Matt Kereczman, Solutions Architect at LINBIT
Björn Kraus, Chief Technical Officer at PHOENIX MEDIA
Björn is CTO at an Adobe Commerce Solution Partner in Germany, where he leads the engineering team with a strong focus on Kubernetes and cloud-native infrastructure. A Certified Kubernetes Administrator (CKA), he has established a DevOps culture and introduced GitOps workflows to streamline operations. As a passionate LINSTOR user, he integrated it deeply into the company’s Kubernetes clusters and worked closely with LINBIT support to refine features like the Operator v1 to v2 migration and CSI snapshot support with Velero.
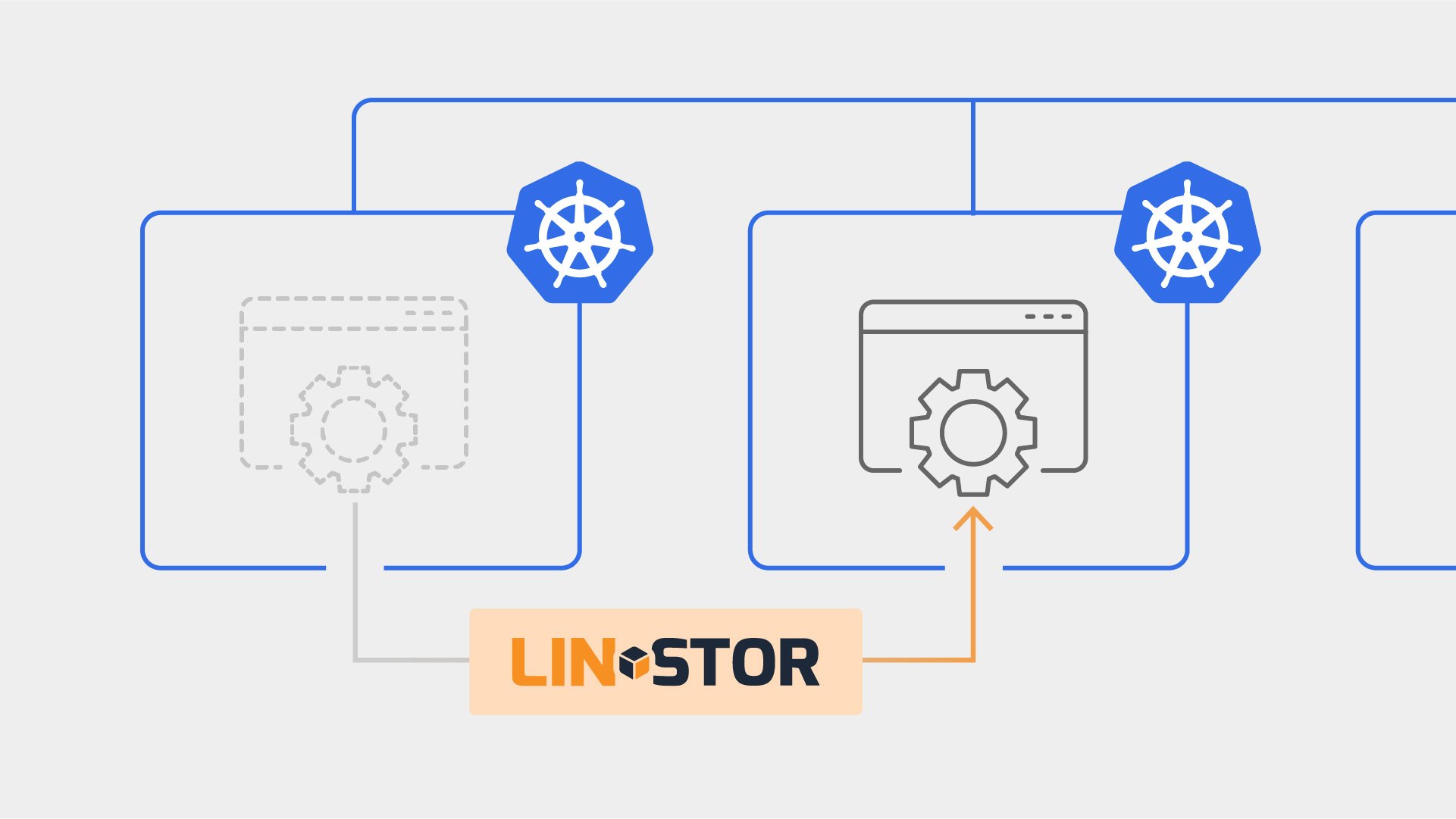
When running stateful Kubernetes workloads, migrating applications and their persistent volumes between Kubernetes clusters isn’t trivial. Common methods used to overcome this challenge typically include some form of volume backup and restoration, a process which usually involves downtime while data is being restored in the target cluster. However, if you’re using LINSTOR® for persistent storage in Kubernetes, it’s possible to move workloads, including their persistent volumes, from one cluster to another with minimal downtime and without data loss.
PHOENIX MEDIA, a LINBIT® customer, accomplished this by connecting a second Kubernetes cluster to the LINSTOR controller running within the first cluster, allowing them to share the same storage back end. This clever technique enabled a clean migration of persistent volumes and workloads, using mostly standard Kubernetes tools and LINSTOR’s internal custom resource definitions (CRDs).
This blog outlines that migration process step-by-step, complete with YAML examples and the shell scripts that the PHOENIX MEDIA team used in their migration process. The entire procedure involves:
- Connecting two clusters to the same LINSTOR controller
- Exporting and importing PVCs and PVs between clusters
- Handling workload failover gracefully
- Optionally reassigning control to the new cluster
Environment details
The procedure begins with two separate Kubernetes clusters:
- Cluster A is the original cluster with the Piraeus Operator installed and using LINSTOR to manage storage.
- Cluster B is the new cluster that will take over workload responsibility.
In Cluster A:
- Piraeus was deployed.
- A PVC was created and used by a deployment.
- LINSTOR satellites were running as expected.
In Cluster B:
- Kubernetes was deployed.
📝 NOTE: The Piraeus Operator, part of the upstream open source Piraeus Datastore CNCF project, is functionally equivalent to the LINSTOR Operator. Both are open source tools for deploying and managing LINSTOR clusters in Kubernetes, and use the same CRDs and architecture. The key difference is that the Piraeus Operator uses community-maintained container images available to everyone, while the LINSTOR Operator deploys LINBIT enterprise images, which require a subscription to access and are officially supported by LINBIT.
Expose the LINSTOR controller in Cluster A
To allow Cluster B to communicate with the existing LINSTOR controller, expose it as a NodePort service in Cluster A by using the following configuration:
apiVersion: v1
kind: Service
metadata:
name: linstor-controller-external
namespace: linstor
spec:
type: NodePort
ports:
- name: linstor-controller
port: 3370
targetPort: 3370
nodePort: 30370
protocol: TCP
selector:
app.kubernetes.io/component: linstor-controller
app.kubernetes.io/instance: linstorcluster
app.kubernetes.io/name: piraeus-datastore
Make sure firewall rules and network access between the clusters allow this port to be reached from Cluster B.
Connect Cluster B to the LINSTOR controller in Cluster A
In Cluster B, install Piraeus, referencing the controller in Cluster A. The LinstorCluster resource should include the externalController field:
apiVersion: piraeus.linbit.com/v1
kind: LinstorCluster
metadata:
name: linstorcluster
spec:
externalController:
url: http://<cluster-a-node-ip>:30370
Ensure both clusters’ satellites use host networking, so that DRBD® can properly connect nodes across clusters.
Once the Piraeus Operator and the LINSTOR satellite pods have been deployed to Cluster B, they should be visible in the LINSTOR controller. To verify this, enter linstor node list in the LINSTOR controller in Cluster A and check the “online” status of the new nodes from Cluster B.
You can now create resources on the Cluster B nodes by using linstor resource create <cluster-b-node-name> <resource name>. This will create a DRBD replica on a node which is not part of the original cluster, Cluster A. The LINSTOR and DRBD software components are functioning properly at this point. Next, you need to ensure that the Kubernetes resources get migrated and are available in the new cluster.
Export and clean up PVCs and PVs
To make the storage resources available in Cluster B, you need to migrate the PVCs and PVs resources. This will allow access to the DRBD resources originally created in Cluster A.
On Cluster A, run this script to export and sanitize all in-use PVCs and PVs. It removes unnecessary metadata to prepare the objects for reapplication in Cluster B.
#!/bin/bash
BACKUP_DIR="./k8s-backup"
mkdir -p "$BACKUP_DIR/pvc"
mkdir -p "$BACKUP_DIR/pv"
echo "Export and cleanup PVCs..."
# All PVCs that link to PVs
kubectl get pv -o json | jq -r '
.items[] | select(.spec.claimRef != null) |
[.spec.claimRef.namespace, .spec.claimRef.name] | @tsv
' | sort | uniq | while IFS=$'\t' read -r namespace pvc_name; do
output_file="$BACKUP_DIR/pvc/${namespace}-${pvc_name}.yaml"
kubectl get pvc "$pvc_name" -n "$namespace" -o json | jq '
{
apiVersion,
kind,
metadata: {
name: .metadata.name,
namespace: .metadata.namespace
},
spec
}
' > "$output_file"
echo " -> PVC $namespace/$pvc_name exported to $output_file"
done
echo "Export and cleanup PVs..."
kubectl get pv -o json | jq -c '.items[]' | while IFS= read -r pv_json; do
name=$(echo "$pv_json" | jq -r '.metadata.name')
output_file="$BACKUP_DIR/pv/${name}.yaml"
echo "$pv_json" | jq '
{
apiVersion,
kind,
metadata: {
name: .metadata.name
},
spec: (
.spec
| if has("claimRef") then
.claimRef |= {
name: .name,
namespace: .namespace
}
else .
end
)
}
' > "$output_file"
echo " -> PV $name exported to $output_file"
done
Inspect the contents of the BACKUP_DIR to verify they are as expected.
Import PVCs and PVs in Cluster B
Apply the manifests that were backed up and sanitized in the previous step to the new cluster:
kubectl apply -f ./k8s-backup/pvc/
kubectl apply -f ./k8s-backup/pv/
The PVCs will bind to the imported PVs immediately.
💡 TIP: Be sure to use the correct kubeconfig when talking to Cluster A and B. For example, you can use an
export KUBECONFIG=config-cluster-acommand to set the kubeconfig before using kubectl.
Migrate workloads
Copy over the consuming deployments and statefulsets to Cluster B, and apply them. The pods will initially fail to start if the volume is still in-use on Cluster A. This is expected and a sign that DRBD is protecting you from split-brains.
Scale the deployments and statefulsets down to zero replicas on Cluster A:
kubectl scale deployment <your-app> --replicas=0
kubectl scale statefulsets <your-app> --replicas=0
Then, as Cluster A’s pods release or unmount each DRBD volume, pods will begin to start in Cluster B.
At this point, each pod will be accessing its data by using DRBD client (also known as diskless) mode. Use the following LINSTOR command to create a diskful replica on the node where the pods are running:
linstor resource toggle-disk <node> <resource>
This will synchronize the remote block device locally to a newly provisioned volume. Pods using the volume can continue to use the volume while it’s being synchronized. Once fully synchronized, the pod will seamlessly begin using the local replica of the volume without requiring a pod restart.
Migrate the LINSTOR controller
The last thing you need to do is to move the active LINSTOR controller to Cluster B. The LINSTOR “database” is stored within Custom Resource Definitions (CRDs) in Cluster A. So first, shutdown the LINSTOR controller in Cluster A to create a consistent backup:
kubectl scale deployment -n linstor linstor-controller --replicas=0
Then, export all LINSTOR CRDs from Cluster A:
mkdir -p linstor-crds; cd ./linstor-crds
kubectl api-resources --api-group=internal.linstor.linbit.com -oname | xargs --no-run-if-empty kubectl get crds -oyaml > crds.yaml
for CRD in $(kubectl api-resources --api-group=internal.linstor.linbit.com -oname); do
kubectl get "${CRD}" -oyaml > "${CRD}.yaml"
done
Next, apply the exported CRDs into Cluster B:
kubectl apply -f ./linstor-crds/
Finally, remove the externalController field in Cluster B:
kubectl edit linstorclusters.piraeus.io
This will cause the LINSTOR controller to start in Cluster B, loading the imported CRDs as its state, completing the migration process.
Optionally, you could configure Cluster A to use Cluster B as its external LINSTOR controller now if necessary. That would essentially be the same process outlined here, but in reverse. I will leave that as an exercise for the reader.
Summary
With a bit of YAML wrangling and the abstractions LINSTOR provides, migrating workloads between Kubernetes clusters becomes a real and repeatable process. This method keeps your data intact, minimizes downtime to only a few minutes, allows gradual or full transitions between clusters, and doesn’t require custom operators or complex tooling.
The process and patterns used in this article are very close to what is needed to facilitate federated LINSTOR clusters in Kubernetes capable of “cluster failovers”.
LINBIT is extremely thankful, as an open source company, to have customers and users such as PHOENIX MEDIA that trust LINBIT software and support with their data. The LINBIT team is especially appreciative of those that collaborate with us when pioneering processes such as this, which in-turn feeds back into the community for others to use, learn from, or even expand upon.


