
Authors: Michael Troutman & Rene Peinthor
—
This post will guide you through integrating LINBIT SDS (LINSTOR® and DRBD®) with OpenNebula, to provide fast, scalable, and highly available storage for your virtual machine (VM) images. After completing the integration, you will be able to easily live-migrate VMs between OpenNebula nodes, and have data redundancy, so that if the storage node hosting your VM images fails, another node, with a perfect replica of the storage backing your images will be ready to take over the hosting role.
Prerequisites
This post assumes that you already have OpenNebula installed and running in your cluster.
The instructions in this article were written by using version 6.8.01 (latest at time of writing) of the miniONE OpenNebula front end and the OpenNebula KVM host package available in the OpenNebula Community Edition repository. Instructions were tested on RHEL 9 and Ubuntu 22.04 LTS.
📝 IMPORTANT: If you are using version 6.6.0 or earlier of the Community Edition of the OpenNebula miniONE software, you might need to apply the following patch to the
/var/lib/one/remotes/datastore/libfs.shscript on the OpenNebula front-end node,node0, if you get an error when trying to create an image on the LINSTOR image datastore:function image_vsize { - echo "$($QEMU_IMG info "${1}" 2>/dev/null | sed -n 's/.*(\([0-9]*\) bytes).*/\1/p')" + echo "$($QEMU_IMG info --output json "${1}" | jq '."virtual-size"')" }
This post uses an example cluster with the following attributes:
| Node Name | IP | OpenNebula Role | LINSTOR Role |
node0 | 192.168.221.20 | OpenNebula front end | LINSTOR controller |
node1 | 192.168.221.21 | Virtualization host | LINSTOR satellite |
node2 | 192.168.221.22 | Virtualization host | LINSTOR satellite |
node3 | 192.168.221.23 | Virtualization host | LINSTOR satellite |
📝 NOTE: This example setup uses a single network interface controller (NIC) for each node in the cluster, for simplicity. In a production environment, for performance reasons, you can provision a separate NIC that is solely dedicated to DRBD replication traffic. Refer to instructions in the LINSTOR User’s Guide for more information.
Firewall
The LINSTOR satellite service requires TCP ports 3366 and 3367. The LINSTOR controller service requires TCP port 3370. Verify that you have these ports allowed on your firewall on the appropriate nodes.
Also, DRBD replication traffic requires TCP port 7000 and above for each DRBD resource to replicate data between peer nodes, that is, port 7000 for the first DRBD resource, 7001 for the next, and so on. For each VM image that you add to a LINSTOR-backed OpenNebula image datastore, and each VM image that you instantiate, LINSTOR will create a LINSTOR resource that will correspond to a replicating DRBD resource. So, you will need to allow TCP traffic starting at port 7000, and incrementally for each VM image and VM instance in the LINSTOR-backed datastore.
SELinux
For deployment in an RPM-based Linux environment, disable SELinux according the procedure specific to your Linux distribution and as recommended by the OpenNebula documentation. However, if deploying into a production cluster, this will impact the security of your environment and you will need to integrate your deployment with SELinux rather than disabling SELinux.
Installing LINSTOR and Preparing It For Integration With OpenNebula
The following instructions will detail how you can install LINSTOR into your cluster and then show you how to add a LINSTOR image and system datastore to OpenNebula.
Preparing Back-End Storage For LINSTOR
On each of the virtualization host nodes, create two LVM thin-provisioned storage pools, named linstorpool/thin_image and linstorpool/thin_system. In the example cluster in this article, each of the virtualization hosts has a second hard disk drive, /dev/vdb, that will back the LVM physical volumes.
# vgcreate linstorpool /dev/vdb
# lvcreate -l 30%FREE -T linstorpool/thin_system
# lvcreate -l 70%FREE -T linstorpool/thin_image
📝 NOTE: In a production environment, you might want to have different backing devices for your system and image logical volumes, for performance reasons. Also, you can adjust the storage allocation to suit your needs. A 30%/70% split here is used only for example purposes.
Installing LINSTOR Packages
If you are a LINBIT® customer, you can install LINSTOR, and the add-on that allows it to integrate with OpenNebula, by using a package manager to install a couple of packages from LINBIT customer package repositories, on your OpenNebula front-end node, node0, in this example.
📝 IMPORTANT: The necessary LINBIT packages are available in the
drbd-9LINBIT package repository. If you have not already enabled this repository on your LINSTOR nodes, you can enable it by running the LINBIT manage node helper script on each node.
Installing the LINSTOR Controller and LINSTOR OpenNebula Driver Packages
On a DEB-based system, enter:
# apt -y install linbit-sds-controller linstor-opennebula
On an RPM-based system, enter:
# dnf -y install linbit-sds-controller linstor-opennebula
Installing the LINSTOR Satellite Packages
On all other virtualization host nodes, you do not need the linbit-sds-controller or linstor-opennebula packages. These nodes will function as the storage nodes in your cluster and will host VM images. These nodes are called satellites in LINSTOR-speak. Install the LINBIT SDS satellite package and DRBD kernel module packages on these nodes.
On DEB-based systems, enter:
# apt -y install linbit-sds-satellite drbd-dkms
📝 NOTE: On DEB-based systems, if you do not want to install the built-from-source DRBD kernel module, you can install a kernel module that is specific to the kernel version that you are running. You can run the LINBIT manage node helper script with the
--hintsflag to get the package name for this.
On RPM-based systems, enter:
# dnf -y install linbit-sds-satellite kmod-drbd
Starting and Enabling LINSTOR Services
After installing packages, enable and start the LINSTOR controller service, on the OpenNebula front-end node, node0:
# systemctl enable --now linstor-controller
On each virtualization host node, enable and start the LINSTOR satellite service:
# systemctl enable --now linstor-satellite
Now all LINSTOR-related services should be running in your cluster. As a basic verification that at least the LINSTOR client can reach your LINSTOR controller, enter the following command on your OpenNebula front-end node, to list the nodes in your LINSTOR cluster:
# linstor node list
The client should be able to reach the LINSTOR controller service and output from the command will show that there are no nodes in the LINSTOR cluster:
╭─────────────────────────────────────╮
┊ Node ┊ NodeType ┊ Addresses ┊ State ┊
╞═════════════════════════════════════╡
╰─────────────────────────────────────╯
Adding LINSTOR Nodes
All nodes that will work as virtualization host nodes need to be added to LINSTOR, so that storage can be distributed and activated on all nodes. On your LINSTOR controller node (OpenNebula front-end node), enter:
# for i in {1..3}; do linstor node create node$i; done
📝 IMPORTANT: For the above command to succeed, the LINSTOR controller must be able to resolve the IP address of each of the LINSTOR satellites by the hostname of each satellite. You can
pingeach of the satellite nodes by hostname to verify. If yourpingcommand fails, verify that the controller can look up the satellites’ IP addresses via DNS or else add the satellites’ IP addresses and hostnames to the controller’s/etc/hostsfile. Alternatively, you can specify the node’s IP address after its hostname in thelinstor node createcommand. In the command above, using the IP addresses in this article’s example cluster, that would be:192.168.221.2$i
Creating LINSTOR Storage Pools
After adding the satellite nodes to your LINSTOR cluster, create the LINSTOR storage pools on the satellite nodes that will provide the consumable storage for the OpenNebula system (running VMs) and image (VM repository) datastores.
📝 NOTE: OpenNebula has a third type of datastore,
files and kernels, that is not supported by LINSTOR-provisioned storage. Refer to OpenNebula Datastores documentation for more information.
On the LINSTOR controller node, enter the following commands to create LINSTOR storage pools, named on_system and on_image on each satellite node:
# for i in {1..3}; do linstor storage-pool create lvmthin node$i \
on_system linstorpool/thin_system; done
# for i in {1..3}; do linstor storage-pool create lvmthin node$i \
on_image linstorpool/thin_image; done
Verifying Storage Pools
Enter the following command to list your LINSTOR storage pools to verify that you created them correctly:
# linstor storage-pool list
Output should show the on_system and on_image storage pools on each satellite node.
╭──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
┊ StoragePool ┊ Node ┊ Driver ┊ PoolName ┊ FreeCapacity ┊ TotalCapacity ┊ CanSnapshots ┊ State ┊ SharedName ┊
╞══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╡
┊ DfltDisklessStorPool ┊ node1 ┊ DISKLESS ┊ ┊ ┊ ┊ False ┊ Ok ┊ node1;DfltDisklessStorPool ┊
┊ DfltDisklessStorPool ┊ node2 ┊ DISKLESS ┊ ┊ ┊ ┊ False ┊ Ok ┊ node2;DfltDisklessStorPool ┊
┊ DfltDisklessStorPool ┊ node3 ┊ DISKLESS ┊ ┊ ┊ ┊ False ┊ Ok ┊ node3;DfltDisklessStorPool ┊
┊ on_image ┊ node1 ┊ LVM_THIN ┊ linstorpool/thin_image ┊ 14.67 GiB ┊ 14.67 GiB ┊ True ┊ Ok ┊ node1;on_image ┊
┊ on_image ┊ node2 ┊ LVM_THIN ┊ linstorpool/thin_image ┊ 14.67 GiB ┊ 14.67 GiB ┊ True ┊ Ok ┊ node2;on_image ┊
┊ on_image ┊ node3 ┊ LVM_THIN ┊ linstorpool/thin_image ┊ 14.67 GiB ┊ 14.67 GiB ┊ True ┊ Ok ┊ node3;on_image ┊
┊ on_system ┊ node1 ┊ LVM_THIN ┊ linstorpool/thin_system ┊ 8.97 GiB ┊ 8.97 GiB ┊ True ┊ Ok ┊ node1;on_system ┊
┊ on_system ┊ node2 ┊ LVM_THIN ┊ linstorpool/thin_system ┊ 8.97 GiB ┊ 8.97 GiB ┊ True ┊ Ok ┊ node2;on_system ┊
┊ on_system ┊ node3 ┊ LVM_THIN ┊ linstorpool/thin_system ┊ 8.97 GiB ┊ 8.97 GiB ┊ True ┊ Ok ┊ node3;on_system ┊
╰──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
Creating LINSTOR Resource Groups
The LINSTOR OpenNebula driver uses LINSTOR resource groups to provide the basis for the storage that your LINSTOR-backed OpenNebula system and image datastores will use. Create a resource group for each datastore that references the LINSTOR storage pool that you want to associate with each datastore.
On the LINSTOR controller node, node0, enter:
# linstor resource-group create on_image_rg \
--place-count 2 --storage-pool on_image && \
linstor volume-group create on_image_rg
# linstor resource-group create on_system_rg \
--place-count 2 --storage-pool on_system && \
linstor volume-group create on_system_rg
📝 NOTE: Setting
--place-count=2ensures that there will be two replicas of your datastore data on two LINSTOR satellite nodes, as you will see later, after adding a VM image to a LINSTOR-backed datastore.
You have now configured LINSTOR and it is ready to be used by OpenNebula.
Integrating LINSTOR With OpenNebula
OpenNebula uses different types of datastores: system, image and files.
As mentioned earlier, LINSTOR supports the system and image datastore types:
- The system datastore is used to store a small context image that stores all information needed for running a VM on a host.
- The image datastore is the repository for your VM images.
You do not need to configure OpenNebula with a LINSTOR system datastore. By default, OpenNebula will work with its own system datastore. However, by using LINSTOR as backing storage for the OpenNebula system and image system datastores, you get the benefit of high availability for images stored in the LINSTOR-backed datastores.
Setting Up the LINSTOR OpenNebula Datastore Driver
LINSTOR uses an add-on driver to integrate with OpenNebula. To install the driver, add linstor to the list of drivers in the OpenNebula transfer manager and datastore driver configuration sections in the /etc/one/oned.conf configuration file, on your OpenNebula front-end node:
TM_MAD = [
EXECUTABLE = "one_tm",
ARGUMENTS = "-t 15 -d dummy,lvm,shared,fs_lvm,fs_lvm_ssh,qcow2,ssh,ceph,dev,vcenter,iscsi_libvirt,linstor"
]
[...]
DATASTORE_MAD = [
EXECUTABLE = "one_datastore",
ARGUMENTS = "-t 15 -d dummy,fs,lvm,ceph,dev,iscsi_libvirt,vcenter,restic,rsync,linstor -s shared,ssh,ceph,fs_lvm,fs_lvm_ssh,qcow2,vcenter,linstor"
]
📝 IMPORTANT: Specify
linstortwice in theARGUMENTSline of theDATASTORE_MADstanza: once for the image and once for the system datastore.
Next, add new TM_MAD_CONF and DS_MAD_CONF stanzas for the linstor driver in the appropriate sections of the /etc/one/oned.conf configuration file:
TM_MAD_CONF = [
NAME = "linstor", LN_TARGET = "NONE", CLONE_TARGET = "SELF", SHARED = "yes", ALLOW_ORPHANS="yes",
TM_MAD_SYSTEM = "ssh,shared", LN_TARGET_SSH = "NONE", CLONE_TARGET_SSH = "SELF", DISK_TYPE_SSH = "BLOCK",
LN_TARGET_SHARED = "NONE", CLONE_TARGET_SHARED = "SELF", DISK_TYPE_SHARED = "BLOCK"
]
DS_MAD_CONF = [
NAME = "linstor", REQUIRED_ATTRS = "BRIDGE_LIST", PERSISTENT_ONLY = "NO", MARKETPLACE_ACTIONS = "export"
]
Finally, restart the OpenNebula service:
# systemctl restart opennebula.service
Adding the LINSTOR Datastores
After adding the LINSTOR drivers to the OpenNebula configuration, you can next add the image and system datastores to OpenNebula.
For each datastore, system and image, you will create a configuration file and add it with the OpenNebula datastore management tool, onedatastore. To create the LINSTOR-backed system datastore, enter:
# su oneadmin
$ cat << EOF > /tmp/system_ds.conf
NAME = linstor_system_datastore
TM_MAD = linstor
TYPE = SYSTEM_DS
DISK_TYPE = BLOCK
LINSTOR_RESOURCE_GROUP = "on_system_rg"
BRIDGE_LIST = "node1 node2 node3" #node names
EOF
$ onedatastore create /tmp/system_ds.conf
Next, create a similar configuration file for the image datastore and use it to create a LINSTOR-backed image datastore. Enter the following commands (still logged in as the oneadmin user):
$ cat << EOF > /tmp/image_ds.conf
NAME = linstor_image_datastore
DS_MAD = linstor
TM_MAD = linstor
TYPE = IMAGE_DS
DISK_TYPE = BLOCK
LINSTOR_RESOURCE_GROUP = "on_image_rg"
COMPATIBLE_SYS_DS = "0,100"
BRIDGE_LIST = "node1 node2 node3"
EOF
$ onedatastore create /tmp/image_ds.conf
📝 IMPORTANT: When the LINSTOR-backed system datastore is created, an
IDis assigned to it by OpenNebula (100is assigned in this particular blog post). When defining the LINSTOR-backed image datastore, the previously created system datastoreIDis added to theCOMPATIBLE_SYS_DSfield. This ensures the datastores can be used together in OpenNebula. Adjust these values accordingly when configuring your environment.
Verifying the LINSTOR Datastores
You should now have two new datastores that you can view by using the OpenNebula web front end, Sunstone: http://node0/#datastores-tab.
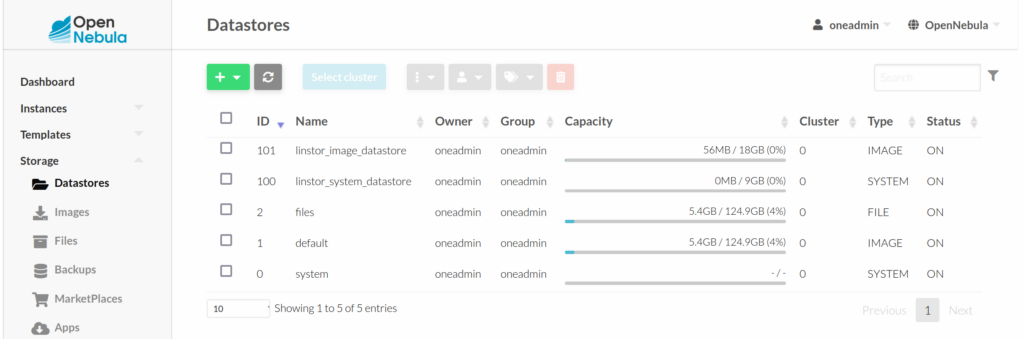
Alternatively, on your OpenNebula front-end node, you can use the onedatastore list command to list your datastores:
ID NAME SIZE AVA CLUSTERS IMAGES TYPE DS TM STAT
101 linstor_image_datastore 14.7G 100 0 1 img linstor linstor on
100 linstor_system_datastore 9G 100 0 0 sys - linstor on
2 files 124.9G 96% 0 0 fil fs ssh on
1 default 124.9G 96% 0 2 img fs ssh on
0 system - - 0 0 sys - ssh on
Usage and Notes
The newly added LINSTOR datastores can be used in the usual OpenNebula datastore selections and should support all OpenNebula features.
The LINSTOR OpenNebula driver also has some configuration options, such as LINSTOR_CONTROLLERS, that are described in the LINSTOR User’s Guide beyond what was shown in this article.
The Benefits of Using LINSTOR With OpenNebula
By using LINBIT SDS (LINSTOR and DRBD) to back your OpenNebula datastores, you can provide high availability to your OpenNebula VM and system images.
For example, create a VM image on the LINSTOR-backed OpenNebula image datastore:
# su oneadmin
$ wget http://mirror.slitaz.org/iso/rolling/slitaz-rolling.iso \
-O /var/tmp/slitaz-rolling.iso
$ oneimage create --datastore linstor_image_datastore \
--name Slitaz-on-LINSTOR \
--path /var/tmp/slitaz-rolling.iso \
--disk_type CDROM \
--description "Slitaz lightweight Linux distribution"
Highly Available Virtual Machine Images
You can then enter a linstor resource list command to show that after creating an OpenNebula VM image that is based on the downloaded ISO file, LINSTOR automatically provisions a storage resource that is placed on two nodes and on a third node, in diskless mode. The diskless resource serves as a tiebreaker for DRBD quorum purposes, to avoid split-brain issues.
╭─────────────────────────────────────────────────────────────────────────────────────────────────╮
┊ ResourceName ┊ Node ┊ Port ┊ Usage ┊ Conns ┊ State ┊ CreatedOn ┊
╞═════════════════════════════════════════════════════════════════════════════════════════════════╡
┊ OpenNebula-Image-8 ┊ node1 ┊ 7000 ┊ Unused ┊ Ok ┊ UpToDate ┊ 2023-08-11 12:30:04 ┊
┊ OpenNebula-Image-8 ┊ node2 ┊ 7000 ┊ Unused ┊ Ok ┊ UpToDate ┊ 2023-08-11 12:30:04 ┊
┊ OpenNebula-Image-8 ┊ node3 ┊ 7000 ┊ Unused ┊ Ok ┊ TieBreaker ┊ 2023-08-11 12:30:03 ┊
╰─────────────────────────────────────────────────────────────────────────────────────────────────╯
Diskless Resource Distribution
It is important to know that the LINSTOR-provisioned storage can potentially be accessed by all nodes in the cluster by using a DRBD feature called “diskless clients”. Assume that node1 and node2 had the most free space and were selected, and that a VM instance was created on node2
By using the low level tool drbdadm status, on one of the LINSTOR satellite nodes, you can see that the DRBD resource is created on two nodes (node1 and node2) and the DRBD resource is in a primary role on node2.
Now if you want to migrate the VM from node2 to node3. You can do this by either a few clicks in the Sunstone GUI, or by entering a onevm migrate command in the front-end CLI. Interesting things happen behind the scenes here. The LINSTOR OpenNebula storage add-on realizes that it has access to the data on node1 and node2 (your two replicas) but also needs access on node3 to run the VM. The add-on therefore creates a diskless assignment on node3. When you enter a drbdadm status command on node3, you should now see that now three nodes are involved in the overall picture:
node1with storage in a secondary rolenode2with storage in a secondary rolenode3as a diskless client in a primary role
Diskless clients are created (and deleted) on-demand without needing any user interaction, besides moving around VMs in either the OpenNebula GUI or CLI. This means that if you now move the VM back to node2, the diskless assignment on node3 gets deleted as it is no longer needed.
Performance Benefits
For deploying this solution, it is probably even more interesting that all of this, including VM migration, happens within seconds without having to move the actual replicated storage contents.
Conclusion
The instructions and examples in this article have been provided to get you started using LINBIT SDS with OpenNebula. Besides some of the things already mentioned, such as provisioning a separate dedicated network for DRBD replication traffic, there are other steps that you can take to make this solution more production-ready:
If your deployment might require other architecture considerations, you can contact the experts at LINBIT.
Here is a video demonstration of running LINBIT SDS with OpenNebula.
1: When updating this blog post earlier in 2023, miniONE version 6.6.0 was the latest version. An OpenNebula developer kindly answered a question posted in the issues section of the miniONE GitHub project about an error encountered when first trying to create this setup. This resulted in the libfs.sh patch shown above that solved the issue. If you have issues setting up the Community Edition of OpenNebula, the OpenNebula Community Forum could be another place that you could seek help. The official OpenNebula documentation site is also a helpful resource.


