About nine years ago, LINBIT® introduced the dynamic sync-rate controller in DRBD® 8.3.9. The goal behind this was to tune the amount of resync traffic so as to not interfere or compete with application IO to the DRBD device. We did this by examining the current state of the resync, application IO, and network, ten times a second and then deciding on how many resync requests to generate.We knew from experimentation that we could achieve higher resync throughput if we were to poll the situation during a resync more than ten times a second.
However, we didn’t want to shorten this interval by default as this would uselessly consume CPU cycles for the DRBD installations on slower hardware. With DRBD 9.0.17, we now have some additional logic. The resync-rate controller will poll the situation both at 100ms AND when all resync requests are complete, even before the 100ms timer expires.We estimate that these improvements will only be beneficial to storage and networks that are capable of going faster than 800MiB/s. For our benchmarks, I used two identical systems running CentOS 7.6.1810. Both are equipped with 3x Samsung 960 Pro M.2 NVMe drives. The drives are configured up in RAID0 via the Linux software RAID. My initial baseline test found that in this configuration, the disk can achieve a throughput around 3.1GiB/s (4k sequential writes). For the replication network, we have dual port 40Gb/s Mellanox ConnectX-5 devices. They’re configured as a bonded interface using mode 2 (Balance XOR). This crossover network was benchmarked at 37.7Gb/s (4.3GiB/s) using iperf3. These are actually the same systems used in my NVMe-oF vs. iSER test here.
Then, I ran through multiple resyncs as I found out how best to tune the DRBD configuration for this environment. It was no surprise that DRBD 9.0.17 looked to be the clear winner. However, this was fully-tuned. I wanted to find out what would happen if we scaled back the tuning slightly. I then decided to test while also using the default values for sndbuf-size and rcvbuf-size. The results were fairly similar, but surprisingly 9.0.16 did a little better. For my “fully tuned” test, my configuration was the default except for the following tuning:
net {
max-buffers 80k;
sndbuf-size 10M;
rcvbuf-size 10M;
}
disk {
resync-rate 3123M; # bytes/second, default
c-plan-ahead 20; # 1/10 seconds, default
c-delay-target 10; # 1/10 seconds, default
c-fill-target 1M; # bytes, default
c-max-rate 3123M; # bytes/second, default
c-min-rate 250k; # bytes/second, default
}Three tests were ran. All tests were done with a 500GiB LVM volume using the /dev/md0 device as the physical volume. A blkdiscard was run against the LVM between each test. The first test was with no application IO to the /dev/drbd0 device and without the sndbuf-size and rcvbuf-size. The second was with no application IO, and fully-tuned as per the configuration above. The third test was again fully-tuned with the configuration above. However, immediately after the resource was promoted to primary, I began a loop that used ‘dd’ to write 1M chunks of zeros to the disk sequentially.
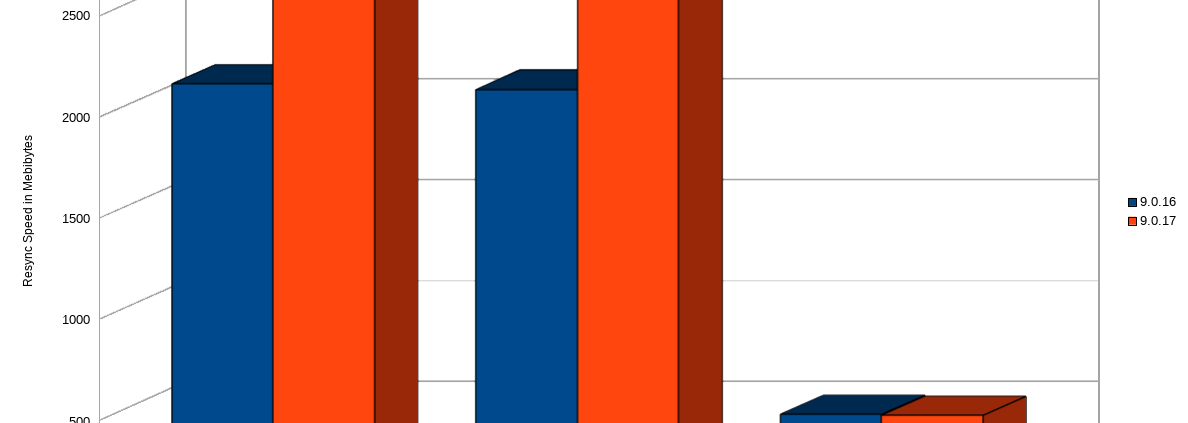
When idle – DRBD 9.0.17 can resync at the speeds the physical disk will allow, where as 9.0.16 seems to top out around 2000MiB/s. DRBD 8.4.11 can’t seem to push past 1500MiB/s. However, when we introduce IO to the DRBD virtual disk, both DRBD 9 versions scale back the resync speeds to roughly the same speeds. Surprisingly, DRBD 8.4 doesn’t throttle down as much and hovers around 700MiB/s. This is most likely due to an increase in IO lockout granularity between versions 8 and 9. However, faster here is not necessarily desired. It is usually favorable to have the resync speeds throttled down in order to “step aside” and allow application IO to take priority.Have questions? Contact us and we’re happy to help!


