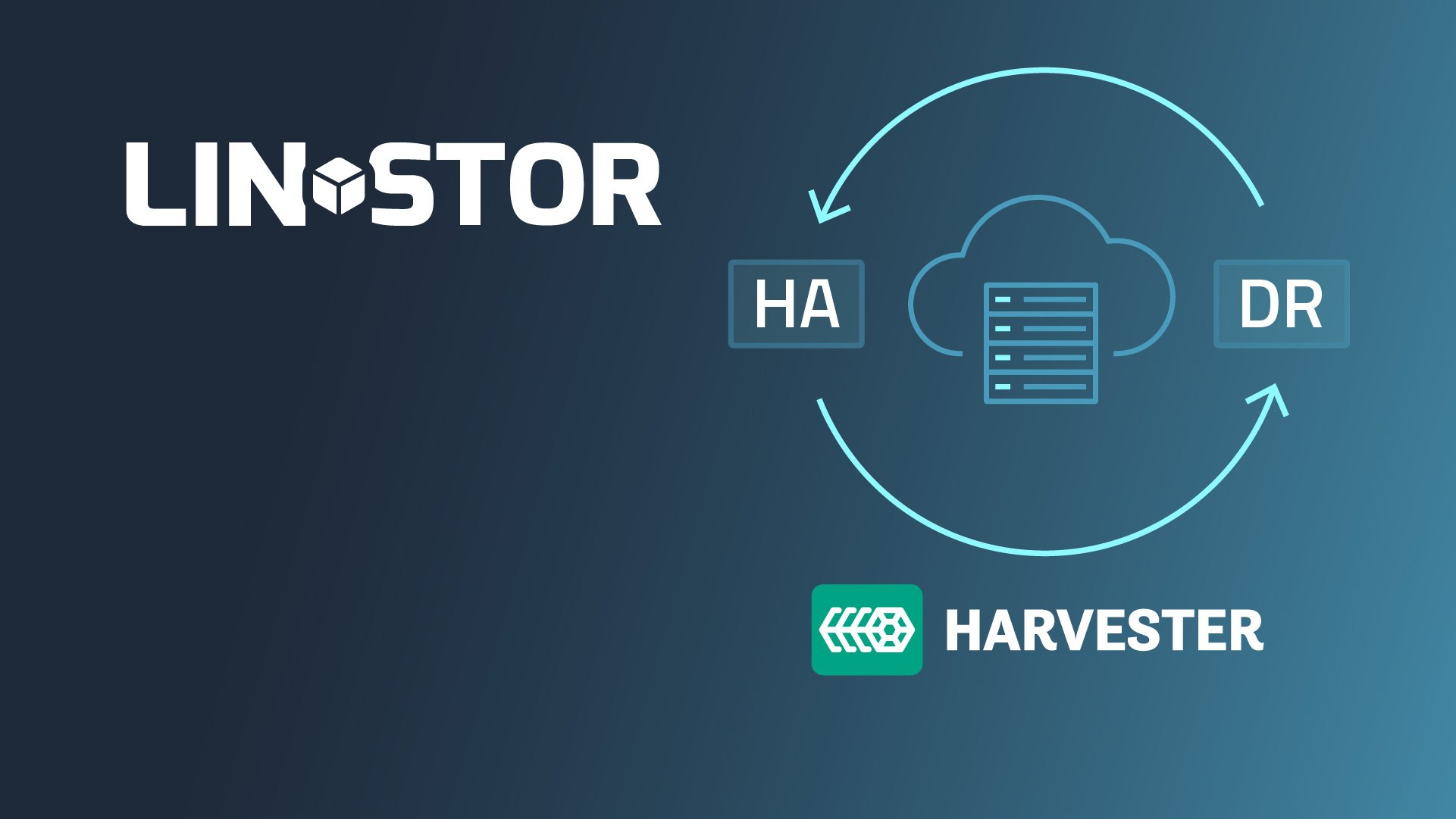
SUSE Harvester is an open source hyperconverged infrastructure (HCI) virtualization management platform, built on top of Rancher, the SUSE-developed management platform for Kubernetes. Harvester deployments typically use Longhorn for persistent storage, but because you can also use Container Storage Interface (CSI) compliant storage systems, LINSTOR® is an option. This article will provide an overview of the LINSTOR integration with SUSE Harvester and its benefits.
LINSTOR uses a CSI driver to integrate with other Kubernetes-based platforms besides Harvester, such as OpenShift, minikube, and others. Because this makes LINSTOR deployments in different Kubernetes-based environments similar, diligent readers of the LINBIT® blog might have encountered content in this article in other LINBIT blog articles or guides. If just knowing that you can use LINSTOR with Harvester is enough for you to want to get started, you can download a LINBIT how-to guide on getting started with LINSTOR in SUSE Harvester and be on your way. Otherwise, read on to learn more about the integration.
Choosing a storage back end for virtualized workloads
If you have containerized or virtualized applications that demand I/O performance, such as databases or messaging queues, you do not want the persistent storage they might require to become a bottleneck in your deployment. Here there can be storage hardware and architecture choices that you can make to limit bottlenecks and maximize performance. But when it comes to flexibility, resiliency, and scalability, considering software-defined storage (SDS) will likely be a factor in your deployment planning. Here too, you do not want your SDS choice to slow your applications down.
This is where LINSTOR can enter the picture.
Background on LINSTOR
LINSTOR is an open source SDS configuration management system, designed for Linux systems. By using LINSTOR and its CSI driver, you can define your storage resources abstractly and then create, manage, monitor, and consume those resources through actions in Harvester. Abstracting storage gives you the flexibility to change or scale your physical storage back ends to adapt to business changes, customer demands, or environmental factors, without having to disrupt or change the applications that consume the storage, or how your users interface with different storage back ends.
Replicating persistent storage for high availability
Although it is not a strict requirement, LINSTOR is often used to manage DRBD® replicated storage and makes deploying such storage easier. In particular, LINSTOR uses DRBD 9 for replicating storage resources across deployments. DRBD is the long-standing open source data replication technology that provides exceptional performance, as LINBIT testing has shown, as confirmed by independent testing here and here, and as businesses and organizations that use DRBD worldwide have attested. Using DRBD 9 opens up such LINSTOR features as self-healing by configuring automatic replica placement counts, and the DRBD quorum feature to prevent data divergence (so-called split-brains).
Getting started with LINSTOR in SUSE Harvester
LINSTOR is adaptable to different kinds of deployments: bare metal, cloud, or hybrid installations, and it integrates with many platforms. One popular LINSTOR integration is with Kubernetes and Kubernetes-based environments.
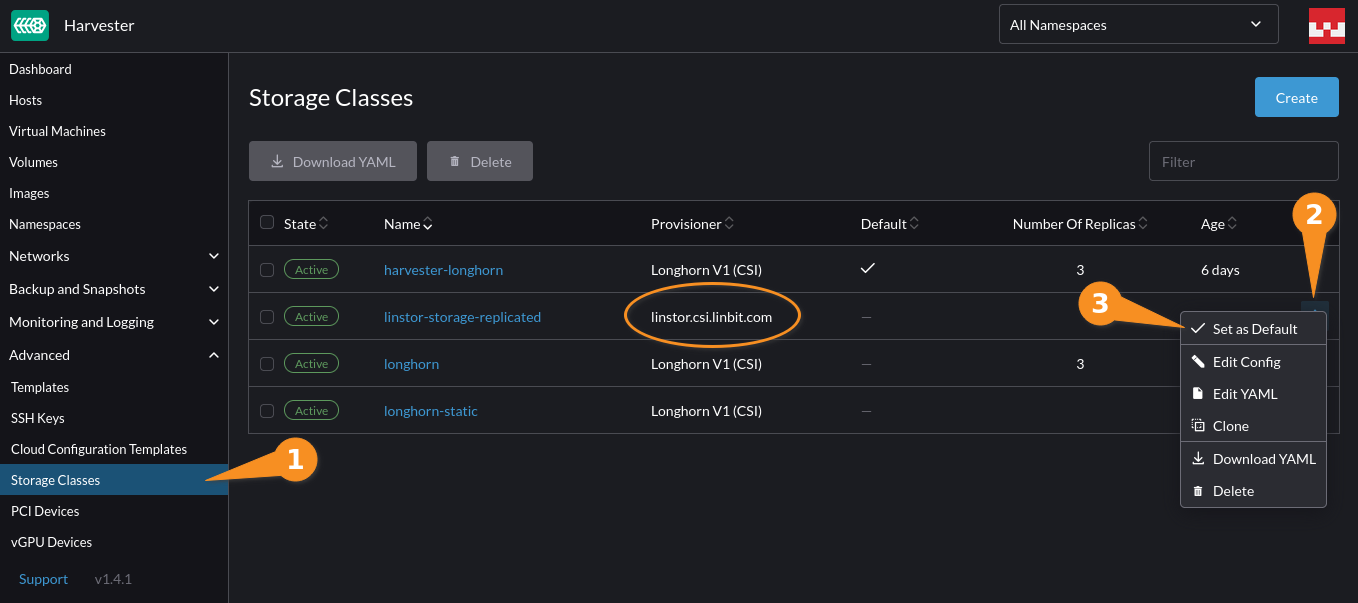
A LINSTOR Operator makes it easy to deploy LINSTOR in Harvester and provides benefits such as high availability (HA) and disaster recovery (DR) capabilities for your Persistent Volume Claims (PVCs). To get you started quickly, you can follow the instructions in the Getting Started With LINSTOR in SUSE Harvester. This how-to guide will take you through the steps to install LINSTOR in Harvester, and provides some initial guidance for using LINSTOR within Harvester.
By following this guide, you can use LINSTOR within a Harvester cluster to offer and manage persistent storage for your virtual machine (VM) disk images. A benefit of this integration will be the ability to dynamically provision highly available, persistent storage volumes that back your VMs in Harvester.
The guide also has instructions for deploying an example VM within Harvester that will use a PVC, backed by LINSTOR managed storage. By using LINSTOR, the persistent storage used for VM disk images will be highly available across the nodes in your cluster, by virtue of DRBD’s high performance block-level replication. This makes it possible to fail over VMs to other nodes, for example, when performing system maintenance. There is even support for live migrating VMs, similar to how it is done in KubeVirt.
Diving deeper into LINSTOR, you can also explore other benefits such as snapshot shipping for thin LVM or ZFS volumes, to other LINSTOR clusters or to S3 compatible object storage, such as MinIO, or Storj, or other backup solutions that might integrate with the LINSTOR CSI driver. LINSTOR snapshot shipping, on its own or with a potential integration, is a feature which can be a part of your disaster recovery planning.
Using an operator to easily deploy LINSTOR in Harvester
Instructions in the Getting Started With LINSTOR in SUSE Harvester how-to guide use the LINSTOR Operator v2 to make deploying LINSTOR in Harvester even easier. By using LINBIT customer or evaluation account credentials, you can access the LINBIT container images registry. After deploying the LINSTOR Operator, you are then just a single kustomization file and kubectl command away from deploying LINSTOR in Harvester.
If you are not a LINBIT customer but want to evaluate LINSTOR in Harvester, contact the LINBIT team to request an evaluation.


