
Distributed Replicated Storage System
The DRBD®– software is a distributed replicated storage system for the Linux platform. It is implemented as a kernel driver, several userspace management applications, and some shell scripts.
DRBD is traditionally used in high availability (HA) computer clusters, but beginning with DRBD version 9, it can also be used to create larger software defined storage pools with a focus on cloud integration.
DRBD Linux Kernel Driver
DRBD® kernel driver
The DRBD kernel driver presents virtual block devices to the system. It is an important building block of the DRBD. It reads and writes data to optional local backing devices.
Peer Nodes
The DRBD kernel driver mirrors data writes to one (or multiple) peer(s). In synchronous mode it will signal completion of a write request after it receives completion events from the local backing storage device and from the peer(s).
Data Plane
The illustration above shows the path the data takes within the DRBD kernel driver. Please note that the data path is very efficient. No user space components involved. Read requests can be carried out locally, not causing network traffic.
DRBD Utilities
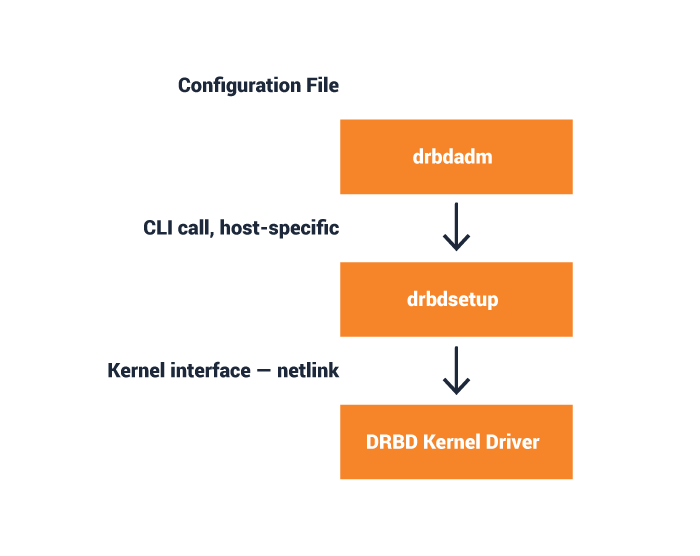
drbdsetup
drbdsetup is the low level tool that interacts with the DRBD kernel driver. It manages the DRBD objects (resources, connections, devices, paths). It can modify all properties, and can dump the kernel driver’s active configuration. It displays status and status updates.
drbdmeta
drbdmeta is used to prepare meta-data on block devices before they can be used for DRBD. You can use it to dump and inspect this meta-data as well. It is comparable to mkfs or pvcreate.
drbdadm
drbdadm processes configuration declarative configuration files. Those files are identical on all nodes of an installation. drbdadm extracts the necessary information for the host it is invoked on.
Built With Developers In Mind
DRBD® has a command line interface (CLI) and can also be used independently of a cloud, virtualization, or container platform to manage large DRBD clusters.
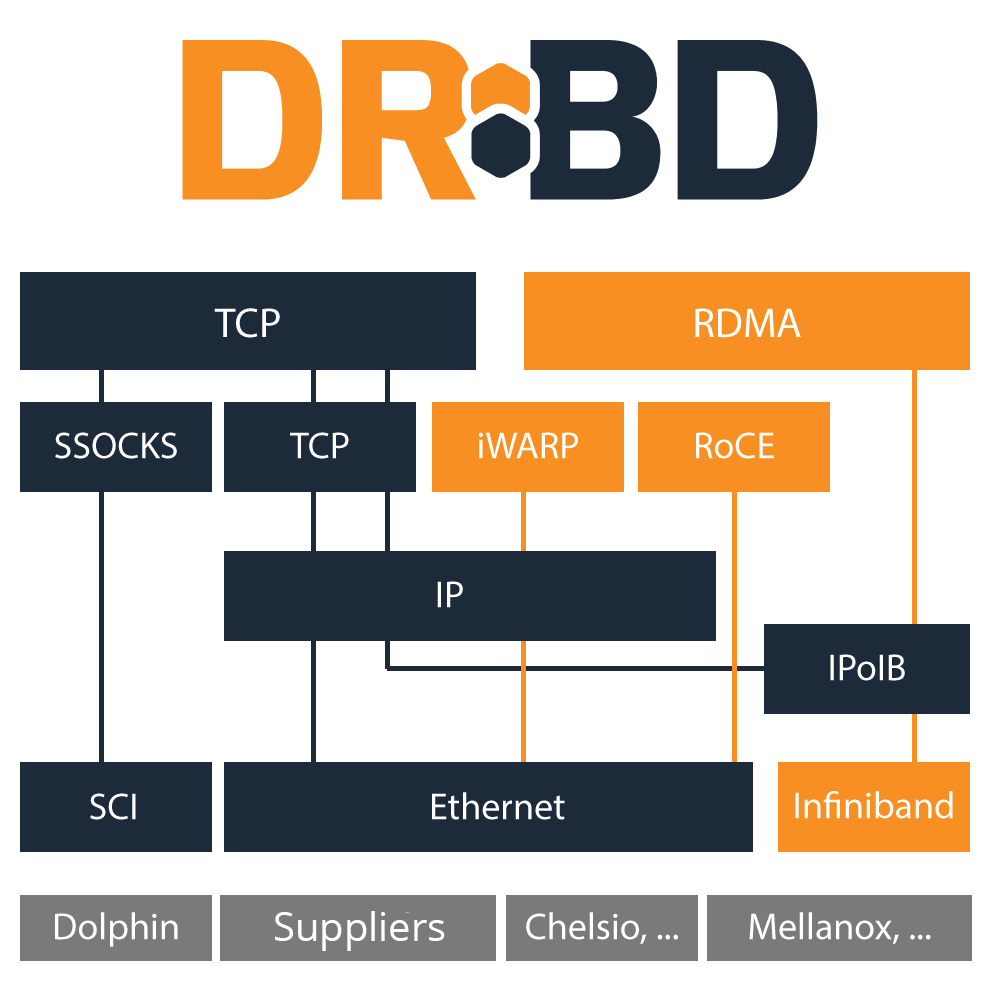
Networking Options
Network transport abstraction
DRBD® has an abstraction for network transport implementations.
TCP/IP
TCP/IP is the natural choice. It is the protocol of the Internet. Usually it is used on top of ethernet hardware (NICs and switches) in the data center. While it is the lingua franca of the network it has started to become outdated and is not the best choice to achieve the highest possible performance.
RDMA/Verbs
Compared to TCP/IP a young alternative is RDMA. It requires NICs that are RDMA capable. It can run over InfiniBand networks, which come with their own cables and switches. It can run over enhanced ethernet (DCB) or on top of TCP/IP via an iWARP NIC. It is all about enhancing performance while reducing load on the CPUs of your machines.
DRBD Windows Driver and Utilities
LINBIT released its DRBD®-Windows driver to make the many advantages of DRBD available for Windows named WinDRBD®.
We will release new versions of WinDRBD on a regular basis. Ready-to-use precompiled and signed packages can be downloaded from our Download page. Please use the contact form below to provide feedback, we look forward to hear from you.
You get the documentation for WinDRBD in our content hub at docs.linbit.com. To learn more about WinDRBD as a software click the link below:
DRBD RDMA Transport
InfiniBand, iWARP, RoCE
In the HPC world InfiniBand became the most prominent interconnect solution about 2014. It is proven technology, and with iWARP and RoCE it bridges into the Ethernet world as well.
Properties
It brings the right properties for a storage networking solution. It offers bandwidth ahead of the curve, it has lower latency. It comes with an advanced API: RDMA/verbs.
DRBD
The DRBD RDMA Transport allows you to take advantages of the RDMA technology for mirroring data in your DRBD setup. With it DRBD® supports multiple paths for bandwidth aggregation and link failover.
Disaster Recovery
WAN Links
Long distance links often expose varying bandwidth, due to the side effects of other traffic sharing parts of the path. They often have higher latency than LANs.
Varying Demand
It might be peaks in write load on DRBD, it might be temporal setback in the available link bandwidth, it may happen that the link bandwidth becomes lower than the necessary bandwidth to mirror the data stream.
Buffering and Compression
Disaster Recovery‘s main task is to mitigate these issues, otherwise DRBD would slow down the writing application by delivering IO completion events later. Disaster Recovery does that by buffering the data.

Forum

GitHub

Documentation

