上のノードに移動したい場合、追加のメタデータのために下位ストレージをリサイズする必要があります。このトピックは、 LVMチャプター で議論されています。
-
リソースの設定を無効にし、DRBD 8.4 をアンロードし、 v9 カーネルモジュールをロード してください。
-
DRBDのメタデータ をv09形式に変換し、同時にビットマップの数を変更することもできます。
-
クラスターマネージャーを使用している場合は、 DRBDリソースを開始し 、クラスターノードを再び オンライン にします。
B.3. リポジトリのアップデート
8.4 ブランチと 9.x ブランチの間で多くの変更があったため、LINBIT はそれぞれに個別のリポジトリを作成しました。 LINBIT の顧客または評価アカウントをお持ちの場合、マシンに LINBIT のソフトウェアをインストールする最良の方法は、 Python ヘルパー クリプト をダウンロードし、ターゲットマシンで実行することです。
B.3.1. LINBITリポジトリの有効化にはLINBIT Manage Node Helperスクリプトを使用
LINBITのヘルパースクリプトを実行することで、特定のLINBITパッケージリポジトリを有効にすることができます。DRBD 8.4からアップグレードする際には、 drbd-9 パッケージリポジトリを有効にすることをお勧めします。
ヘルパースクリプトには、drbd-9.0 パッケージリポジトリを有効にするオプションがありますが、これは DRBD 8.4 からアップグレードするための推奨される方法ではありません。なぜなら、そのブランチには DRBD 9.0 および関連ソフトウェアしか含まれていないからです。将来的にはおそらく廃止され、drbd-9 パッケージリポジトリで利用できる DRBD バージョン 9.1 以降は、バージョン 8.4 とプロトコル互換性があります。
|
drbd-9 リポジトリを有効化するためにスクリプトを使用するには、このガイド内の指示を参照してください。「LINBITヘルパースクリプトを使用してノードを登録しパッケージリポジトリを構成する方法」 のセクションを参照してください。
B.3.2. Debian/Ubuntu システム
LINBIT パッケージリポジトリを使用して DRBD 8.4 を 9.1 に更新する場合、LINBIT は現在、Focal (20.04) と Jammy (22.04) の 2 つの LTS Ubuntu バージョンのみを最新に保つことに注意してください。DRBD v8.4 を実行している場合は、これらよりも古いバージョンの Ubuntu Linux を使用している可能性があります。ヘルパースクリプトを使用して LINBIT パッケージ リポジトリを追加し、DRBD を更新する前に、まずシステムを LINBIT がサポートする LTS バージョンに更新する必要があります。
B.4. DRBD の状態を確認する
DRBDを更新する前に、リソースが同期しているか確認してください。cat /proc/drbd の出力には、リソースが「UpToDate/UpToDate」の状態であることが表示されるはずです。
node-2# cat /proc/drbd
version: 8.4.9-1 (api:1/proto:86-101)
GIT-hash: [...] build by linbit@buildsystem, 2016-11-18 14:49:21
GIT-hash: [...] build by linbit@buildsystem, 2016-11-18 14:49:21
0: cs:Connected ro:Secondary/Secondary ds:UpToDate/UpToDate C r-----
ns:0 nr:211852 dw:211852 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:d oos:0
cat /proc/drbd コマンドは、リソース ステータス情報を取得するための DRBD バージョン 9.x で廃止されました。 DRBD をアップグレードした後、 drbdadm status コマンドを使用してリソースのステータス情報を取得します。
|
B.5. サービスの一時停止
リソースが同期されていることがわかったので、まずはセカンダリーノードのアップグレードを開始してください。これは、手動で行うか、クラスターマネージャーのドキュメントに従って行うことができます。 両方の手順について以下で説明します。クラスタマネージャーとしてPacemakerを使用している場合は、手動方法を使用しないでください。
B.6. パッケージのアップグレード
パッケージをアップデートします。
RHEL/CentOS:
node-2# dnf -y upgrade
Debian/Ubuntu:
node-2# apt-get update && apt-get upgrade
アップグレードが完了すると、セカンダリノードである「node-2」に最新のDRBD 9.xカーネルモジュールと「drbd-utils」がインストールされます。
しかしカーネルモジュールはまだ有効化されていません。
B.7. 新しいカーネルモジュールのロード
現時点では、もはやDRBDモジュールを使用していないはずなので、次のコマンドを入力してアンロードしてください:
node-2# rmmod drbd_transport_tcp; rmmod drbd
” ERROR : Module drbd is in use ” のようなメッセージが出る場合は、まだすべてのリソースが正常に停止していません。
パッケージのアップグレード を再試行するか、コマンド drbdadm down all を実行して、まだアクティブなリソースを特定してください。
よくあるアンロードを妨げる原因には以下のものがあります。
-
DRBDが下位デバイスのファイルシステムにNFSエクスポートがある(
exportfs -vの出力を確認) -
ファイルシステムはまだマウントされています。
grep drbd /proc/mountsをチェックしてください。 -
ループバックデバイスがアクティブ (
losetup -l) -
デバイスマッパーが直接または間接的にDRBDを使用している。(
dmsetup ls --tree) -
DRBD-PV(
pvs)の LVM
| 上記はよくあるケースであり、すべてのケースを網羅するものではないという事に注意ください。 |
これで、DRBDモジュールをロードすることができます。
node-2# modprobe drbd
次に、ロードされている DRBD カーネル モジュールのバージョンが更新された 9.x バージョンであることを確認できます。インストールされたパッケージが間違ったカーネル バージョン用である場合、modprobe は成功しますが、drbdadm --version コマンドからの出力は、DRBD カーネル バージョン (DRBD_KERNEL_VERSION_CODE) がまだ古い 8.4 (16 進数で 0x08040) バージョンになります。
‘drbdadm –version’ の出力は 9.x.y を表示し、次のようになっているでしょう。
DRBDADM_BUILDTAG=GIT-hash:\ [...]\ build\ by\ @buildsystem\,\ 2022-09-19\ 12:15:10 DRBDADM_API_VERSION=2 DRBD_KERNEL_VERSION_CODE=0x09010b DRBD_KERNEL_VERSION=9.1.11 DRBDADM_VERSION_CODE=0x091600 DRBDADM_VERSION=9.22.0
メインのノードである node-1 では、drbdadm --version を実行すると、引き続き次の情報が表示されます。
|
B.8. 設定ファイルの移行
DRBD 9.x は 8.4 の設定ファイルに後方互換性がありますが、一部の構文は変更しています。変更点の全一覧は 設定上の構文の変更点 を参照してください。’drbdadm dump all’ コマンドを使えば古い設定を簡単に移すことができます。これは、新しいリソース設定ファイルに続いて新しいグローバル設定も両方とも出力します。この出力を使って適宜変更してください。
B.9. メタデータの変更
ここで、ディスク上のメタデータを新しいバージョンに変換する必要があります。 drbdadm create-md コマンドを使用して 2 つの質問に答えるだけです。
たくさんのノードを変更したい場合には、追加のビットマップに十分なスペースを確保するため、すでに下位デバイスの容量を拡張していることでしょう。この場合には以下のコマンドを追加の引数 --max-peers=<N> を付けて実行します。対向ノードの数(予定)を決める時には、 DRBDクライアント も考慮に入れてください。
# drbdadm create-md <resource> You want me to create a v09 style flexible-size internal meta data block. There appears to be a v08 flexible-size internal meta data block already in place on <disk> at byte offset <offset> Valid v08 meta-data found, convert to v09? [need to type 'yes' to confirm] yes md_offset <offsets...> al_offset <offsets...> bm_offset <offsets...> Found some data ==> This might destroy existing data! <== Do you want to proceed? [need to type 'yes' to confirm] yes Writing meta data... New drbd meta data block successfully created. success
もちろん、リソース名に all を渡すこともできます。また、運が良ければ、勇気があれば、あるいはその両方であれば、次のように --force フラグを使用して質問を回避できます。
drbdadm -v --max-peers=<N> -- --force create-md <resources>
| これらの引数の順序は重要です。このコマンドを入力する前に、このコマンドの潜在的なデータ損失の意味を理解していることを確認してください。 |
B.10. DRBDを再起動します
あとはDRBDデバイスを再びupにして起動するだけです。単純に、 drbdadm up all で済みます。
次に、クラスターマネージャーを使用しているか、DRBDリソースを手動で追跡しているかによって、リソースを起動する方法が2つあります。クラスターマネージャーを使用している場合は、そのドキュメントに従ってください。
-
手動操作
node-2# systemctl start drbd@<resource>.target
-
Pacemaker
# crm node online node-2
これによってDRBDは他のノードに接続し、再同期プロセスが開始します。
両ノードのリソースが再度「UpToDate」となった時点で、アプリケーションをすでにアップグレードされたノード(node-2 ここでは)に移動し、その後、引き続きバージョン8.4を実行しているクラスターノードで同じ手順を実行してください。
ping の結果を使用しています
bitmap_parse 関数を使用してCPUマスクパラメータの機能を提供しています。 bitmap_parse 関数のLinuxカーネルドキュメントを参照してください:https://docs.kernel.org/core-api/kernel-api.html?highlight=bitmap_parse#c.bitmap_parse[こちら
ping-timeout 、またはカーネルが接続を中断させることがあります。これは、ネットワークリンクがダウンした結果かもしれません。