
LINBIT® has been a player in the world of highly available storage and data replication since 2001. At the heart of the LINBIT software ecosystem are DRBD® and LINSTOR®, two technologies that provide a foundation for building resilient, scalable, and integrated storage solutions. What makes LINBIT storage software truly powerful and unique is flexibility. I often say that LINBIT doesn’t build HA, DR, or SDS products (which might not be completely true), instead LINBIT builds HA, DR, and SDS tools and components. To further, “drive this analogy home”, I would say you don’t come to LINBIT to buy a BMW, you come to LINBIT to buy the tools and expertise needed to build a Ferrari, or a Volkswagen, or whatever kind of car you want to build – you’re in the driver’s seat. I’ll stop with the car stuff now…
The flexibility and freedom that this approach to development gives LINBIT software users is an upside, from the LINBIT team’s perspective. If your organization prefers to use NFS based storage for Kubernetes, LINBIT can build an HA NAS with open source software to accommodate that. If your organization values performance over everything in Kubernetes, LINBIT can instead directly integrate LINSTOR into your Kubernetes cluster for direct and low latency block access to replicated storage. There is always more than one way to use LINBIT software to provide storage to a platform, depending on your specific needs or constraints.
That flexibility does come with a somewhat unfortunate side effect of additional complexity for new and sometimes even experienced users trying to navigate the LINBIT software catalog when researching solutions for a project. In this blog, I’ll delve into the relationships that make up the LINBIT software ecosystem, how they integrate with major platforms, and how these relationships enable organizations to build storage solutions that are not only reliable but also adaptable to the ever-changing demands of modern IT.
Navigating LINBIT software stacks for any platform
To better explain relationships between LINBIT software, I created a “relationship diagram” with input from colleagues and help from designers. I used quotation marks around relationship diagram because it’s not an entity relationship diagram (ERD) as we learned in school or use in software development and database design, but is instead a simplified “map” of relationships that anyone can pick up to get a general understanding of how LINBIT software interacts with other LINBIT software and specific platforms.
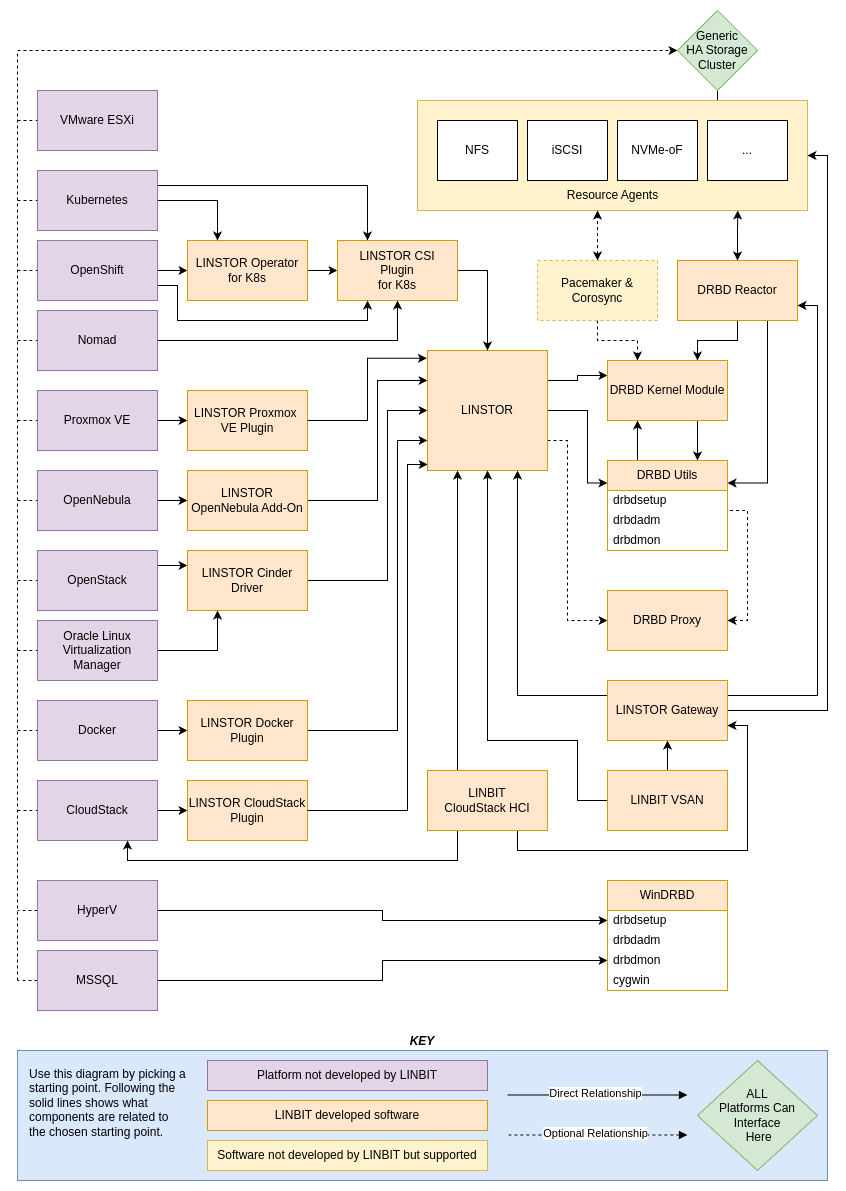
If I left you with the above image, you would probably still be at least a little lost. Hopefully the key at the bottom starts to explain my madness thinking. But to further help understanding, I’ll offer up some more guidelines to use while trying to navigate the nuance.
Generic storage clusters or platform specific integrations
Looking at the platforms in purple on the left of the diagram, you will see that there are at least “two paths forward” for almost all platforms. Each “path” from a platform leads you to a different LINBIT developed and supported software stack that can provide HA or DR capable storage for that platform. If you follow any single path “to the end” (where there’s no more “paths leading out”), you’ll see they all end with DRBD and the DRBD utilities. This is why LINBIT will often say things such as, “DRBD is at the core of all LINBIT solutions”.
One path from each platform is a dotted line, typically this is the less specific or the “alternate” path, that leads you to a “Generic HA storage cluster”. This, in terms of LINBTI software, is the path that involves building HA storage clusters that can interface with storage by using commonly supported protocols, such as NFS, iSCSI, or NVMe-oF. This path uses DRBD for data replication, DRBD Reactor or Pacemaker for cluster resource management, and a few dependencies depending on how you plan to expose the storage (NFS, iSCSI, NVMe-oF) which you can see by following that path to its end. This option is ideal for any environment that wants to keep storage completely separate from their compute platform, or for organizations that value the use of well known protocols and familiar software stacks in their environments.
The other path(s) from a given platform is a solid line that leads you to a platform-specific LINSTOR integration. This path involves a LINSTOR driver for the chosen platform, a LINSTOR cluster for provisioning and managing storage volumes, and DRBD for replicating those volumes. This is often the preferred path, as it offers the deepest integration, allowing your compute nodes to read and write to directly attached storage in hyperconverged infrastructures when low latency access to storage is required. Again, this path ends with DRBD, and since DRBD is a kernel module, when compute resources are running on the same host as their DRBD storage volumes the amount of abstraction and data in transit is kept to an absolute minimum, which means greater performance than might be possible with a “generic path”.
Understanding these two “main paths” and the LINBIT software involved in building a storage solution for them will help you grasp 85-90% of the possible software combinations you can use to build an HA or DR storage cluster by using LINBIT software.
Other types of software and their relationships
Then, there are the snowflakes in the diagram. No software solution exists without its asterisks, and the 10-15% of understanding I “left on the table” in the closing sentence of the previous section are the LINBIT software “asterisks“.
You’ll see that some LINBIT software is not in a direct path between a platform and other LINBIT software, such as LINSTOR Gateway. The same is true for either of the LINBIT “appliance” offerings: LINBIT VSAN, and LINBIT CloudStack HCI. These are software stacks that are either used to bundle the most complex relationships between LINBIT software, as with the LINBIT appliance offerings, or act as an API layer between other LINBIT software components, as with LINSTOR Gateway.
These “paths” are usually “replacement paths”, such that you could use the LINBIT CloudStack HCI appliance, for example, to create an Apache CloudStack cluster with LINSTOR integrated storage ready to go using a single ISO installation image, rather than setting up Apache CloudStack, then LINSTOR and DRBD, and then integrating it into CloudStack manually. Or, you could use the LINBIT VSAN appliance to create generic HA storage resources, rather than piecing together your own cluster using DRBD Reactor, LINSTOR, DRBD, and “hand configured” clustered resources. While this easier path to a solution might seem like a no-brainer, and is a counter to my introduction’s quote about LINBIT building software tools and components rather than products, these appliances might not always support the idea or architecture you have in mind. This is why it’s important to understand that there are multiple paths and what they entail.
Concluding thoughts
Sometimes finding what you’re looking for among the collection of LINBIT software documentation, source code repositories, blogs, and platform specific integration materials can seem daunting and scattered, and I think I’ve demonstrated that you’re not wrong to feel that way. Perhaps I’ve also demonstrated that it is that way for a good reason: To give LINBIT software users flexibility and control over their mission critical storage infrastructure. That is the intention of LINBIT developers when developing new and existing LINBIT software.
Hopefully sharing my LINBIT software relationship diagram coupled with the nuance above will help you navigate the growing LINBIT software catalog. If you have any feedback, or questions about anything I’ve written here or illustrated in the diagram, don’t hesitate to reach out directly, or in the LINBIT community forums.


