
Update: The full technical document described in this blog post has been updated to version 8.2 on 2024-04-06 to include enhancements made to the LINSTOR Operator’s monitoring and alerting capabilities.
Reader Bootstrapping
Amazon Elastic Kubernetes Service (EKS) might be one of the quickest routes an organization can take to run a highly available, fault-tolerant, and scalable Kubernetes cluster. EKS handles many of the difficult tasks in managing a Kubernetes cluster for its users; letting them focus more on their applications than their infrastructure. For example, EKS will balance your Kubernetes control plane and worker nodes across AWS availability zones (AZs) in your region, dynamically create EC2 load balancers enabling access to your applications, and even includes an Elastic Block Store (EBS) storage class for your stateful applications. As great as that all sounds (and is!), there are some gaps that LINBIT SDS® can fill.
Where Are These Gaps
The two main storage offerings available from Amazon for use in EKS are their Elastic Block Store (EBS) and Elastic File System (EFS).
EBS provides block-level storage to EC2 instances – EKS workers in this case – running within the same AZ as the EBS volume. EBS volumes are RWO (read write once) – just like LINBIT SDS and other block storage for Kubernetes – meaning they can only be accessed by one EKS worker instance at a time. This makes EBS a good fit for stateful applications that require performant (low latency and high throughput) block-level storage in AWS. RWO access also means that you’ll have to configure and rely on your application’s built-in replication for fault tolerance and high availability of your application’s stateful data. However, what if your application doesn’t have built-in replication?
EFS provides a filesystem to EC2 instances that can be accessed concurrently and across AZs. In Kubernetes terms, it’s an RWX (read write many) persistent storage option. This acts much like an NFS mounted filesystem. Much like NFS, write performance to EFS suffers from the locking overhead necessary to prevent corruption. EFS is not suitable for use-cases such as OLTP databases, or applications requiring single file access such as Jenkins. EFS is more suited for use-cases such as content repositories, big data, home directories, and media processing.
Therefore, if your application requires highly performant storage and doesn’t have the ability to replicate its state on its own, you’re in the gap between EBS and EFS. If you choose EBS, your application could become unavailable in the event of an AZ service outage in your AWS region. If you choose EFS for one of the use cases it wasn’t designed for, you might experience high write latency. LINBIT SDS fills that gap by providing high performance, synchronously replicated, block storage to Kubernetes clusters. With a little EC2 massaging, LINBIT SDS can fill that gap in Amazon EKS.
LINBIT SDS is open source, and can run on your development notebook just like it can in the cloud. This means your “throw-away development cluster” can have the same storage backend as your production cluster in AWS, which is another gap LINBIT SDS can help fill.
Preparing EC2 for LINBIT SDS
LINBIT SDS for Kubernetes deploys a LINSTOR® cluster into your Kubernetes cluster configured by the LINSTOR operator. LINSTOR will then layer different Linux block technologies such as LVM, VDO, LUKS, and DRBD® on top of one another to enable specific features on a volume. The most important layer LINSTOR manages will almost always be DRBD for its in-kernel block replication. In order for LINSTOR to create DRBD devices in our EC2 worker instances, it either needs to package a kernel module specific to the Amazon Linux 2.0 kernel (the default Linux distribution for EKS), or the EC2 instances need to have the appropriate kernel-devel packages installed so LINSTOR can compile DRBD for Amazon Linux 2.0 on deployment. Therefore, we must create a launch template in EC2 for our EKS cluster to use when bootstrapping new EKS worker nodes. LINSTOR also requires an unused block device attached to each EC2 instance that it can use as a storage pool; this can also be done via the EC2 launch template.
Log in to the AWS Management Console and go to the EC2 Dashboard. In the navigation sidebar, you should see a link to “Launch Templates” nested under the “Instances” drop down; follow that link. Then, click the “Create launch template” button in the Launch Template console. Set only the options pictured below, as the rest will be configured elsewhere (depending on how your organization manages EKS).
Name and Describe the Launch Template
Instance Type for Launch Template
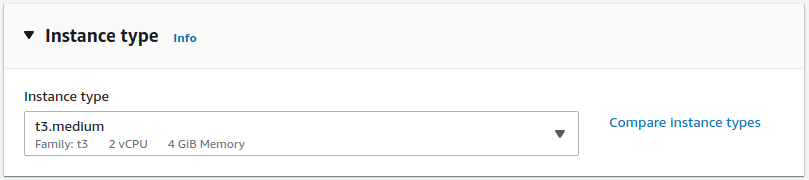
Set the instance type according to your application’s needs. LINSTOR itself is not resource intensive. Memory utilization for a DRBD resource scales with the size of volume and number of replicas. The formula is roughly 32KiB of memory per 1GiB of storage, multiplied by the number of peers (other nodes with replicas).
Storage Settings for Launch Template
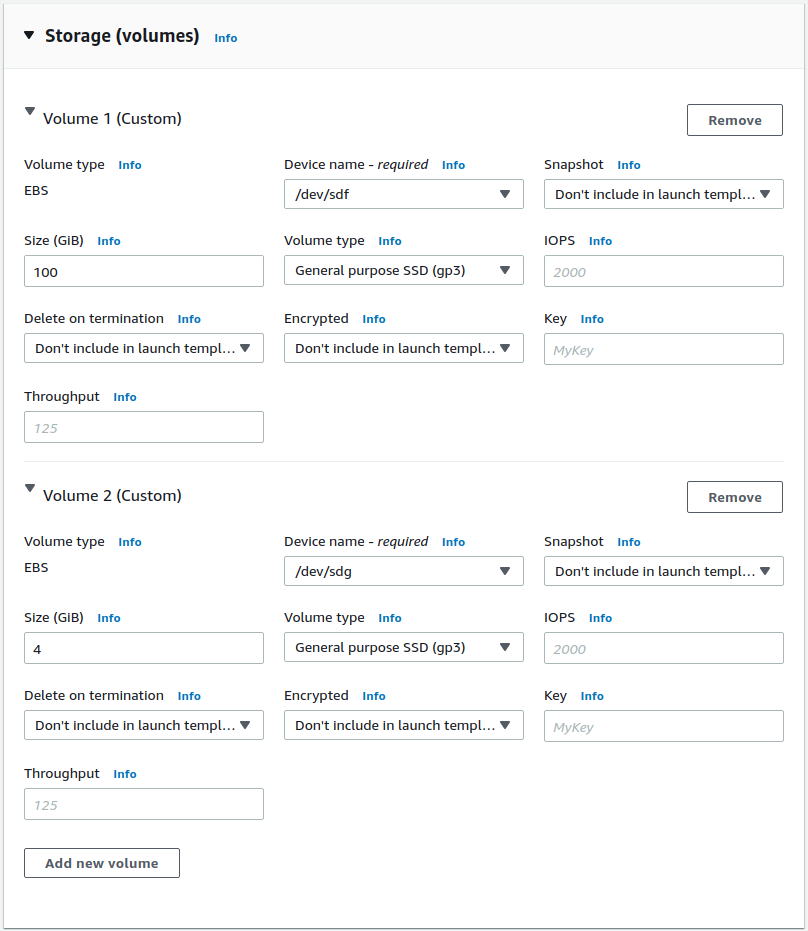
Volume type for both should be set to General purpose SSD (gp3) for both volumes. The larger volume will be used by LINSTOR when provisioning PVs from its storage classes. Set the size and type according to your requirements. The smaller volume will be used by LINSTOR as an external metadata storage-pool for the DRBD volumes that LINSTOR provisions. The smallest an EBS volume can be is 4GiB, which is enough space for up to 64TiB of LINSTOR provisioned DRBD volumes when replicating 3-ways.
Advanced Settings for Launch Template
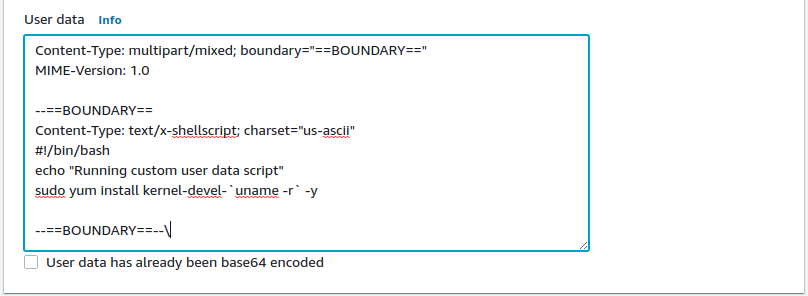
The only advanced settings that need modification is the user data pictured above. This additional user data will be appended to the user data responsible for bootstrapping an EKS worker. For copy and paste ability, here is the user data pictured above:
Content-Type: multipart/mixed; boundary="==BOUNDARY=="
MIME-Version: 1.0
--==BOUNDARY==
Content-Type: text/x-shellscript; charset="us-ascii"
#!/bin/bash
echo "Running custom user data script"
sudo yum install kernel-devel-`uname -r` -y
--==BOUNDARY==--\
Finally, click the “Create template version” button to save the launch template. You should see that your launch template was created successfully. Follow the link to view your launch template and note the “Launch Template ID” which should be formatted like this: lt-0123456789abcdefg. You will need to specify this launch template in the managed node group used by your EKS cluster.
If you use eksctl to create EKS clusters, you can specify your launch template right in your eksctl configuration:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: linbit-eks
region: us-west-2
managedNodeGroups:
- name: lb-mng-0
launchTemplate:
id: lt-0123456789abcdefg
version: "1"
desiredCapacity: 3
Creating the LINSTOR’s Operator in EKS
With EC2 prepped for LINSTOR, you should be able to follow the LINSTOR User’s Guide to deploy LINSTOR. For convenience, here are the LinstorSatelliteConfiguration options I use when deploying LINSTOR into an EKS cluster that uses the launch template described above:
apiVersion: piraeus.io/v1
kind: LinstorSatelliteConfiguration
metadata:
name: storage-pool
spec:
storagePools:
- name: lvm-thin
lvmThinPool:
volumeGroup: drbdpool
thinPool: thinpool
source:
hostDevices:
- /dev/nvme2n1
- name: ext-meta-pool
lvmThinPool:
volumeGroup: metapool
thinPool: thinpool
source:
hostDevices:
- /dev/nvme1n1
---
apiVersion: piraeus.io/v1
kind: LinstorSatelliteConfiguration
metadata:
name: compile-drbd-module-loader
spec:
patches:
- target:
kind: Pod
name: satellite
patch: |
apiVersion: v1
kind: Pod
metadata:
name: satellite
spec:
initContainers:
- name: drbd-module-loader
env:
- name: LB_HOW
value: compile
The additional EBS volumes attached to each EC2 instance that EKS spins up from our launch template will be attached as /dev/nvme1n1 and /dev/nvme2n1, which we’ve set in the LINSTOR operator’s LinstorSatelliteConfiguration definition named storage-pool above. This will cause LINSTOR to automatically prepare those EBS volumes for use as LINSTOR storage pools.
The LinstorSatelliteConfiguration definition named compile-drbd-module-loader tells the LINSTOR operator to compile the DRBD kernel module on our EKS worker nodes rather than installing from pre-packaged rpms. This ensures we have a DRBD kernel module that is an exact match for the EKS kernel.
For best performance, and to use the external metadata storage-pool, the following storageClass definitions should be configured in Kubernetes:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: "linstor-csi-lvm-thin-r1"
provisioner: linstor.csi.linbit.com
parameters:
allowRemoteVolumeAccess: "false"
autoPlace: "1"
storagePool: "lvm-thin"
DrbdOptions/Disk/disk-flushes: "no"
DrbdOptions/Disk/md-flushes: "no"
DrbdOptions/Net/max-buffers: "10000"
property.linstor.csi.linbit.com/StorPoolNameDrbdMeta: "ext-meta-pool"
reclaimPolicy: Retain
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: "linstor-csi-lvm-thin-r2"
provisioner: linstor.csi.linbit.com
parameters:
allowRemoteVolumeAccess: "false"
autoPlace: "2"
storagePool: "lvm-thin"
DrbdOptions/Disk/disk-flushes: "no"
DrbdOptions/Disk/md-flushes: "no"
DrbdOptions/Net/max-buffers: "10000"
property.linstor.csi.linbit.com/StorPoolNameDrbdMeta: "ext-meta-pool"
reclaimPolicy: Retain
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: "linstor-csi-lvm-thin-r3"
provisioner: linstor.csi.linbit.com
parameters:
allowRemoteVolumeAccess: "false"
autoPlace: "3"
storagePool: "lvm-thin"
DrbdOptions/Disk/disk-flushes: "no"
DrbdOptions/Disk/md-flushes: "no"
DrbdOptions/Net/max-buffers: "10000"
property.linstor.csi.linbit.com/StorPoolNameDrbdMeta: "ext-meta-pool"
reclaimPolicy: Retain
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
If you’ve made it this far and you’re interested in the use case that instigated this blog post, please read the reference architecture I wrote for HA Jenkins deployments in EKS. Or, of course, reach out directly!


