
Besides being able to ship storage snapshots internally to the same LINSTOR® cluster, or to a different “remote” LINSTOR cluster, LINSTOR administrators can also ship storage snapshots to S3 compatible storage. MinIO and Amazon S3 are examples of this that articles on this blog have explored before. Storj is an intriguing open source S3 compatible storage offering that you can easily add as a data backup destination in LINSTOR and is the topic of this article.
Background on using LINSTOR for disaster recovery
Authors on the LINBIT® blog have written on the topics of disaster recovery (DR) and LINSTOR snapshot shipping before. LINBIT Solutions Architect, Yusuf Yıldız, wrote about disaster recovery as a general topic in the article, “Disaster Recovery Is Not a Technology, It’s a Plan”. Yildiz also wrote about LINSTOR storage snapshot shipping in the article, “Controlling Data Replication with Snapshot Shipping Using LINSTOR”.
The basic concept is that you can use LINSTOR to take point-in-time snapshots and snapshot deltas of data within thin-provisioned LVM or ZFS storage volumes under LINSTOR management. You can then send these snapshots over networks, either manually or automatically on a schedule, to a LINSTOR remote. The LINSTOR remote can either be the same or another LINSTOR cluster, or else S3 compatible storage.
When you need to, you can use a snapshot to restore your data to an earlier state, captured by the snapshot. In day-to-day operations, if you have the choice, you likely want to restore data from a local snapshot. However, disaster recovery is not about the day-to-day, it is about preparing for the worst. Before you have a catastrophe, such as an entire data center going down, you need a plan for getting your critical applications and services, including the data they might rely on, up and running again. This is where having LINSTOR managed storage with backups in off-site storage, such as Storj S3 storage, can help.
Background on Storj S3 storage
Storj S3 object storage is notable for a few features which set it apart from more traditional object storage offerings.
Distributed storage
The first notable aspect about Storj that sets it apart from other S3 offerings is that data uploaded to a Storj S3 bucket will be stored across a globally distributed network of storage. This storage comes from individuals and companies who have rented their excess storage, along with network bandwidth to access that storage, to the Storj global network of distributed storage. Rarely do people and organizations use storage volumes to their maximum capacity, with the possible exception of my personal home directory which I am constantly culling to make room for new data. It is this “extra” storage capacity, that would otherwise just be sitting around doing nothing, that the Storj model uses to build its S3 storage offering.
Encryption
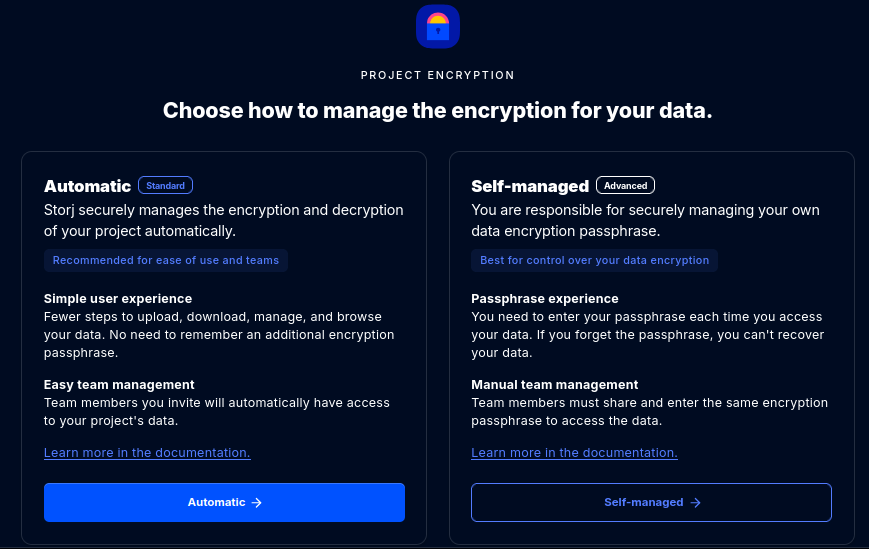
When you upload a file to Storj storage, it is first encrypted. At the outset of a new Storj project, you can choose whether you want to use Storj managed encryption or else self-managed encryption. Using Storj managed encryption is easier, and encrypts data by using a stored (and also encrypted) passphrase within the Storj network of hosted services. A self-managed encryption passphrase is not stored by Storj or its network of hosted services. If you opt to use self-managed encryption, you and you alone are responsible for remembering, storing, and sharing your passphrase across your team.
You can learn more about these two encryption models by referring to Storj documentation on the topic.
Privacy and security
If the thought of your data residing on data storage provided by strangers concerns you, the Storj storage model should provide some comfort. After first encrypting a file that you upload to Storj storage, Storj services use an erasure coding algorithm that breaks the file up into pieces, called erasure shares. By using an erasure coding algorithm, an erasure-coded file can be reconstituted by using only a subset of the total number of erasure shares. An attacker who has compromised a single node in the Storj network of “strangers” providing storage and bandwidth, for example, would not be able to reconstitute a file from a single erasure share.
The Storj storage model also implements barriers that prevent an attacker who has comprised a node in the Storj storage network from learning the location of erasure shares on other nodes that would allow the attacker to find more erasure shares and reconstitute a Storj stored file. You can learn more about these topics in Storj documentation, and in a Storj published technical paper.
Storj hierarchy of data storage
If you have used other S3 storage offerings, such as Amazon S3 or MinIO, for example, then the Storj hierarchy of data storage will be familiar. Storj object storage is arranged, from the top down, into three conceptual containers, quoted from Storj documentation as follows:
Projects – Projects allow you to invite team members, manage billing, and manage access for various apps or users.
Buckets – Buckets represent a collection of objects. You can upload, download, list, and delete objects of any size or shape.
Objects – Each object typically includes the data itself, a variable amount of metadata, and a globally unique identifier (object key) which uniquely identifies the object in a bucket. Objects within buckets are represented by keys […]. Objects are always end-to-end encrypted.
Benefits of using Storj as an S3 LINSTOR remote
Using Storj storage as an S3 remote destination for LINSTOR storage volume backups has technical benefits. I have mentioned some of these such as encryption, privacy, security, and the open source nature of the project.
Durability
Storj storage also has the technical benefit of durability. Because of the erasure coding algorithm that Storj storage uses, more erasure shares are created of a file, for example, and stored on different Storj nodes, than are needed to reconstitute the file. This means that many nodes having erasure shares for the file might fail, and you can still reconstitute the file.
Storj targets an “11 nines” measurement of data durability to inform the logic that determines how many erasure shares are created, and the minimum number of erasure shares that are needed to reconstitute data. Borrowing an observation from Storj documentation, “The National Weather Service estimates the likelihood of you not getting hit by lightning [based on averages for 2009-2018] at only six 9s […].” Storj documentation has more details about file redundancy, durability, and the mathematics behind these topics.
Carbon offset
Besides the technical benefits, the Storj storage model might also bring some environmental benefits, including reducing carbon emissions, when compared to using traditional data center storage models. The premise of this claim is based on some assumptions such as the life cycle costs of manufacturing new storage drives, the amount of electrical power data centers consume, the environmental impact of building new data centers, and other factors that contribute to carbon emissions. By using existing, underutilized storage media (storage drives not running at full capacity), in existing data centers and elsewhere, fewer storage drives need to be manufactured, fewer data centers built, and less power consumed.
Accepting all of this leads to the conclusion that using Storj storage, rather than traditional cloud-based storage, is better for the environment, as far as carbon emissions go. A Storj technical paper, “How Using Spare Capacity for Data Storage is Better for the Environment”, provides more depth, analysis, and backing for these claims and is an interesting read.
Getting started with using Storj and LINSTOR
With that background covered, getting started using Storj S3 storage as a backup shipping target in LINSTOR is straightforward. Two guides cover the steps you need to take.
If you are already familiar with Storj but less familiar with LINSTOR, you might refer to the guide within Storj documentation. If you familiar with LINSTOR but less familiar with Storj, you might refer to the guide within the LINBIT knowledge base.
Setting up a Storj backup shipping remote target in LINSTOR by using the GUI
The two guides mentioned in the earlier section use a combination of steps within the Storj GUI and the LINSTOR CLI, to set up Storj storage as a remote target for backup shipping in LINSTOR. If you prefer an entirely GUI-based approach, you can use the LINSTOR GUI to create a Storj S3 remote and ship LINSTOR storage resource backups to it.
Prerequisites
To configure LINSTOR to use Storj storage as a LINSTOR S3 remote, you need to meet the following prerequisites:
- Have a Storj account, and a storage bucket with configured access to the bucket through S3 credentials
- Have a local LINSTOR cluster with a LINSTOR resource backed by thin-provisioned LVM or ZFS storage
Creating an encryption passphrase
First, create a LINSTOR encryption passphrase if you have not done so already.
Open the Settings page in the GUI (open <LINSTOR-controller-IP-address-or-resolvable-hostname>:3370/ui/#/settings in a web browser), click the Passphrase tab, enter a passphrase in the two fields, then click the Submit button.
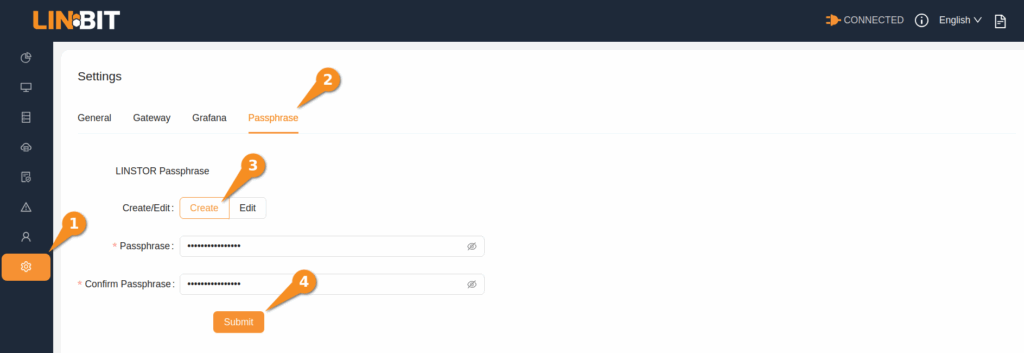
❗ IMPORTANT: If the LINSTOR controller service restarts, for example, after a node reboot or after upgrading the controller software, you will need to reenter your encryption passphrase. You can do this by clicking the “Unlock LINSTOR” padlock icon from the Backups page, from the Remote menu item.
Creating an S3 remote in LINSTOR for Storj storage
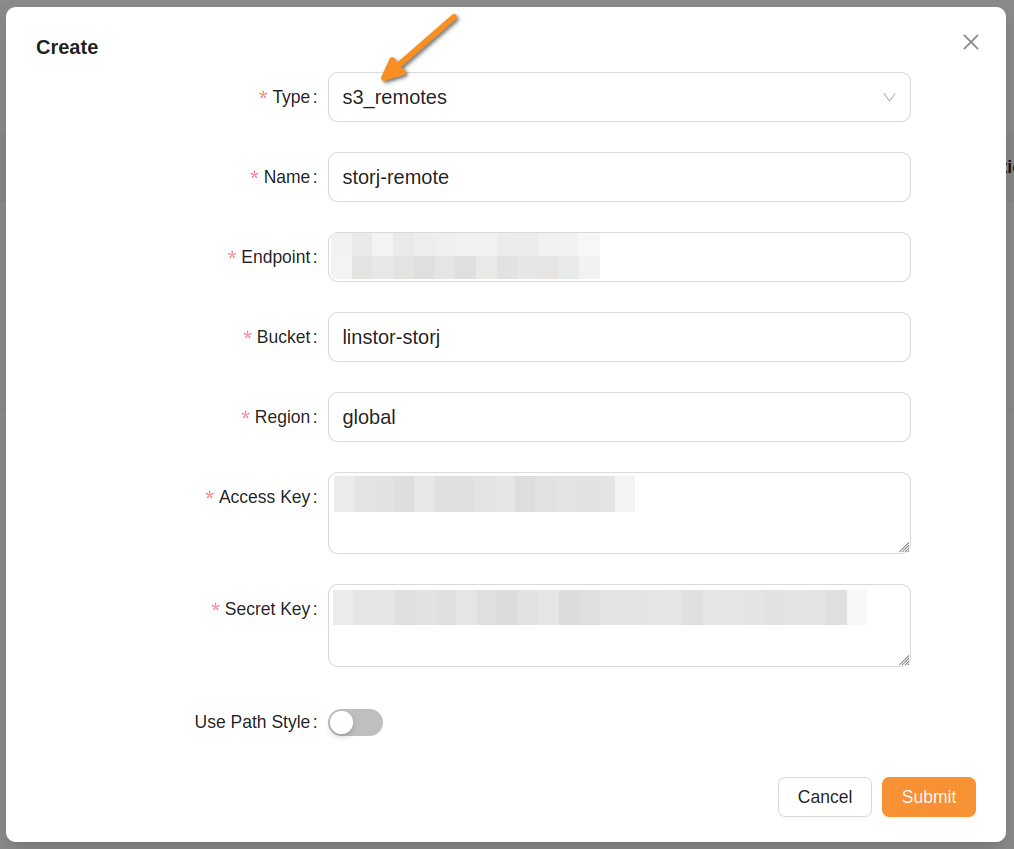
Open the Remote List page in the GUI (<LINSTOR-controller-IP-address-or-resolvable-hostname>/ui/#/remote/list), then click the Create button.
Select s3_remotes for the type, and enter appropriate information in the fields.
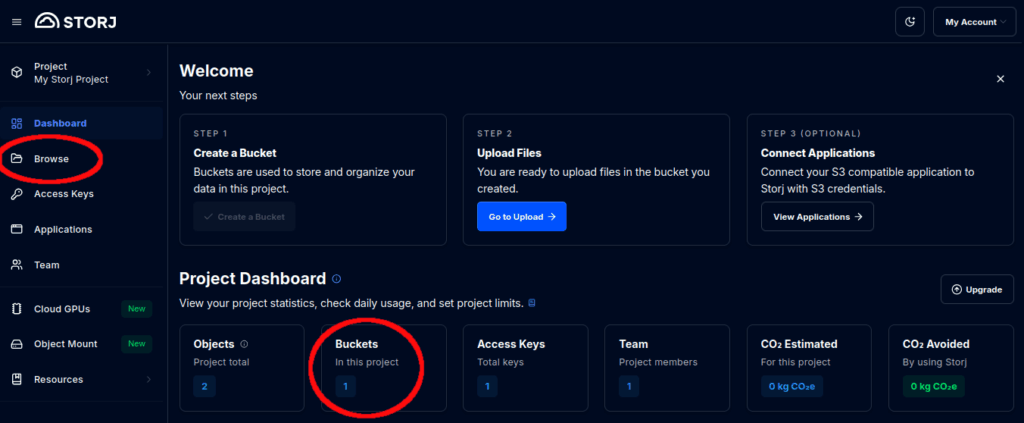
You can find your storage bucket name and region from the Browse Buckets page within your Storj project page.
After filling in the fields in the LINSTOR GUI create a remote dialog box, click the Submit button. The Remote List page will then show the remote that you just created.
Creating a LINSTOR storage resource backup
To create a LINSTOR storage resource backup, from the Remote List page in the GUI, click the Backups button, below the Action column entry for the Storj S3 remote that you created.
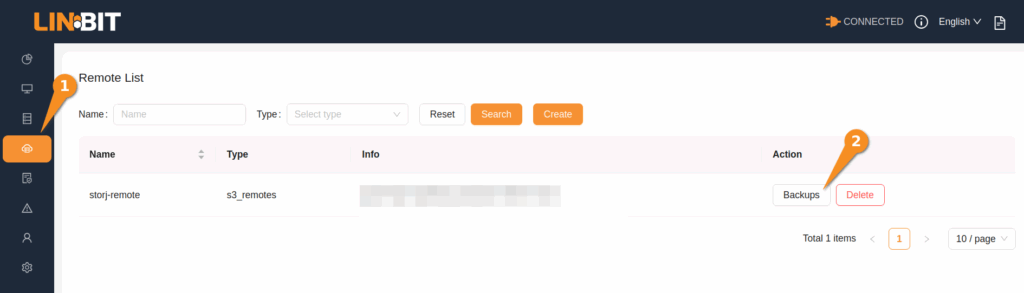
This will bring you to the Backups page for the Storj S3 remote.
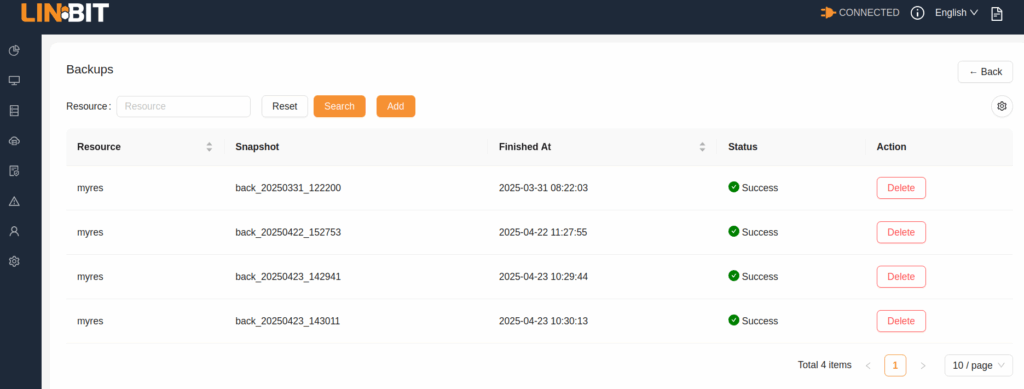
Click the Add button, select the resource you want to create a backup for and toggle the Incremental switch, depending on whether you want to ship a full backup of the resource or only an incremental (delta) backup. Click the Confirm button to start creating the resource snapshot and shipping it to your Storj bucket.
The Backups list page will show the backup you just created. After LINSTOR creates the local snapshot and ships it to your Storj bucket, the status will show Success.
Other features and use cases
While this article has focused on using Storj S3 storage as a backup shipping target for LINSTOR, for disaster recovery, Storj storage might have other benefits and uses for you. You can explore some of the other use cases for Storj storage within Storj documentation.
If the “multimedia storage” use case intrigues you, Storj has a feature offering called “Object Mount”. The Storj Object Mount feature uses cunoFS. By using this feature, you can work with files you have stored in the Storj storage network, or other S3 compatible storage, directly, as if they were on your local system. The Storj Object Mount feature involves no copying, downloading, or buffering. You can seamlessly work with large media files such as video files and collaborate with other teams globally. A video, “Using Object Mount for Media”, on the Storj website is a good introduction to this feature and uses a video editing scenario to show a possible use case.
Conclusion
Using the correct tool for the job is often a reliable guideline in life. It can also be a helpful guideline when choosing a back-end storage type for your data. Block storage, the type of storage LINBIT software such as DRBD® and LINSTOR work with, is well-suited for databases, messaging queues, and other such applications that have demanding storage I/O patterns, particularly random reads and writes. Object storage is best-suited for storing large unstructured data, such as audio and video data, and other such data that typically require sequential read/write I/O patterns. Object storage can also be great for data that is infrequently accessed, such as data backups and archives.
If you are already using LINSTOR to manage DRBD replicated storage volumes, living the glorious life of high performance block storage management and replication, you do not have to turn up your nose at other storage types. Using a Storj S3 object storage bucket as a remote destination for your LINSTOR storage volume backups is a great example of this.
Next steps
To learn more about LINSTOR volume snapshot and backup topics, refer to these sections in the LINSTOR User Guide:
If you are new to Storj, the Storj getting started guide is the perfect place to begin and is a fine jumping off point to other places of interest within Storj documentation.
Follow either of the guides linked earlier in this article’s “Getting started with using Storj and LINSTOR” section, or the steps for using the LINSTOR GUI to add a Storj S3 remote, to combine LINSTOR and Storj as part of a disaster recovery plan.


