
This article describes the reasoning behind and the benefits of a high-availability (HA) solution for providing services and applications. This article is intended as a general overview and introduction to HA, with a nontechnical reader in mind. Because you are reading this article on the LINBIT® blog, you will also learn how LINBIT software can help you create highly available services and applications.
Background on high availability
According to Red Hat:
High availability is the ability of an IT system to be accessible and reliable nearly 100% of the time, eliminating or minimizing downtime. It combines two concepts to determine if an IT system is meeting its operational performance level: that a given service or server is accessible–or available–almost 100% of the time without downtime, and that the service or server performs to reasonable expectations for an established time period.
So, HA is a term used to describe a system that meets an agreed upon operational performance level. A company, organization, or service provider can determine what that performance level is. However, an HA system usually provides services or applications that users depend on and need to be up and running continuously. These would be critical services or applications that if they were not running and accessible, would negatively impact a service provider’s business. Factors such as the cost of downtime, and the patience of users or customers during downtime, will likely play an important role in what an organization determines is an acceptable performance level.
Data shares, financial applications, e-commerce websites, shared development environments, virtual private server (VPS) providers, and any “as-a-service” offerings, are just some of the use cases where you will find HA solutions deployed. HA used to be implemented exclusively by large corporations and organizations. However, because of how dependent people are on digital solutions and transactions, now even small organizations rely on HA solutions.
Further defining high availability
As the name suggests, HA is a term that describes the ability of a system’s components to continue functioning in a specified time frame. HA can be measured relative to fully (100%) operational. A popular standard of availability for a product or service is “five 9s” (99.999%) availability. This translates to about 5 minutes and 16 seconds of downtime per year.
To achieve such a minimum level of downtime, an HA system must be well designed and its segments well tested for availability, before an organization deploys it into production.
Significant parts of an HA system include backup and failover processing, data storage, and network access. All the individual components that work to provide these parts of the system must always be “available”.
Avoiding single points of failure
The practical result of this is that the HA solution duplicates components of the system to avoid single points of failure. If one of the components fails, a failover process is activated, and transfers the handling to the redundant component. This method returns the system to a “normal” functioning state in a matter of microseconds. This also allows the system to be up and running while a systems administrator resolves the issue, for example, replacing a failed component in the background. It is important to mention that “component” here can refer to something physical such as a server or network card within a server, or something nonphysical such as user data or a software application.
Creating a highly available system
Creating a highly available system means setting up a system that can remain operational continuously over a long period of time. HA allows services with critical importance to be “always” online and undisturbed, regardless of location or external situation. Even if some of the system components fail, the system as a whole will continue to provide services and applications. Someone who uses the applications or services should not notice that there has been failover. Setting up such a system involves ensuring redundancies, and when data is involved, replication.
Replicating data for redundancy and failover
DRBD® is the open source software that LINBIT has developed for over 20 years. It is trusted and used globally by organizations of all sizes to replicate data between nodes in a cluster. This is one piece of the HA puzzle.
Similar to how hard disk drives in a RAID configuration mirror data so that one drive might fail without causing loss of data within the RAID, DRBD mirrors data over a network, either via TCP or RDMA, to other nodes. This helps systems administrators create HA clusters of redundant systems to keep critical data, applications, and services up and running.
Managing increased complexity
HA solutions create redundancy within a cluster of machines to eliminate any single point of failure. This includes multiplying network connections with redundant cables, network interface cards, switches, and switch ports. And not just the network, all components need to be redundant to achieve HA, such as storage, compute, and other aspects of the system.
However, increasing the components of a system does not automatically turn it into a highly available system. On the contrary, the greater the system’s complexity, the greater its risk of failure. This is where a storage management utility such as LINSTOR®, and a cluster resource manager (CRM) can help. These tools help systems administrators decrease the complexity of managing large numbers of HA storage resources (by using LINSTOR) or HA services (by using a CRM). You can use the open source and LINBIT-developed DRBD Reactor software with its promoter plugin as a simpler alternative to other CRMs such as Pacemaker.
Increasing availability across geographical distances
Sometimes, HA within a single site is not enough. The HA solution might even require geographically distributed clusters to tolerate failures due to events such as natural disasters or power outages that might affect an entire region’s operations. When an HA solution involves multiple sites, it is typically referred to as a disaster recovery (DR) solution. The “stretched cluster” is an example of such a site design. This architecture deployment is typically limited to a campus or metro region, and not spread across large geographical distances. However, learning about the stretched cluster architecture, if you are not familiar with it, will help you understand some of the concepts involved with DR.
Not letting redundant components and resources go to waste
Modern system architectures also use load balancing devices or software within an HA system to distribute workloads (either compute, storage, or network) across multiple instances of whatever component handles the workload. This helps to optimize resource usage, maximize performance, minimize response times, and avoid overburdening any one component. This way, redundant architecture does not just sit there doing nothing, consuming power and other resources, only becoming useful when there is a failover event. Organizations can often put redundant systems to use and can even help improve the performance or user access of your applications and services. The earlier mentioned stretched cluster architecture is an example of this.
The main benefits of HA
The next sections summarize some of the benefits of high availability.
Availability and the five nines uptime
As mentioned earlier, an industry standard benchmark for measuring uptime is the five nines, that is, 99.999% uptime.
This metric can be applied to:
- The entire system
- The system components
- The software and processes running within the system
The more 9s an HA system has, the higher its uptime. The aim of an HA system is to provide as little downtime as possible and the framework to continue to provide the services that your users require. However, time and costs considerations for implementing and maintaining an HA solution will put practical constraints on the uptime that an organization can offer its users. And of course, this uptime should be defined in a service level agreement (SLA) between the organization and the users. This way, an organization is upfront about the potential limits of the system and customers are not caught off-guard by expecting more uptime than your system can deliver.
Reliability
At a practical level, users experience uptime as the reliability of an organization’s services or applications. This is one of the most significant properties of an HA system. Reliability can go beyond the convenience of an always available service to being essential, mainly when a system’s function offers a critical service. For example, air traffic control. In such scenarios, even a millisecond of delay could be the difference between life and death. Reliability also creates trust and faith in your company and the services that you provide.
Scalability
If the HA system encounters a load spike, for example, a network traffic increase or other increase in demand for resources, the system should be able to scale to meet those needs in the moment. By integrating scalability features into the system, the system would adapt rapidly to any changes affecting how the system processes requests for its services. The HA system should not have to rely on manual intervention, from a systems administrator, for example, to meet increased demand.
While you can spread DRBD resources across multiple nodes, as you increase the number of nodes, you also increase the complexity of maintaining and managing the system. The LINBIT answer to this dilemma is LINSTOR, an open source software-defined storage (SDS) management utility. With LINSTOR, you can define logical storage objects, such as storage pools and resource groups, and then easily create storage resources such as DRBD-replicated devices in your clusters. This can be a way to group similar kinds of back-end storage, for example, faster or slower hard disk drives. This is how some organizations, such as VPS providers, offer tiered storage to their customers.
LINSTOR has an auto-placement feature that lets you specify constraints for resource placement in your cluster, such as number of data replicas, and other constraints that you can set up so that you do not need to manually intervene. LINSTOR can also automatically evict nodes from a cluster if a node loses its network connection to other nodes. LINSTOR has a “diskless” mode feature that you can take advantage of. After fulfilling diskful storage resource placement constraints in your cluster, LINSTOR can assign diskless resources to the remaining nodes. This allows a diskless node to access the resource across the network, as if it was on local storage.
In Kubernetes environments, LINSTOR supports native ReadWriteMany (RWX) volumes, allowing many pods to access the same storage at the same time, without needing an NFS layer outside of Kubernetes.
These LINSTOR features can have cost-saving benefits and can help with scalability.
Handling errors
When there is an error, the system can adjust and compensate while staying up and operating. This form of structure requires forethought and contingency planning. One of the essential characteristics of a high-availability system is anticipating problems and preparing for them, rather than reacting to them after they happen. For a practical example, this could mean configuring a system to seamlessly revert a new version of software to a previous version should there be an unrecoverable error when deploying a new version. This would typically be configured at either the application or the orchestrator level, for example, if you integrating DRBD and LINSTOR with Kubernetes, by using the LINSTOR Operator and CSI driver, Kubernetes can automatically handle rollbacks of failed deployments while LINSTOR ensures the underlying storage remains available.
Comparing high availability with disaster recovery
As introduced earlier, high availability and disaster recovery are terms that are often used together to describe resilient systems but they should not be confused for each other.
Disaster recovery (DR) does exactly what the name implies: It provides a detailed plan that helps a system recover quickly after it has experienced a failure. If you have an HA system, you might wonder why you would also need disaster recovery.
DR usually is focused on getting a system and its services back online after a severe failure, possibly due to outside uncontrollable circumstances, such as a natural disaster. A DR plan could deal with the recovery of an entire region’s operations.
HA is focused, however, on failures that are more likely to happen in the normal day-to-day operations of a system offering services, for example, a failing server or hard disk drive.
Possible HA implementations
One of the methods for achieving HA is by using multiple application servers (or nodes). If you experience a sudden surge in traffic, your server might shut down, and users cannot make requests from it. This leads to more downtime. To avoid such scenarios, applications are deployed on systems that use redundant components, across several servers, as mentioned earlier. If one server fails, the rest can take the extra load, allowing for a high fault tolerance within the system.
Another method for achieving HA is by scaling databases, application stacks, and other services. HA is perhaps the most widely-used method to save and protect the data of your users. As any organization knows or can imagine, losing such vital information can often be a costly experience. Physical equipment can likely be replaced. User data is irreplaceable without having a backup or replication solution in place, before any failures or disasters happen. That said, HA is a complement to and not a replacement for regularly backing up important data. LINSTOR supports taking, shipping, and restoring snapshots of thin-provisioned storage such as LVM logical volumes or ZFS zvols. These features provide a built-in way for taking manual or scheduling automated backups with LINSTOR.
Finally, an organization can achieve HA by also spreading the servers across many geographical locations. Political events, natural disasters, and failures of the electric grid can all lead to a shutdown of your servers, even if there are many but they are clustered in one geographic location. To ensure the safety of the data and complete protection, modern solutions deploy servers worldwide. This further increases their reliability and allows for flexible disaster recovery plans that can bring systems back up more quickly than waiting for local response and mitigation. This variant of HA as mentioned earlier is called disaster recovery.
LINBIT solutions for high availability
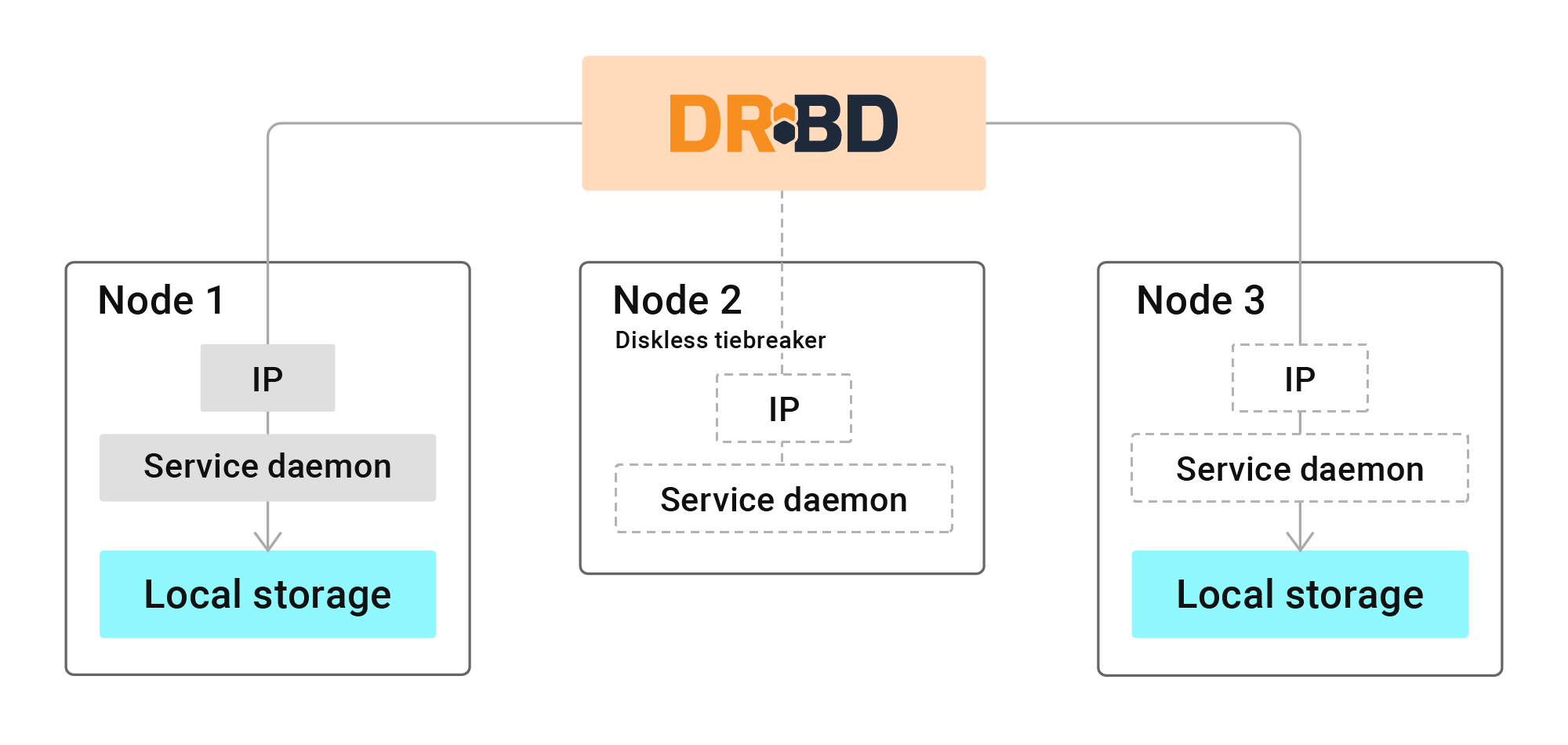
LINBIT – the creator of DRBD® block storage replication software – has over 20 years of experience in storage, high-availability systems, and disaster recovery. LINBIT not only provides and supports HA deployment within notable companies and organizations, but also uses the same HA deployment architectures and tools for LINBIT’s own operations. Many of the companies LINBIT supports choose LINBIT HA, the enterprise solution built on DRBD itself. Other organizations, particularly those with large deployments, choose LINBIT SDS, the combined LINSTOR and DRBD solution. Typical reasons for choosing an open source solution are the lack of vendor lock-ins and the ability for an organization to use commercial off-the shelf (COTS) system components. Clients pay only with respect to what they use. The data that clients replicate with LINBIT HA or LINBIT SDS solutions is accessible at any moment and can be switched to other platforms. You are not locked in to a LINBIT solution. LINBIT HA and LINBIT SDS can handle databases, file servers, storage targets, and application stacks – operating in cloud environments, or on premises, or in a hybrid setup – while maintaining low total cost of ownership (TCO).
If you are interested in increasing your uptime, and providing reliable and scalable services to your customers and users, and without sacrificing performance, contact us to learn more about LINBIT HA or LINBIT SDS, or to request an evaluation or quote.
Changelog
2026-03-30:
- Added more details about LINSTOR in Kubernetes.
- Made minor, non-technical copy edits and language improvements.
2025-04-28:
- Made language improvements.
- Added reference to tiered-storage.
- Added more examples of HA use cases.
2024-06-14:
- Updated blog for language and clarity and to reference LINBIT solutions inline, rather than just at the end of the article.
- Updated an image used in the article.


